Clear Sky Science · ru
Гибридная оптимизированная иерархическая многомасштабная архитектура трансформера для сверхразрешения изображений
Четче картинки из размытого начала
От спутниковых снимков городов до МРТ и фотографий со смартфонов — многие изображения изначально более размыты, чем хотелось бы. Сверхразрешение изображений — это набор методов, которые пытаются восстановить резкое и детализированное изображение из низкого разрешения. В этой работе предложен новый подход, сочетающий современные инструменты ИИ, чтобы восстановить тонкие текстуры и контуры, которые старые методы часто размывают или теряют.
Почему сделать изображение резким так сложно
Преобразовать нечеткое изображение в резкое звучит просто, но это классическая «обратная задача»: одно и то же размытое изображение может соответствовать многим различным сценам высокого разрешения. Задача — угадать версию, которая наиболее близка к реальности. Простые методы, такие как интерполяция, быстро увеличивают изображение, но часто дают гладкие, искусственные результаты. Традиционные математические модели работают лучше, но медленны и испытывают сложности при больших коэффициентах увеличения. Даже мощные системы глубокого обучения, основанные на сверточных нейронных сетях или новых моделях Transformer, по-прежнему склонны пропускать тонкие линии, текстуры и повторяющиеся узоры, особенно в сложных сценах, таких как плотная городская застройка или комиксы.
Новый трёхэтапный конвейер сверхразрешения
Чтобы преодолеть эти ограничения, авторы предлагают иерархическую многомасштабную архитектуру трансформера (HMT). Она обрабатывает изображение в три основных этапа. Сначала неглубокий извлекатель признаков фиксирует базовые шаблоны — края и простые текстуры, а стандартный шаг увеличения служит ориентиром, сохраняя исходную структуру. 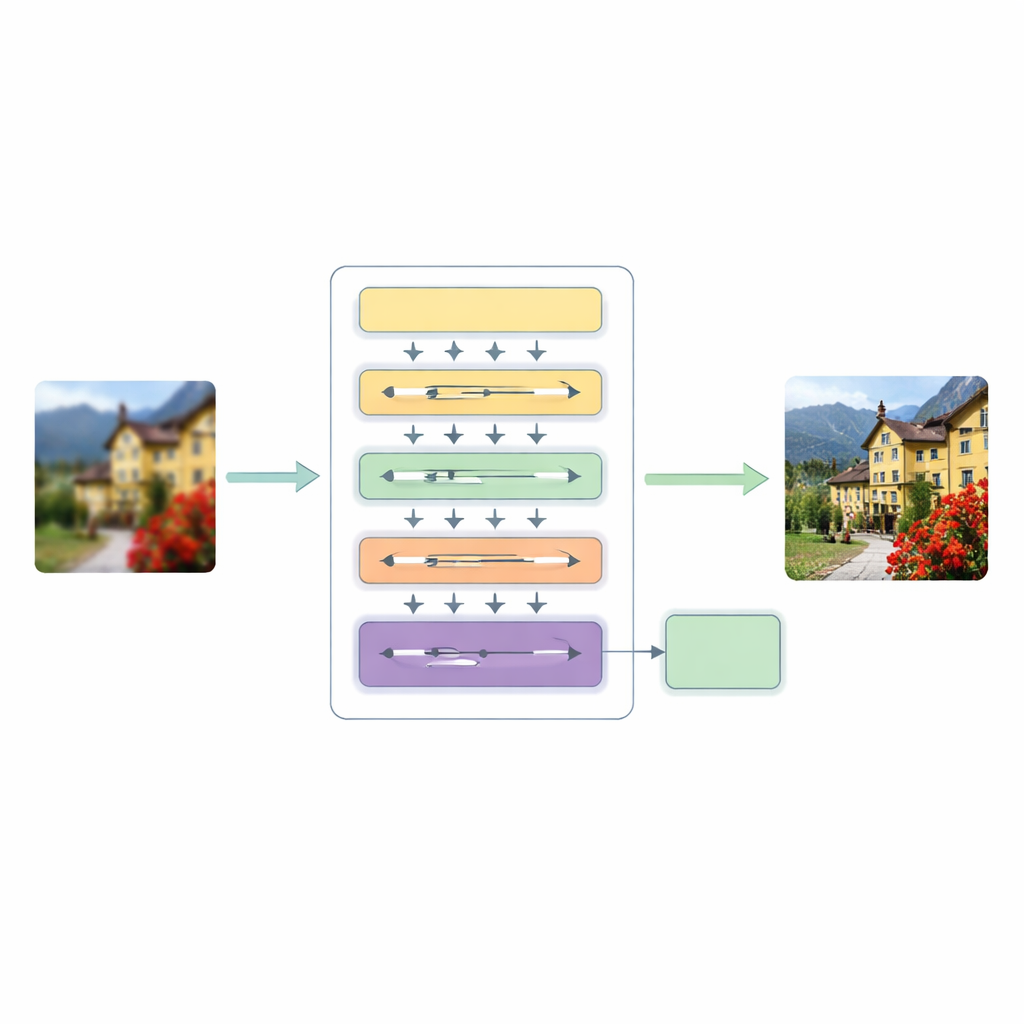
Слияние глобальных паттернов с локальными деталями
Ядро системы — гибридный механизм внимания, который смотрит на изображение двумя взаимодополняющими способами. Одна ветвь работает в частотной области, используя преобразование Фурье для анализа изображения с точки зрения глобальных паттернов, таких как крупные цветовые области и повторяющиеся структуры. Другая ветвь развивает недавнюю идею моделирования в пространстве состояния, позволяя просеивать изображение в нескольких направлениях и улавливать дальнодействующие взаимосвязи без тяжёлых вычислений классического самовнимания. Сливая эти два взгляда, сеть понимает и общую компоновку сцены, и тонкие связи между удалёнными, но связанными пикселями, при этом сохраняя вычисления в разумных пределах.
