Clear Sky Science · de
Hybrid aufmerksamkeitsoptimierte hierarchische Multiskalen-Transformer-Architektur für Bild-Superauflösung
Scharfere Bilder aus unscharfen Anfängen
Von Satellitenaufnahmen von Städten über MRT-Scans bis hin zu Smartphone-Schnappschüssen: Viele Bilder sind anfangs verschwommener, als wir es gerne hätten. Bild-Superauflösung umfasst Techniken, die versuchen, aus einer niedrig aufgelösten Version ein scharfes, detailreiches Bild wiederaufzubauen. Dieses Paper stellt eine neue Herangehensweise vor, die eine clevere Mischung moderner KI-Werkzeuge nutzt, um feine Texturen und Kanten zurückzugewinnen, die ältere Methoden häufig verschmieren oder verlieren.
Warum das Schärfen von Bildern so schwierig ist
Aus einem unscharfen Bild ein scharfes zu machen klingt einfach, ist aber ein klassisches „inverse Problem“: Viele verschiedene hochauflösende Szenen können dasselbe verschwommene Bild erzeugen. Die Herausforderung besteht darin, die Version zu erraten, die der Realität am nächsten kommt. Einfache Tricks wie Interpolation vergrößern Bilder zwar schnell, erzeugen jedoch oft glatte, künstlich wirkende Ergebnisse. Traditionelle mathematische Modelle sind besser, arbeiten aber langsam und haben bei größeren Vergrößerungsfaktoren Schwierigkeiten. Selbst leistungsfähige Deep-Learning-Systeme, ob auf Faltungsnetzwerken oder neueren Transformer-Modellen basierend, übersehen häufig winzige Linien, Texturen und wiederkehrende Muster, besonders in komplexen Szenen wie dichten Stadtblöcken oder Comic-Grafiken.
Eine neue dreistufige Super-Resolution-Pipeline
Um diese Schwächen anzugehen, schlagen die Autoren eine Hierarchical Multiscale Transformer (HMT)-Architektur vor. Sie verarbeitet ein Bild in drei Hauptphasen. Zuerst extrahiert ein flaches Merkmal-Extraktor grundlegende Muster wie Kanten und einfache Texturen, während ein standardmäßiger Upsampling-Schritt die ursprüngliche Struktur als Leitlinie bewahrt. 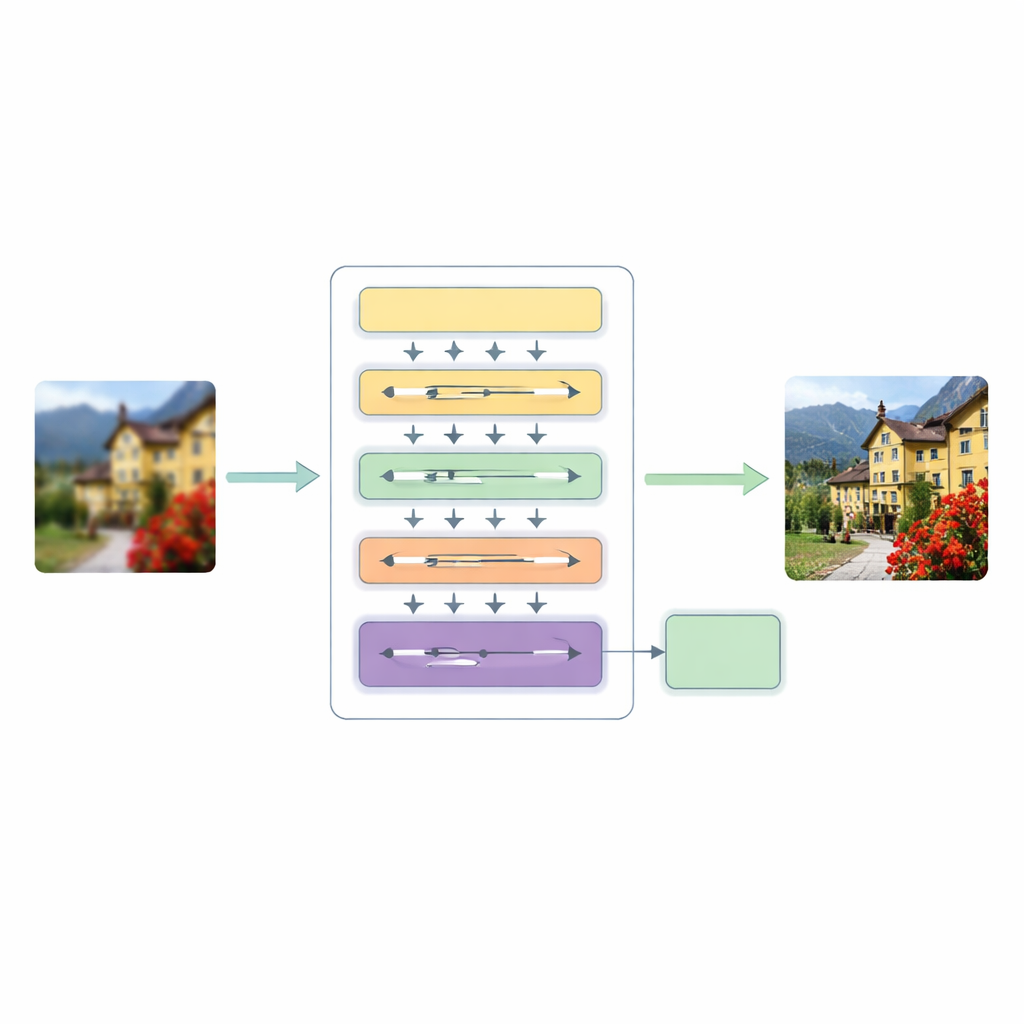
Globale Muster mit lokalen Details verbinden
Der Kern dieses Systems ist ein hybrider Aufmerksamkeitsmechanismus, der das Bild auf zwei komplementäre Arten betrachtet. Ein Zweig arbeitet im Frequenzbereich und nutzt eine Fourier-Transformation, um das Bild in Bezug auf globale Muster wie breite Farbregionen und wiederkehrende Strukturen zu analysieren. Der andere Zweig erweitert eine jüngere „State-Space“-Modellidee, sodass er das Bild in mehreren Richtungen durchlaufen kann und so langfristige Beziehungen erkennt, ohne die hohen Kosten traditioneller Selbstaufmerksamkeit zu verursachen. Durch die Verschmelzung dieser beiden Blickwinkel kann das Netzwerk sowohl das Gesamtgefüge einer Szene als auch subtile Beziehungen zwischen weit auseinanderliegenden, aber verwandten Pixeln erfassen – und das bei beherrschbarem Rechenaufwand.
