Clear Sky Science · fr
Architecture de transformeur hiérarchique multirésolution optimisée par attention hybride pour la super-résolution d'images
Des images plus nettes à partir de débuts flous
Des photos satellites de villes aux IRM en passant par les clichés pris au smartphone, de nombreuses images commencent plus floues que souhaité. La super-résolution d'images regroupe des techniques visant à reconstruire une image nette et détaillée à partir d'une version basse résolution. Cet article présente une nouvelle approche qui combine habilement des outils d'IA modernes pour retrouver des textures fines et des contours que les méthodes plus anciennes tendent à estomper ou à perdre.
Pourquoi rendre une image plus nette est si difficile
Transformer une image floue en une image nette semble simple, mais c'est un « problème inverse » classique : de nombreuses scènes haute résolution différentes peuvent produire la même image floue. Le défi consiste à deviner la version qui correspond le plus à la réalité. Des astuces simples comme l'interpolation permettent d'agrandir rapidement une image mais donnent souvent des résultats lisses et artificiels. Les modèles mathématiques traditionnels peuvent faire mieux, mais ils sont lents et peinent lorsque le facteur d'agrandissement augmente. Même les systèmes d'apprentissage profond puissants, qu'ils soient basés sur des réseaux de neurones convolutionnels ou sur les modèles Transformer plus récents, ont tendance à rater des lignes minuscules, des textures et des motifs répétés, notamment dans des scènes complexes comme des quartiers urbains denses ou des planches de bande dessinée.
Un nouveau pipeline de super-résolution en trois étapes
Pour répondre à ces lacunes, les auteurs proposent une architecture Hierarchical Multiscale Transformer (HMT). Elle traite l'image en trois grandes étapes. D'abord, un extracteur de caractéristiques peu profond capture des motifs de base tels que les contours et les textures simples, tandis qu'une étape d'upsampling standard conserve la structure d'origine comme guide. 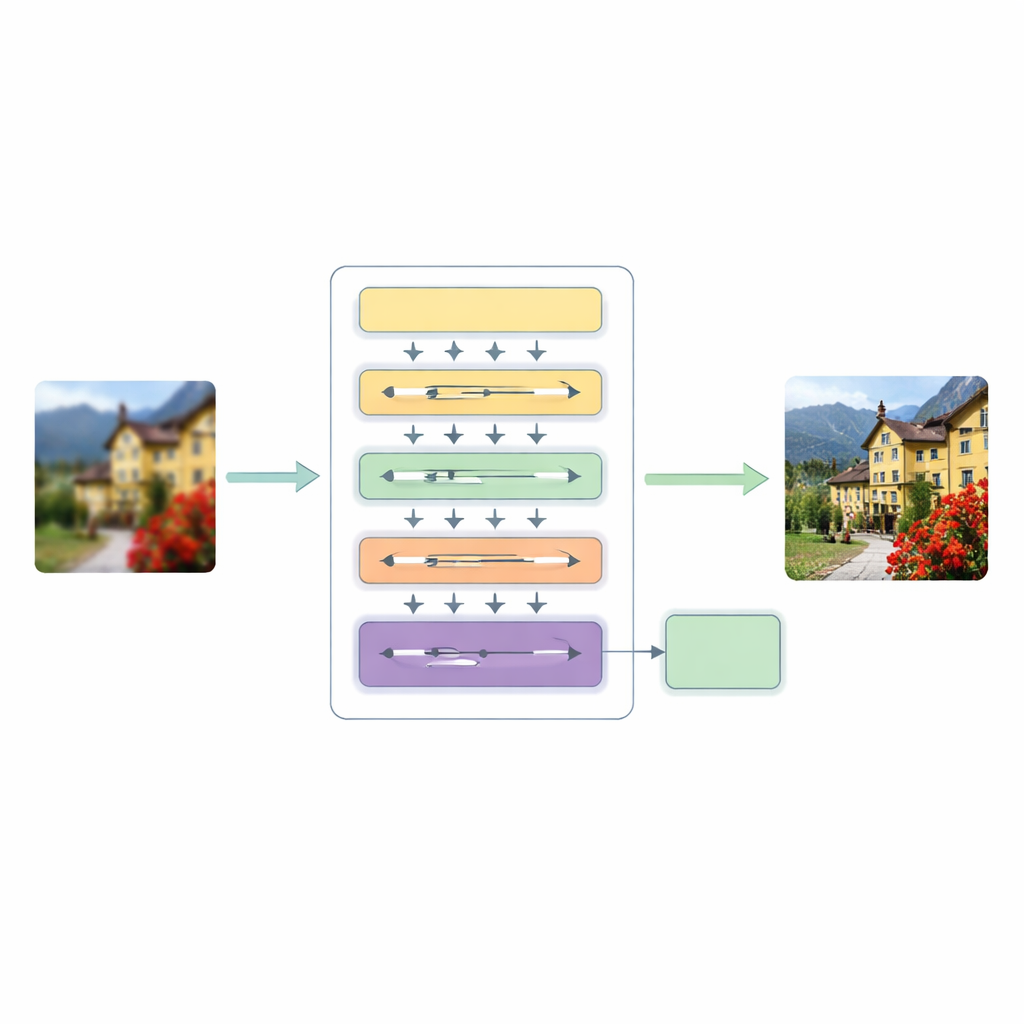
Mêler motifs globaux et détails locaux
Le noyau de ce système est un mécanisme d'attention hybride qui analyse l'image selon deux angles complémentaires. Une branche opère dans le domaine fréquentiel, utilisant une transformée de Fourier pour analyser l'image en termes de motifs globaux comme de larges régions de couleur et des structures répétitives. L'autre branche étend une idée récente de modélisation en « état d'espace » afin de balayer l'image dans plusieurs directions, captant des relations à longue portée sans le coût élevé de l'attention par auto-attention classique. En fusionnant ces deux visions, le réseau comprend à la fois l'agencement général d'une scène et les relations subtiles entre des pixels lointains mais liés, tout en maintenant la charge computationnelle à un niveau raisonnable.
