Clear Sky Science · pt
Arquitetura transformadora hierárquica multiescala otimizada por atenção híbrida para super-resolução de imagens
Imagens mais nítidas a partir de começos borrados
De fotos de satélite de cidades a exames de ressonância magnética e fotos de smartphones, muitas imagens começam mais borradas do que gostaríamos. Super-resolução de imagem é um conjunto de técnicas que tentam reconstruir uma imagem nítida e detalhada a partir de uma versão de baixa resolução. Este artigo apresenta uma nova forma de fazer isso, usando uma combinação inteligente de ferramentas modernas de IA para recuperar texturas finas e contornos que métodos mais antigos tendem a borrar ou perder.
Por que é tão difícil deixar imagens mais nítidas
Transformar uma imagem embaçada em uma nítida soa simples, mas é um clássico “problema inverso”: muitas cenas em alta resolução diferentes podem produzir a mesma imagem borrada. O desafio é estimar a versão que mais se aproxima da realidade. Truques simples, como interpolação, podem ampliar imagens rapidamente, mas frequentemente geram resultados suaves e artificiais. Modelos matemáticos tradicionais podem ser melhores, porém são lentos e têm dificuldade quando o fator de ampliação aumenta. Mesmo sistemas poderosos de aprendizado profundo, sejam baseados em redes neurais convolucionais ou em modelos Transformer mais recentes, ainda tendem a perder linhas finas, texturas e padrões repetidos, especialmente em cenas complexas como quarteirões densos de cidade ou obras em quadrinhos.
Um novo pipeline de super-resolução em três estágios
Para enfrentar essas limitações, os autores propõem uma arquitetura Hierarchical Multiscale Transformer (HMT). Ela processa a imagem em três estágios principais. Primeiro, um extrator de características superficial captura padrões básicos, como bordas e texturas simples, enquanto uma etapa padrão de upsampling mantém a estrutura original como guia. 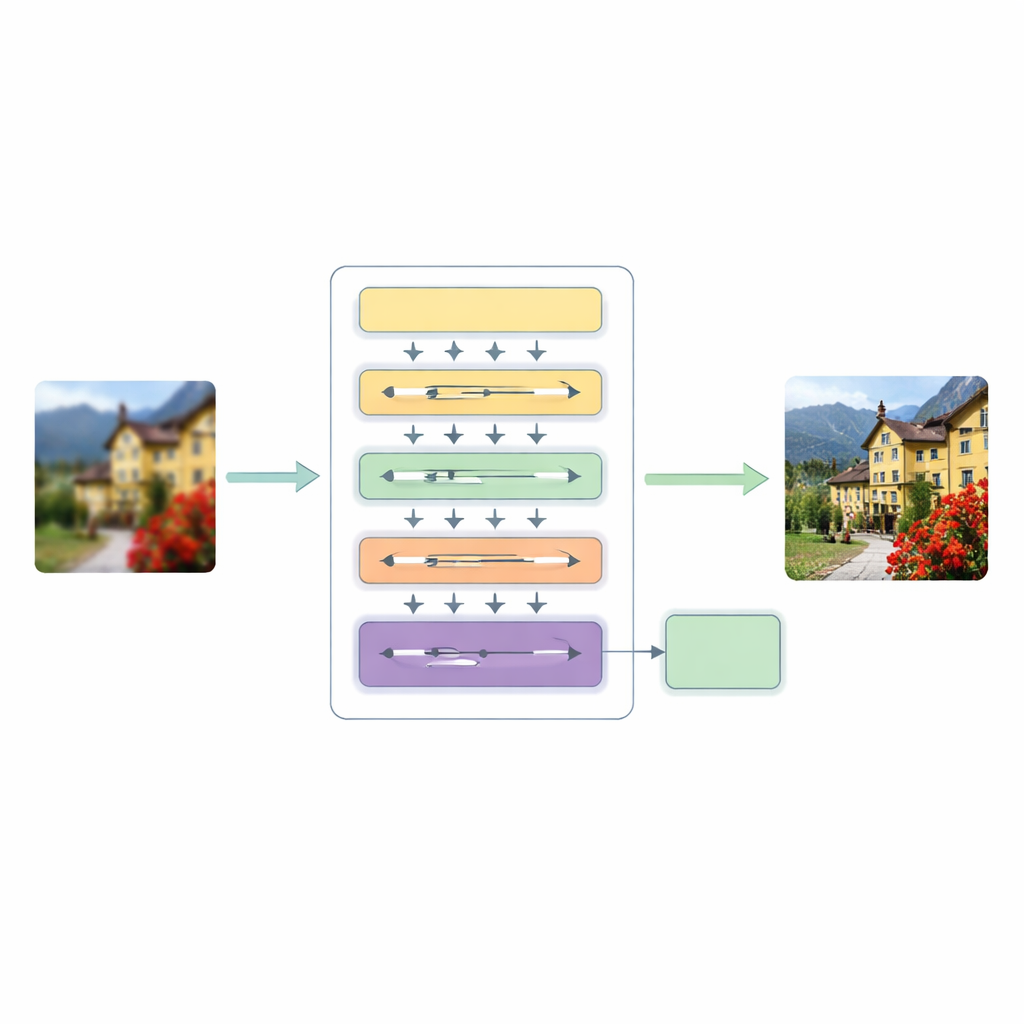
Misturando padrões globais com detalhes locais
O coração desse sistema é um mecanismo de atenção híbrida que observa a imagem de duas maneiras complementares. Um ramo atua no domínio da frequência, usando uma transformada de Fourier para analisar a imagem em termos de padrões globais, como grandes regiões de cor e estruturas repetitivas. O outro ramo amplia uma ideia recente de modelagem em “state space” para que possa varrer a imagem em várias direções, captando relações de longo alcance sem o alto custo da auto-atenção tradicional. Ao fundir essas duas visões, a rede pode entender tanto a disposição geral da cena quanto as relações sutis entre pixels distantes, mantendo a carga computacional manejável.
