Clear Sky Science · tr
Geri yayılmasız, ileri–ileri algoritmalı dikenli sinir ağları
Bilgisayarlara Dikenlerde Düşünmeyi Öğretmek
Bugünün en akıllı makinelerinin çoğu, beyinde olup bitene hiç benzemeyen matematikle öğrenir. Bu makale, gerçek nöronlara benzer kısa elektriksel darbelerle iletişim kuran “dikenli” sinir ağlarını —standart geri yayılma reçetesine dayanmayarak— eğitmenin yeni bir yolunu araştırıyor. Yazarlar, ileri–ileri adı verilen beyin ilhamlı bir yöntemin bu dikenli ağlara görüntüleri ve sesleri tanımayı, mevcut en iyi yöntemlere yakın ve bazen onlardan daha iyi doğrulukla öğretebildiğini; ayrıca düşük güçlü nöromorfik donanımlarla daha uyumlu olduğunu gösteriyorlar.
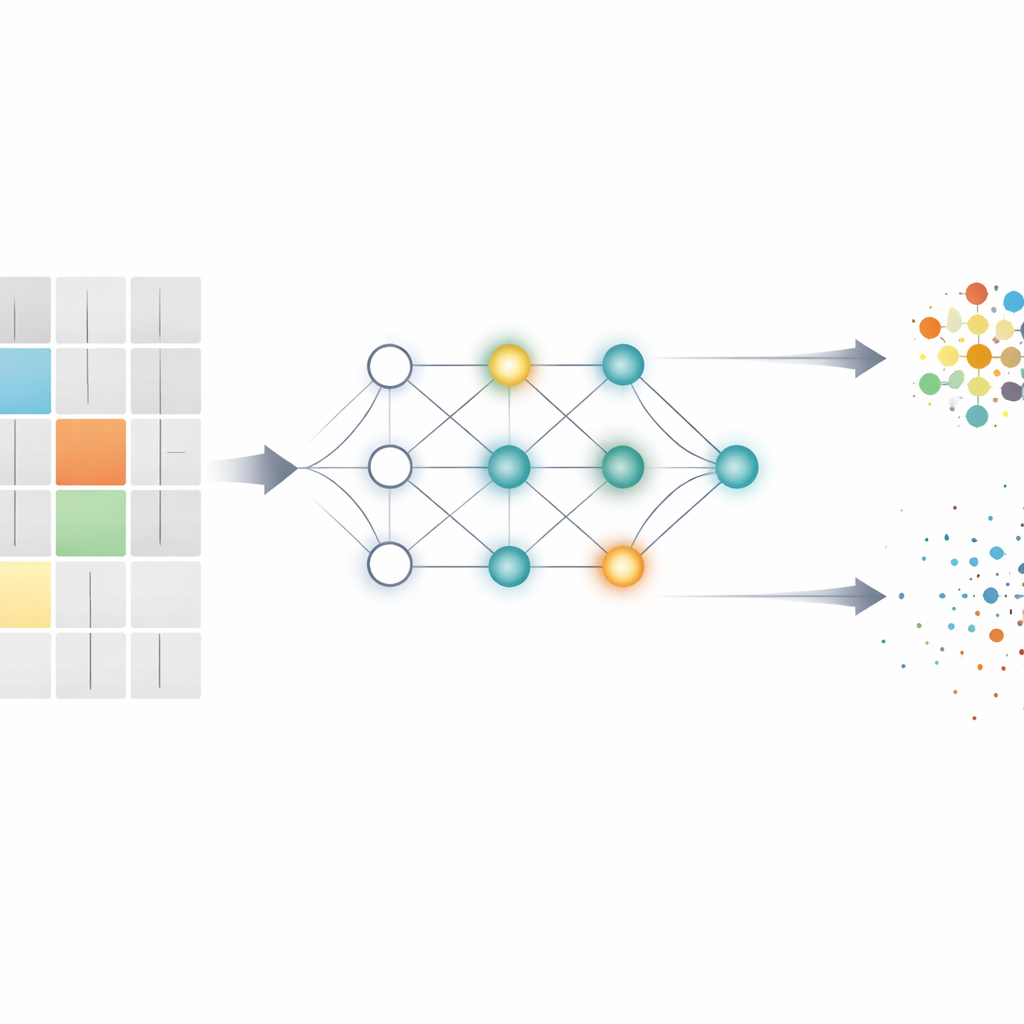
Dikenli Beyinleri Eğitmenin Zorluğu
Dikenli sinir ağları bilgiyi sürekli, pürüzsüz sayılar yerine zaman boyunca ortaya çıkan ayrık patlamalar veya dikenler aracılığıyla işler. Bu, enerji verimli hesaplama ve biyolojik beyinleri taklit etme açısından cazip kılar. Ancak bu, geleneksel öğrenme algoritmaları için baş ağrısı yaratır: geri yayılma, nöronlar arasındaki bağlantıları ayarlamak için pürüzsüz gradyanlara ihtiyaç duyar; oysa dikenler ya vardır ya yoktur. Surrogate gradyanlar gibi geçici çözümler—dikenleri öğrenme sırasında pürüzsüzmüş gibi sayan yöntemler—mevcut olsa da, geri yayılma hala büyük miktarda ara etkinliği depolamayı ve her katman boyunca hassas hata sinyallerini geri göndermeyi gerektirir; bu varsayımlar hem hesaplama açısından ağırdır hem de biyolojik olarak gerçekçi değildir.
Farklı Bir Yol: İki İleri Geçişle Öğrenme