S'adapter à chaque image à la volée
En parallèle, le modèle introduit une Attention Convolutionnelle Dynamique, qui concentre ses efforts là où l'image en a le plus besoin. Il divise les canaux de caractéristiques en petits groupes et applique des filtres légers dépendants de l'image qui imitent les meilleurs aspects de l'attention : ils réagissent différemment selon l'entrée et peuvent relier des régions éloignées. Parce que certains filtres sont partagés entre les couches tandis que d'autres s'adaptent par image, le système gagne en flexibilité sans augmentation majeure des coûts. Un module de fusion dynamique remplace ensuite les raccourcis rigides généralement présents dans les réseaux encodeur–décodeur, permettant au modèle de décider de l'intensité avec laquelle mixer les informations provenant de différentes échelles et profondeurs. 
Quelles performances en pratique ?
Les chercheurs ont testé leur méthode sur des corpus d'images largement utilisés, incluant des photos naturelles, des scènes urbaines riches en lignes droites et en fenêtres répétées, et des pages de manga à fort contraste pleines de traits d'encre fins. Sur plusieurs benchmarks standard et facteurs de zoom, leur approche a systématiquement égalé ou dépassé les meilleurs systèmes de super-résolution, obtenant des scores légèrement supérieurs sur des mesures de netteté et de similarité structurelle. Les comparaisons visuelles montrent que le nouveau modèle préserve mieux les textures fines, réduit le flou autour des contours et gère plus fidèlement les motifs répétitifs complexes, tout en gardant son nombre de paramètres et ses coûts de calcul dans une fourchette raisonnable.
Des images plus claires pour de nombreux usages réels
En termes concrets, ce travail propose un moyen plus fiable de « combler » les détails manquants lors d'un zoom sur une image. En combinant soigneusement l'analyse des motifs globaux, le contexte directionnel et le filtrage adaptatif, l'architecture proposée produit des résultats plus nets et cohérents que beaucoup d'outils existants. Cela peut profiter à des applications allant de l'aménagement urbain et la surveillance des catastrophes à l'imagerie médicale et la photographie grand public, partout où des images plus claires sont nécessaires mais seules des données basse résolution sont disponibles.
Citation: Wang, B., Gao, R., Zhou, T. et al. Hybrid attention optimized hierarchical multiscale transformer architecture for image super-resolution. Sci Rep 16, 13655 (2026). https://doi.org/10.1038/s41598-026-44337-3
Mots-clés: super-résolution d'image, apprentissage profond, réseaux de transformeurs, mécanismes d'attention, vision par ordinateur