Clear Sky Science · sv
Hybrid uppmärksamhetsoptimerad hierarkisk flerskalig transformerarkitektur för bildsuperupplösning
Skarpare bilder från suddiga början
Från satellitfotografier av städer till MR-skanningar och mobilfoton börjar många bilder suddigare än vi önskar. Bildsuperupplösning är en grupp tekniker som försöker återskapa en skarp, detaljerad bild från en lågupplöst version. Denna artikel introducerar ett nytt sätt att göra det på, genom att använda en smart blandning av moderna AI-verktyg för att återfå fina texturer och kanter som äldre metoder tenderar att sudda ut eller förlora.
Varför det är så svårt att göra bilder skarpare
Att förvandla en oskarp bild till en skarp låter enkelt, men det är ett klassiskt ”inversproblem”: många olika högupplösta scener kan ge upphov till samma suddiga bild. Utmaningen är att gissa den version som ligger närmast verkligheten. Enkla knep som interpolering kan förstora bilder snabbt men skapar ofta släta, konstgjorda resultat. Traditionella matematiska modeller kan vara bättre, men de är långsamma och har svårare ju högre förstoring man försöker göra. Även kraftfulla djuplärandesystem, vare sig de bygger på konvolutionella neurala nätverk eller nyare Transformer-modeller, tenderar fortfarande att missa små linjer, texturer och upprepade mönster, särskilt i komplexa scener som tät stadsbebyggelse eller serieteckningar.
En ny trestegs pipeline för superupplösning
För att tackla dessa brister föreslår författarna en Hierarchical Multiscale Transformer (HMT)-arkitektur. Den bearbetar en bild i tre huvudsteg. Först fångar en grundläggande funktionsextraktör ytliga mönster såsom kanter och enkla texturer, medan ett standarduppskalningssteg bevarar den ursprungliga strukturen som en vägledning. 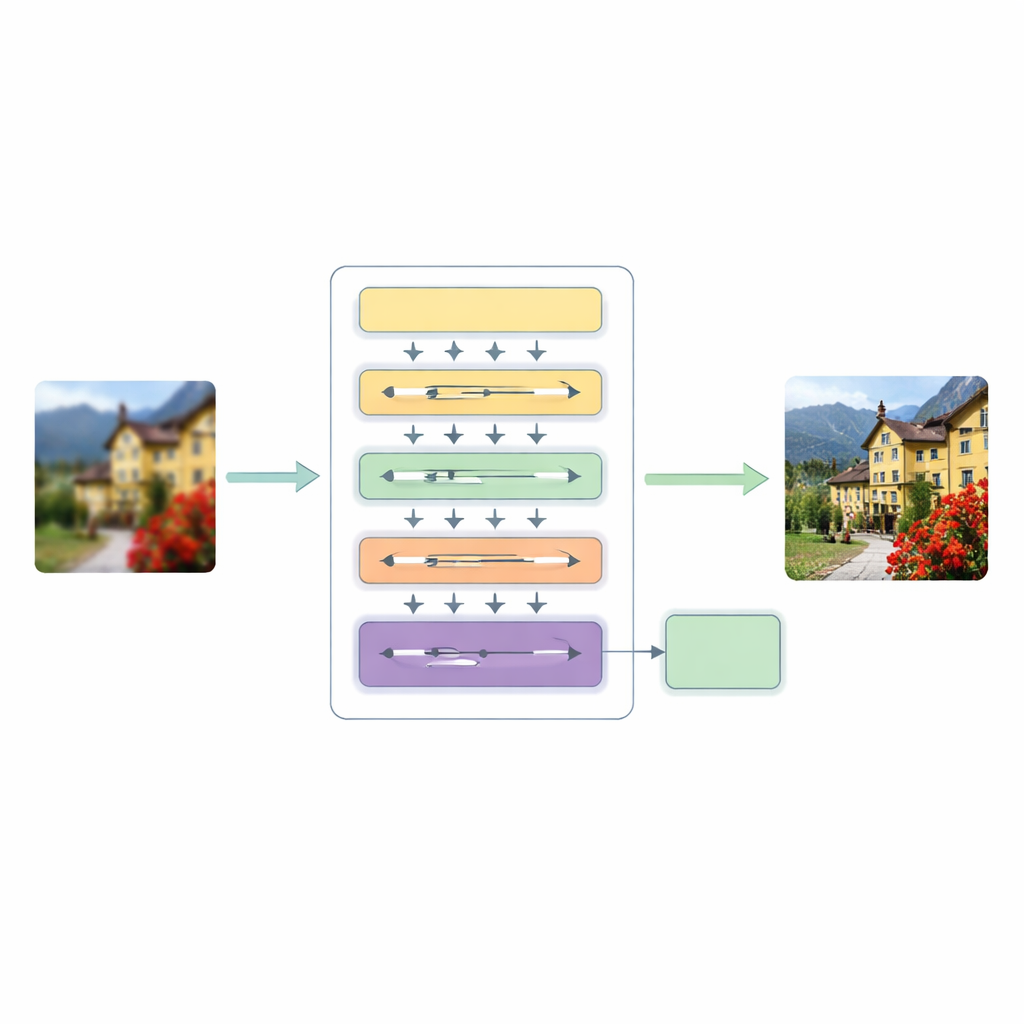
Att blanda globala mönster med lokala detaljer
Hjärtat i systemet är en hybrid uppmärksamhetsmekanism som betraktar bilden på två kompletterande sätt. Den ena grenen arbetar i frekvensdomänen och använder en Fouriertransform för att analysera bilden i termer av globala mönster såsom breda färgregioner och upprepade strukturer. Den andra grenen utvidgar en nyligen föreslagen idé om ”state space”-modellering så att den kan svepa över bilden i flera riktningar och plocka upp långdistansrelationer utan den höga kostnaden för traditionell self-attention. Genom att förena dessa två perspektiv kan nätverket förstå både den övergripande utformningen av en scen och de subtila relationerna mellan avlägsna men relaterade pixlar, samtidigt som beräkningen hålls rimlig.
