Clear Sky Science · pl
Hybrydowa zoptymalizowana hierarchiczna wieloskalowa architektura transformera do superrozdzielczości obrazów
Bardziej ostre obrazy z rozmytych początków
Od zdjęć satelitarnych miast po skany MRI i fotografie ze smartfonów — wiele obrazów zaczyna jako bardziej rozmyte, niż byśmy chcieli. Superrozdzielczość obrazu to zestaw technik mających na celu odbudowę ostrego, szczegółowego obrazu z wersji o niskiej rozdzielczości. W artykule wprowadzono nową metodę, wykorzystującą sprytne połączenie nowoczesnych narzędzi AI, aby odzyskać drobne tekstury i krawędzie, które starsze metody mają tendencję do rozmazywania lub tracenia.
Dlaczego wyostrzanie obrazów jest takie trudne
Przekształcenie rozmytego obrazu w ostry brzmi prosto, ale jest klasycznym „problemem odwrotnym”: wiele różnych scen o wysokiej rozdzielczości może dać ten sam rozmyty obraz. Wyzwanie polega na odgadnięciu wersji, która najwierniej odpowiada rzeczywistości. Proste triki, takie jak interpolacja, potrafią szybko powiększyć obrazy, ale często tworzą gładkie, sztuczne efekty. Tradycyjne modele matematyczne bywają lepsze, lecz są powolne i słabną wraz ze wzrostem współczynnika powiększenia. Nawet zaawansowane systemy głębokiego uczenia, oparte na sieciach splotowych lub nowszych modelach Transformer, wciąż mają skłonność do pomijania drobnych linii, tekstur i powtarzalnych wzorów, szczególnie w złożonych scenach, takich jak gęste bloki miejskie czy komiksowa grafika.
Nowy trzyetapowy potok superrozdzielczości
Aby sprostać tym ograniczeniom, autorzy proponują hierarchiczną wieloskalową architekturę transformera (HMT). Przetwarza obraz w trzech głównych etapach. Najpierw płytki ekstraktor cech wychwytuje podstawowe wzory, takie jak krawędzie i proste tekstury, podczas gdy standardowy etap upsampowania zachowuje oryginalną strukturę jako wskazówkę. 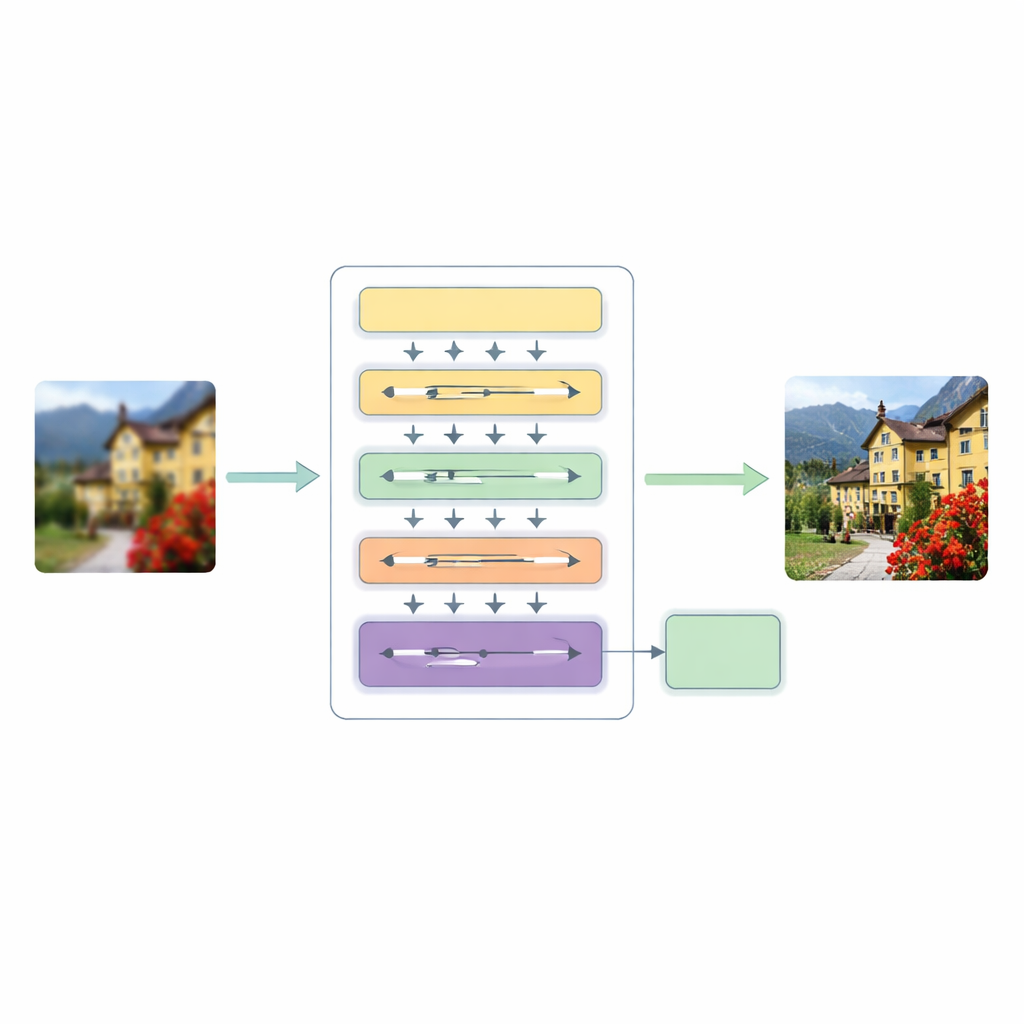
Łączenie wzorców globalnych z detalami lokalnymi
Rdzeniem tego systemu jest hybrydowy mechanizm uwagi, który analizuje obraz na dwa uzupełniające się sposoby. Jedna gałąź działa w dziedzinie częstotliwości, używając transformacji Fouriera do analizowania obrazu pod kątem wzorców globalnych, takich jak szerokie obszary kolorystyczne i powtarzające się struktury. Druga gałąź rozszerza niedawny pomysł modelowania „state space”, aby mogła przemieszczać się po obrazie w wielu kierunkach, wychwytując relacje na długim dystansie bez dużych kosztów tradycyjnej samo-uwagi. Poprzez połączenie tych dwóch perspektyw sieć potrafi zrozumieć zarówno ogólny układ sceny, jak i subtelne powiązania między odległymi, lecz powiązanymi pikselami, przy jednoczesnym utrzymaniu kosztów obliczeniowych na rozsądnym poziomie.