Sich an jedes Bild im laufenden Betrieb anpassen
Parallel dazu führt das Modell Dynamic Convolutional Attention ein, das seine Ressourcen dort bündelt, wo das Bild es am dringendsten braucht. Es teilt Merkmal-Kanäle in kleine Gruppen und wendet leichte, bildabhängige Filter an, die die besten Eigenschaften von Aufmerksamkeit nachahmen: Sie reagieren unterschiedlich auf jede Eingabe und können weit entfernte Regionen verbinden. Weil einige Filter über Schichten hinweg geteilt werden, während andere sich pro Bild anpassen, gewinnt das System an Flexibilität, ohne die Kosten stark zu erhöhen. Ein dynamisches Fusionsmodul ersetzt dann starre Shortcut-Verbindungen, wie sie üblicherweise in Encoder–Decoder-Netzen zu finden sind, und lässt das Modell entscheiden, wie stark Informationen aus verschiedenen Skalen und Tiefen gemischt werden. 
Wie gut funktioniert es in der Praxis?
Die Forschenden testeten ihre Methode auf weit verbreiteten Bildsammlungen, darunter natürliche Fotos, Stadtszenen mit vielen geraden Linien und wiederkehrenden Fenstern sowie hochkontrastige Manga-Seiten voller feiner Tuschestriche. Über mehrere Standard-Benchmarks und Vergrößerungsfaktoren hinweg entsprach ihr Ansatz konsequent führenden Super-Resolution-Systemen oder übertraf sie, wobei er etwas höhere Werte bei Klarheit und struktureller Ähnlichkeit erreichte. Visuelle Vergleiche zeigen, dass das neue Modell winzige Texturen besser bewahrt, Unschärfen an Kanten reduziert und komplexe wiederkehrende Muster treuer wiedergibt – und das bei einer vernünftigen Anzahl von Parametern und Rechenaufwand.
Klarere Bilder für viele reale Anwendungen
Alltagssprachlich bietet diese Arbeit eine verlässlichere Methode, fehlende Details beim Hineinzoomen in ein Bild „aufzufüllen“. Durch die sorgfältige Kombination aus Analyse globaler Muster, richtungsabhängigem Kontext und adaptiver Filterung erzeugt die vorgeschlagene Architektur schärfere, kohärentere Ergebnisse als viele bestehende Werkzeuge. Das kann Anwendungen von Stadtplanung und Katastrophenüberwachung über medizinische Bildgebung bis hin zur Konsumentenfotografie zugutekommen – überall dort, wo klarere Bilder benötigt werden, aber nur niedrig aufgelöste Daten vorliegen.
Zitation: Wang, B., Gao, R., Zhou, T. et al. Hybrid attention optimized hierarchical multiscale transformer architecture for image super-resolution. Sci Rep 16, 13655 (2026). https://doi.org/10.1038/s41598-026-44337-3
Schlüsselwörter: Bild-Superauflösung, Deep Learning, Transformer-Netzwerke, Aufmerksamkeitsmechanismen, Computer Vision