Clear Sky Science · nl
Hybride aandacht geoptimaliseerde hiërarchische multiscale transformer-architectuur voor beeld-superresolutie
Scherpere beelden uit vage beginnen
Van satellietfoto's van steden tot MRI-scans en smartphone-opnamen: veel beelden starten vager dan we zouden willen. Beeld-superresolutie is een verzameling technieken die proberen een scherp, gedetailleerd beeld te reconstrueren uit een laagresolutieversie. Dit artikel introduceert een nieuwe manier om dat te doen, met een slimme mix van moderne AI-instrumenten om fijne texturen en randen terug te halen die oudere methoden vaak vervagen of verliezen.
Waarom het verscherpen van beelden zo moeilijk is
Een wazig beeld omzetten in een scherp beeld klinkt eenvoudig, maar het is een klassiek "inverse probleem": meerdere verschillende high-resolution scènes kunnen hetzelfde vage beeld opleveren. De uitdaging is te raden welke versie het meest overeenkomt met de werkelijkheid. Eenvoudige trucs zoals interpolatie kunnen afbeeldingen snel vergroten maar leveren vaak gladde, kunstmatige resultaten op. Traditionele wiskundige modellen kunnen beter presteren, maar zijn traag en hebben moeite naarmate de vergrotingsfactor toeneemt. Zelfs krachtige deep learning-systemen, of ze nu gebaseerd zijn op convolutionele neurale netwerken of nieuwere Transformer-modellen, missen nog vaak fijne lijntjes, texturen en herhaalde patronen, vooral in complexe scènes zoals dichtbebouwde stadswijken of striptekeningen.
Een nieuwe driedelige superresolutie-pijplijn
Om deze tekortkomingen aan te pakken, stellen de auteurs een Hierarchical Multiscale Transformer (HMT)-architectuur voor. Deze verwerkt een afbeelding in drie hoofd-stadia. Eerst vangt een ondiepe feature-extractor basale patronen op zoals randen en eenvoudige texturen, terwijl een standaard opschaalstap de oorspronkelijke structuur als leidraad behoudt. 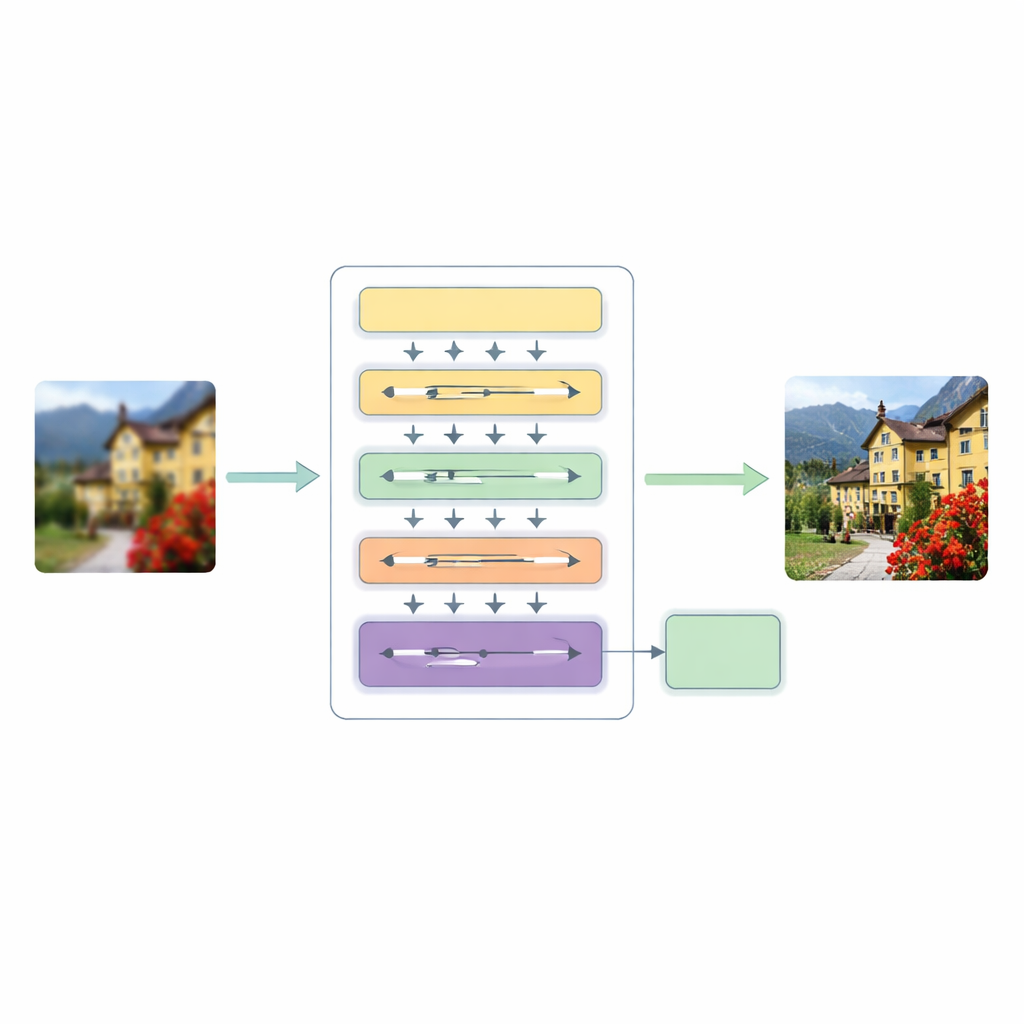
Globale patronen mengen met lokale details
Het hart van dit systeem is een hybride attentie-mechanisme dat het beeld op twee aanvullende manieren bekijkt. De ene tak werkt in het frequentiedomein en gebruikt een Fourier-transformatie om het beeld te analyseren in termen van globale patronen zoals brede kleurvlakken en herhalende structuren. De andere tak breidt een recente "state space"-modellering uit zodat deze over het beeld in meerdere richtingen kan vegen en langeafstandrelaties kan oppikken zonder de hoge kosten van traditionele self-attention. Door deze twee gezichtspunten te versmelten, kan het netwerk zowel de algehele opzet van een scène begrijpen als de subtiele relaties tussen ver uit elkaar liggende maar gerelateerde pixels, terwijl de rekencapaciteit beheersbaar blijft.
