Clear Sky Science · it
Architettura Transformer gerarchica multiscala ottimizzata con attenzione ibrida per la super-risoluzione delle immagini
Immagini più nitide da inizi sfocate
Dalle foto satellitari delle città alle risonanze magnetiche fino agli scatti da smartphone, molte immagini sono inizialmente più sfocate di quanto vorremmo. La super-risoluzione delle immagini è un insieme di tecniche che cercano di ricostruire un'immagine nitida e dettagliata a partire da una versione a bassa risoluzione. Questo articolo presenta un nuovo approccio che utilizza una combinazione intelligente di strumenti AI moderni per recuperare texture e contorni fini che i metodi più vecchi tendono a sfumare o perdere.
Perché rendere le immagini più nitide è così difficile
Trasformare un'immagine sfocata in una nitida sembra semplice, ma è un classico “problema inverso”: molte diverse scene ad alta risoluzione possono generare la stessa immagine sfocata. La sfida è indovinare la versione che più si avvicina alla realtà. Trucchi semplici come l'interpolazione possono ingrandire le immagini rapidamente ma spesso producono risultati lisci e artificiali. I modelli matematici tradizionali possono fare meglio, ma sono lenti e faticano con fattori di ingrandimento elevati. Anche i potenti sistemi di deep learning, basati su reti convoluzionali o sui più recenti modelli Transformer, tendono ancora a perdere linee sottili, texture e motivi ripetuti, specialmente in scene complesse come isolati cittadini densi o tavole a fumetti.
Una nuova pipeline di super-risoluzione in tre fasi
Per affrontare queste carenze, gli autori propongono un'architettura Hierarchical Multiscale Transformer (HMT). Essa elabora l'immagine in tre fasi principali. Innanzitutto, un estrattore di caratteristiche superficiali cattura pattern di base come bordi e texture semplici, mentre un passaggio di upsampling standard mantiene la struttura originale come guida. 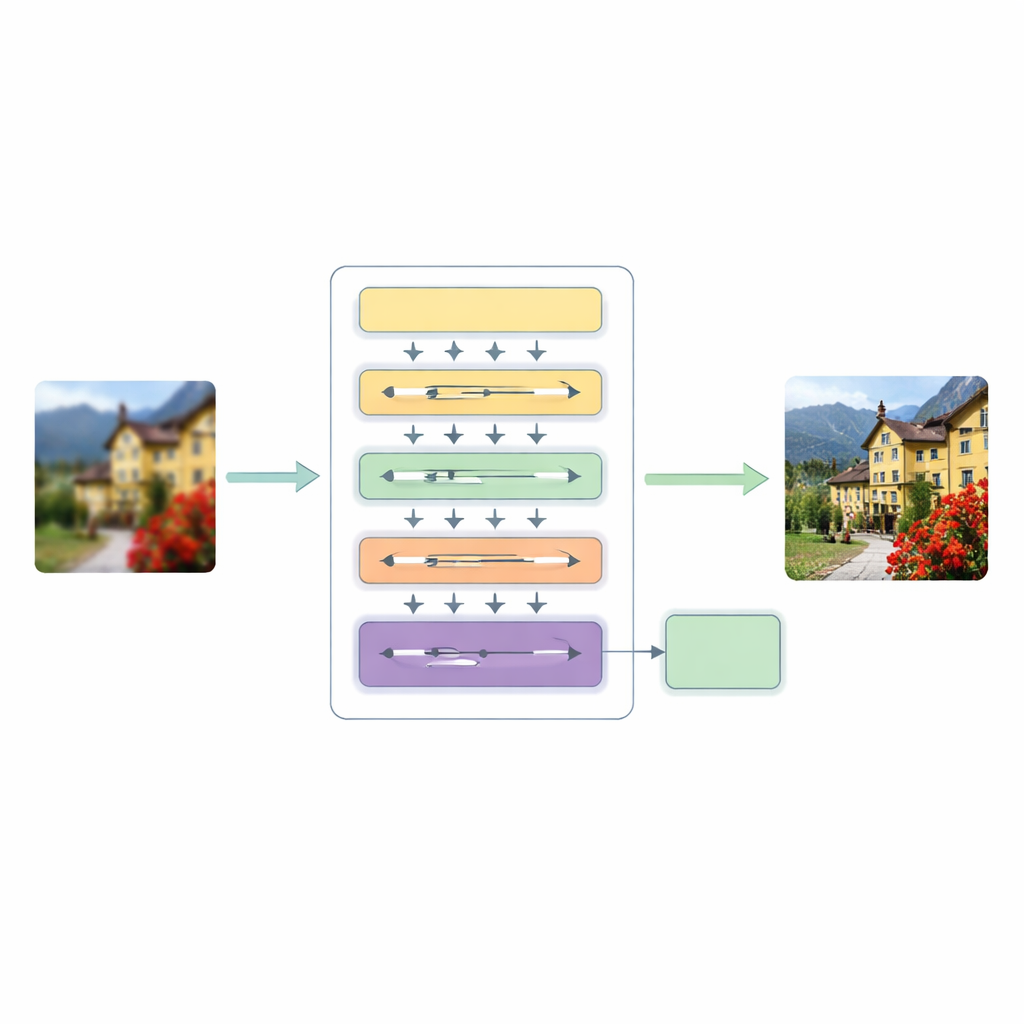
Fondere pattern globali e dettagli locali
Il cuore del sistema è un meccanismo di attenzione ibrido che osserva l'immagine in due modi complementari. Un ramo opera nel dominio delle frequenze, usando una trasformata di Fourier per analizzare l'immagine in termini di pattern globali come ampie regioni cromatiche e strutture ripetute. L'altro ramo estende una recente idea di modellizzazione “state space” in modo che possa scorrere attraverso l'immagine in più direzioni, cogliendo relazioni a lungo raggio senza il costo computazionale elevato dell'auto-attenzione tradizionale. Fondendo queste due prospettive, la rete può comprendere sia la disposizione generale della scena sia le sottili relazioni tra pixel distanti ma correlati, mantenendo al contempo la complessità computazionale su livelli gestibili.
