Clear Sky Science · en
Hybrid attention optimized hierarchical multiscale transformer architecture for image super-resolution
Sharper Pictures from Blurry Beginnings
From satellite photos of cities to MRI scans and smartphone snapshots, many images start out blurrier than we would like. Image super-resolution is a family of techniques that try to rebuild a sharp, detailed picture from a low-resolution version. This paper introduces a new way to do that, using a clever blend of modern AI tools to recover fine textures and edges that older methods tend to smear or lose.
Why Making Images Sharper Is So Hard
Turning a fuzzy image into a sharp one sounds straightforward, but it is a classic “inverse problem”: many different high-resolution scenes can produce the same blurry picture. The challenge is to guess the version that most closely matches reality. Simple tricks such as interpolation can enlarge images quickly but often create smooth, artificial-looking results. Traditional mathematical models can do better, yet they are slow and struggle as the zoom factor increases. Even powerful deep learning systems, whether based on convolutional neural networks or newer Transformer models, still tend to miss tiny lines, textures and repeated patterns, especially in complex scenes like dense city blocks or comic artwork.
A New Three-Stage Super-Resolution Pipeline
To tackle these shortcomings, the authors propose a Hierarchical Multiscale Transformer (HMT) architecture. It processes an image in three main stages. First, a shallow feature extractor captures basic patterns such as edges and simple textures, while a standard upsampling step keeps the original structure as a guide. 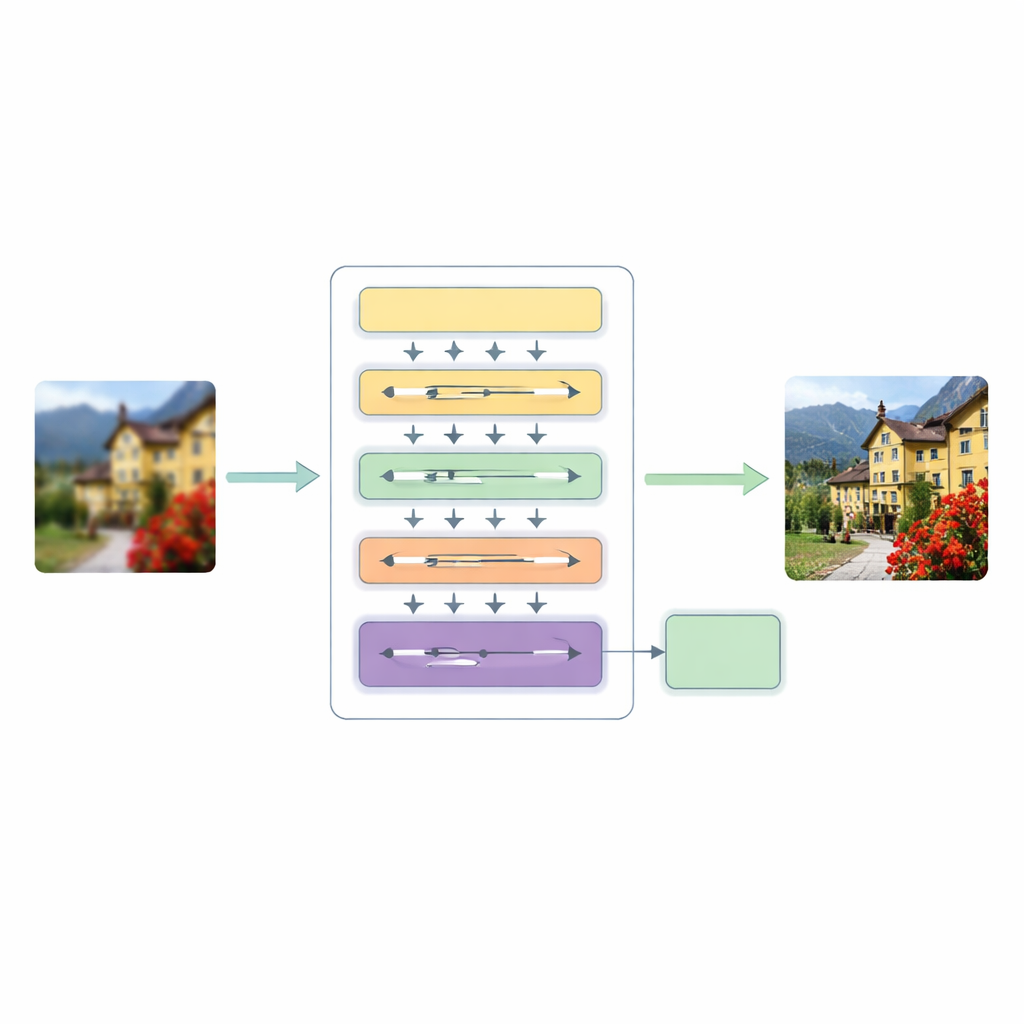
Blending Global Patterns with Local Details
The heart of this system is a hybrid attention mechanism that looks at the image in two complementary ways. One branch works in the frequency domain, using a Fourier transform to analyze the image in terms of global patterns such as broad color regions and repeating structures. The other branch extends a recent "state space" modeling idea so it can sweep across the image in multiple directions, picking up long-range relationships without the heavy cost of traditional self-attention. By fusing these two views, the network can understand both the overall layout of a scene and the subtle relationships between distant but related pixels, all while keeping computation manageable.
Adapting to Each Image on the Fly
In parallel, the model introduces Dynamic Convolutional Attention, which focuses its effort where the image needs it most. It splits feature channels into small groups and applies lightweight, image-dependent filters that mimic the best aspects of attention: they react differently to each input and can connect far-apart regions. Because some filters are shared across layers while others adapt per image, the system gains flexibility without a large increase in cost. A dynamic fusion module then replaces rigid shortcut connections usually found in encoder–decoder networks, letting the model decide how strongly to mix information from different scales and depths. 
How Well Does It Work in Practice?
The researchers tested their method on widely used image collections, including natural photos, city scenes rich in straight lines and repeating windows, and high-contrast manga pages full of fine ink strokes. Across several standard benchmarks and zoom factors, their approach consistently matched or outperformed leading super-resolution systems, achieving slightly higher scores on measures of clarity and structural similarity. Visual comparisons show that the new model better preserves tiny textures, reduces blurring around edges and handles complex repeating patterns more faithfully, all while keeping its number of parameters and computations within a reasonable range.
Clearer Images for Many Real-World Uses
In everyday terms, this work offers a more reliable way to "fill in" missing detail when zooming into an image. By carefully combining global pattern analysis, directional context, and adaptive filtering, the proposed architecture produces sharper, more coherent results than many existing tools. That can benefit applications ranging from urban planning and disaster monitoring to medical imaging and consumer photography, wherever clearer pictures are needed but only low-resolution data are available.
Citation: Wang, B., Gao, R., Zhou, T. et al. Hybrid attention optimized hierarchical multiscale transformer architecture for image super-resolution. Sci Rep 16, 13655 (2026). https://doi.org/10.1038/s41598-026-44337-3
Keywords: image super-resolution, deep learning, transformer networks, attention mechanisms, computer vision