Anpassning till varje bild i realtid
Parallellt introducerar modellen Dynamisk Konvolutionell Uppmärksamhet, som fokuserar sina resurser där bilden behöver det mest. Den delar upp funktionskanaler i små grupper och applicerar lätta, bildberoende filter som förenar de bästa aspekterna av uppmärksamhet: de reagerar olika på varje indata och kan koppla ihop avlägsna regioner. Eftersom vissa filter delas mellan lager medan andra anpassas per bild får systemet flexibilitet utan kraftig kostnadsökning. En dynamisk fusionsmodul ersätter sedan de stelbenta genvägskopplingarna som vanligtvis finns i encoder–decoder-nätverk, vilket låter modellen avgöra hur starkt den ska blanda information från olika skalor och djup. 
Hur väl fungerar det i praktiken?
Forskarna testade sin metod på välanvända bildsamlingar, inklusive naturliga fotografier, stadsbilder rika på raka linjer och upprepade fönster, samt högkontrast manga-sidor fulla av fina bläckstreck. Över flera standardbenchmarks och förstoringar matchade eller överträffade deras tillvägagångssätt konsekvent ledande superupplösningssystem, och uppnådde något högre poäng på mått för skärpa och strukturell likhet. Visuella jämförelser visar att den nya modellen bättre bevarar små texturer, minskar suddning kring kanter och hanterar komplexa upprepade mönster mer troget, samtidigt som antalet parametrar och beräkningar hålls inom rimliga gränser.
Klarare bilder för många verkliga användningsområden
I vardagliga termer erbjuder detta arbete ett mer pålitligt sätt att ”fylla i” saknade detaljer när man zoomar i en bild. Genom att omsorgsfullt kombinera global mönsteranalys, riktad kontext och adaptiv filtrering producerar den föreslagna arkitekturen skarpare, mer koherenta resultat än många befintliga verktyg. Det kan gynna tillämpningar från stadsplanering och katastrofövervakning till medicinsk bildbehandling och konsumentfotografi, där klarare bilder behövs men endast lågupplösta data finns tillgängliga.
Citering: Wang, B., Gao, R., Zhou, T. et al. Hybrid attention optimized hierarchical multiscale transformer architecture for image super-resolution. Sci Rep 16, 13655 (2026). https://doi.org/10.1038/s41598-026-44337-3
Nyckelord: bildsuperupplösning, djuplärning, transformernätverk, uppmärksamhetsmekanismer, datorseende