Adaptando-se a cada imagem em tempo real
Em paralelo, o modelo introduz Atenção Convolucional Dinâmica, que concentra o esforço onde a imagem mais precisa. Ele divide os canais de características em pequenos grupos e aplica filtros leves dependentes da imagem que imitam os melhores aspectos da atenção: reagem de forma diferente a cada entrada e podem conectar regiões distantes. Como alguns filtros são compartilhados entre camadas enquanto outros se adaptam por imagem, o sistema ganha flexibilidade sem aumento grande de custo. Um módulo de fusão dinâmica então substitui conexões de atalho rígidas normalmente encontradas em redes codificador–decodificador, permitindo que o modelo decida com que intensidade misturar informações de diferentes escalas e profundidades. 
Que tão bem funciona na prática?
Os pesquisadores testaram seu método em coleções de imagens amplamente usadas, incluindo fotos naturais, cenas urbanas ricas em linhas retas e janelas repetidas, e páginas de mangá de alto contraste cheias de traços de tinta finos. Em vários benchmarks padrão e fatores de ampliação, sua abordagem igualou ou superou consistentemente os principais sistemas de super-resolução, alcançando pontuações ligeiramente melhores em medidas de nitidez e similaridade estrutural. Comparações visuais mostram que o novo modelo preserva melhor texturas minúsculas, reduz o desfoque nas bordas e lida de forma mais fiel com padrões repetidos complexos, tudo enquanto mantém o número de parâmetros e as contas computacionais dentro de um intervalo razoável.
Imagens mais claras para muitos usos do mundo real
Em termos práticos, este trabalho oferece uma forma mais confiável de “preencher” detalhes faltantes ao dar zoom em uma imagem. Ao combinar cuidadosamente análise de padrões globais, contexto direcional e filtragem adaptativa, a arquitetura proposta produz resultados mais nítidos e coerentes do que muitas ferramentas existentes. Isso pode beneficiar aplicações que vão desde planejamento urbano e monitoramento de desastres até imagem médica e fotografia do consumidor, sempre que imagens mais claras são necessárias, mas apenas dados de baixa resolução estão disponíveis.
Citação: Wang, B., Gao, R., Zhou, T. et al. Hybrid attention optimized hierarchical multiscale transformer architecture for image super-resolution. Sci Rep 16, 13655 (2026). https://doi.org/10.1038/s41598-026-44337-3
Palavras-chave: super-resolução de imagem, aprendizado profundo, redes Transformer, mecanismos de atenção, visão computacional