Sich aan elk beeld aanpassen tijdens verwerking
Parallel introduceert het model Dynamic Convolutional Attention, dat zijn inspanning richt waar het beeld het meest behoefte heeft. Het splitst feature-kanalen in kleine groepen en past lichtgewicht, afbeeldingsafhankelijke filters toe die de beste eigenschappen van attentie nabootsen: ze reageren verschillend op elke input en kunnen ver verwijderde regio's koppelen. Omdat sommige filters over lagen gedeeld zijn terwijl andere per afbeelding aanpassen, krijgt het systeem flexibiliteit zonder een grote toename van de kosten. Een dynamische fusie-module vervangt vervolgens de starre shortcut-verbindingen die gewoonlijk in encoder–decoder-netwerken voorkomen, waardoor het model kan bepalen hoe sterk informatie van verschillende schalen en dieptes gemengd wordt. 
Hoe presteert het in de praktijk?
De onderzoekers testten hun methode op veelgebruikte beelddatasets, waaronder natuurfoto's, stadsgezichten met veel rechte lijnen en herhalende ramen, en hoogcontrast manga-pagina's vol fijne inkstreken. Over meerdere standaard benchmarks en vergrotingsfactoren presteerde hun aanpak consequent gelijk aan of beter dan toonaangevende superresolutie-systemen, met iets hogere scores op maatstaven voor scherpte en structurele gelijkenis. Visuele vergelijkingen tonen aan dat het nieuwe model fijne texturen beter behoudt, vervaging rond randen vermindert en complexe herhalende patronen trouwreproduceert, terwijl het aantal parameters en de benodigde berekeningen binnen een redelijk bereik blijven.
Schoner beeld voor veel praktische toepassingen
In alledaagse termen biedt dit werk een betrouwbaardere manier om ontbrekende details "in te vullen" bij het inzoomen op een afbeelding. Door zorgvuldig globale patroonanalyse, directionele context en adaptieve filtering te combineren, produceert de voorgestelde architectuur scherpere, coherente resultaten dan veel bestaande hulpmiddelen. Dat kan toepassingen ten goede komen van stedelijke planning en rampenmonitoring tot medische beeldvorming en consumentfotografie, overal waar scherpere beelden nodig zijn maar alleen laagresolutiegegevens beschikbaar zijn.
Bronvermelding: Wang, B., Gao, R., Zhou, T. et al. Hybrid attention optimized hierarchical multiscale transformer architecture for image super-resolution. Sci Rep 16, 13655 (2026). https://doi.org/10.1038/s41598-026-44337-3
Trefwoorden: beeld-superresolutie, deep learning, transformator-netwerken, aandachtsmechanismen, computer vision