Адаптация к каждому изображению на лету
Параллельно в модели введено динамическое свёрточное внимание, которое фокусирует ресурсы там, где изображение в этом больше всего нуждается. Оно разбивает каналы признаков на небольшие группы и применяет лёгкие зависящие от изображения фильтры, которые имитируют лучшие свойства внимания: они по-разному реагируют на каждый вход и могут связывать далеко расположенные регионы. Поскольку часть фильтров общая между слоями, а часть адаптируется под конкретное изображение, система получает гибкость без значительного увеличения затрат. Модуль динамического слияния затем заменяет жёсткие пропуски-соединения, обычно встречающиеся в сетях кодер–декодер, позволяя модели самостоятельно решать, насколько сильно смешивать информацию с разных масштабов и уровней глубины. 
Насколько хорошо это работает на практике?
Исследователи протестировали метод на общепринятых наборах изображений, включая природные фотографии, городские сцены с множеством прямых линий и повторяющихся окон, а также страницы манги с высококонтрастными тонкими штрихами. По ряду стандартных бенчмарков и коэффициентов увеличения их подход последовательно сопоставлял или превосходил ведущие системы сверхразрешения, демонстрируя небольшое преимущество по метрикам чёткости и структурного сходства. Визуальные сравнения показывают, что новая модель лучше сохраняет мельчайшие текстуры, снижает размытие вокруг краёв и более точно воспроизводит сложные повторяющиеся узоры, при этом оставаясь в разумных пределах по числу параметров и вычислительным затратам.
Более чёткие изображения для многих реальных задач
Проще говоря, эта работа предлагает более надёжный способ «добавлять» отсутствующие детали при увеличении изображения. Тщательно сочетая анализ глобальных паттернов, направленный контекст и адаптивную фильтрацию, предложенная архитектура даёт более резкие и согласованные результаты, чем многие существующие инструменты. Это может быть полезно в приложениях от градостроительного планирования и мониторинга стихийных бедствий до медицинской визуализации и потребительской фотографии — везде, где нужны более чёткие изображения, но доступны только данные низкого разрешения.
Цитирование: Wang, B., Gao, R., Zhou, T. et al. Hybrid attention optimized hierarchical multiscale transformer architecture for image super-resolution. Sci Rep 16, 13655 (2026). https://doi.org/10.1038/s41598-026-44337-3
Ключевые слова: сверхразрешение изображений, глубокое обучение, сети трансформеров, механизмы внимания, компьютерное зрение