Dostosowywanie się do każdego obrazu w locie
Równolegle model wprowadza dynamiczną konwolucyjną uwagę (Dynamic Convolutional Attention), która skupia wysiłek tam, gdzie obraz tego najbardziej wymaga. Dzieli kanały cech na małe grupy i stosuje lekkie, zależne od obrazu filtry, które naśladują najlepsze cechy uwagi: reagują inaczej dla każdego wejścia i mogą łączyć odległe regiony. Ponieważ niektóre filtry są współdzielone między warstwami, a inne dostosowują się do konkretnego obrazu, system zyskuje elastyczność bez znacznego wzrostu kosztów. Moduł dynamicznej fuzji zastępuje sztywne połączenia skrótowe zwykle spotykane w sieciach koder–dekoder, pozwalając modelowi zdecydować, jak silnie mieszać informacje z różnych skali i głębokości. 
Jak sprawdza się w praktyce?
Naukowcy przetestowali swoją metodę na powszechnie używanych zbiorach obrazów, obejmujących zdjęcia naturalne, sceny miejskie bogate w proste linie i powtarzające się okna oraz strony mangi o wysokim kontraście pełne cienkich kresek tuszem. W kilku standardowych benchmarkach i przy różnych współczynnikach powiększenia ich podejście konsekwentnie dorównywało lub przewyższało wiodące systemy superrozdzielczości, osiągając nieco wyższe wyniki w miarach ostrości i podobieństwa strukturalnego. Porównania wizualne pokazują, że nowy model lepiej zachowuje drobne tekstury, zmniejsza rozmycie wokół krawędzi i wierniej radzi sobie z złożonymi powtarzalnymi wzorami, przy jednoczesnym utrzymaniu liczby parametrów i obliczeń na rozsądnym poziomie.
Wyraźniejsze obrazy dla wielu zastosowań w praktyce
Mówiąc prościej, praca ta oferuje bardziej niezawodny sposób „uzupełniania” brakujących detali podczas przybliżania obrazu. Poprzez staranne połączenie analizy wzorców globalnych, kontekstów kierunkowych i filtracji adaptacyjnej, proponowana architektura generuje ostrzejsze, bardziej spójne wyniki niż wiele istniejących narzędzi. Może to przynieść korzyści zastosowaniom od planowania miejskiego i monitoringu katastrof po obrazowanie medyczne i fotografię konsumencką — wszędzie tam, gdzie potrzebne są wyraźniejsze obrazy, a dostępne są jedynie dane o niskiej rozdzielczości.
Cytowanie: Wang, B., Gao, R., Zhou, T. et al. Hybrid attention optimized hierarchical multiscale transformer architecture for image super-resolution. Sci Rep 16, 13655 (2026). https://doi.org/10.1038/s41598-026-44337-3
Słowa kluczowe: superrozdzielczość obrazu, głębokie uczenie, siecï transformerowe, mechanizmy uwagi, widzenie komputerowe