Adattarsi a ogni immagine al volo
Parallelamente, il modello introduce la Dynamic Convolutional Attention, che concentra gli sforzi dove l'immagine ne ha più bisogno. Divide i canali di feature in piccoli gruppi e applica filtri leggeri dipendenti dall'immagine che imitano i migliori aspetti dell'attenzione: reagiscono diversamente a ogni input e possono collegare regioni lontane. Poiché alcuni filtri sono condivisi tra i livelli mentre altri si adattano per immagine, il sistema guadagna flessibilità senza un forte aumento dei costi. Un modulo di fusione dinamica sostituisce quindi le connessioni di shortcut rigide solitamente presenti nelle reti encoder–decoder, permettendo al modello di decidere quanto intensamente miscelare informazioni da scale e profondità diverse. 
Quanto bene funziona in pratica?
I ricercatori hanno testato il loro metodo su collezioni di immagini ampiamente utilizzate, incluse foto naturali, scene urbane ricche di linee rette e finestre ripetute, e pagine di manga ad alto contrasto piene di sottili tratti d'inchiostro. Su diversi benchmark standard e fattori di zoom, il loro approccio ha costantemente eguagliato o superato i principali sistemi di super-risoluzione, ottenendo punteggi leggermente superiori sulle misure di nitidezza e similarità strutturale. Confronti visivi mostrano che il nuovo modello preserva meglio texture minute, riduce la sfocatura intorno ai bordi e gestisce motivi ripetuti complessi in modo più fedele, mantenendo al contempo il numero di parametri e i requisiti computazionali entro margini ragionevoli.
Immagini più chiare per molti usi reali
In termini pratici, questo lavoro offre un modo più affidabile per “colmare” i dettagli mancanti quando si ingrandisce un'immagine. Combinando con cura analisi dei pattern globali, contesto direzionale e filtraggio adattivo, l'architettura proposta produce risultati più nitidi e coerenti rispetto a molti strumenti esistenti. Ciò può avvantaggiare applicazioni che vanno dalla pianificazione urbanistica e dal monitoraggio delle catastrofi all'imaging medico e alla fotografia di consumo, ovunque siano necessarie immagini più chiare ma siano disponibili solo dati a bassa risoluzione.
Citazione: Wang, B., Gao, R., Zhou, T. et al. Hybrid attention optimized hierarchical multiscale transformer architecture for image super-resolution. Sci Rep 16, 13655 (2026). https://doi.org/10.1038/s41598-026-44337-3
Parole chiave: super-risoluzione delle immagini, apprendimento profondo, reti Transformer, meccanismi di attenzione, visione artificiale