İleri–ileri algoritması buna zıt bir yaklaşım sunar. Bir ileri geçişi ve ardından bir geri hata süpürmesi yerine, ağın her katmanı yalnızca iki ileri geçiş kullanılarak eğitilir: biri doğru etikete uyan “pozitif” örneklerle, diğeri kontrollü olarak yanlış olacak şekilde oluşturulmuş “negatif” örneklerle. Her katman, nöronlarının ne kadar güçlü yanıt verdiğine dayalı olarak “iyi oluş” (goodness) adı verilen basit bir puan ölçer. Amaç, pozitif girdiler için iyi oluşu yüksek, negatifler için düşük tutmaktır. Her katman yalnızca kendi etkinliğini kullanarak bağlantılarını güncellediği için tüm ağ boyunca hata sinyallerini göndermeye gerek kalmaz; algoritma daha yerel, modüler ve donanım-dostu hale gelir.
İleri–İleriyi Dikenlerle Çalıştırmak
Yazarlar bu fikri, girdilerin ve etiketlerin nasıl kodlandığını ve iyi oluşun nasıl ölçüldüğünü dikkatle tasarlayarak dikenli ağlara uyarlar. Önce, görüntüler veya ses desenleri oran kodlaması kullanılarak diken dizilerine dönüştürülür—daha yoğun girdiler kısa bir zaman dizisi boyunca daha çok diken üretir. Etiketler girdinin bir bölümüne doğrudan yerleştirilir, böylece tek bir vektör hem veriyi hem de aday sınıfı taşır. Pozitif örnekler doğru etiketi kullanır; negatif örnekler ise ağın karıştırma eğiliminde olduğu sınıflardan kasıtlı olarak “zor” bir yanlış etiket seçilerek oluşturulur. Sızan entegrasyon ve ateşleme (leaky integrate-and-fire) nöronlarından oluşan katmanlar boyunca dikenler akarken, model her nöronun pozitif ve negatif geçişlerde ne sıklıkta ateşlendiğini sayar. Bir katmanın iyi oluşu bundan sonra toplam diken sayılarıyla tanımlanır ve düzgün bir kayıp fonksiyonu pozitif iyi oluşun negatif iyi oluşun üzerine rahat bir marjla çıkmasını teşvik ederken gradyanların stabil kalmasını sağlar.
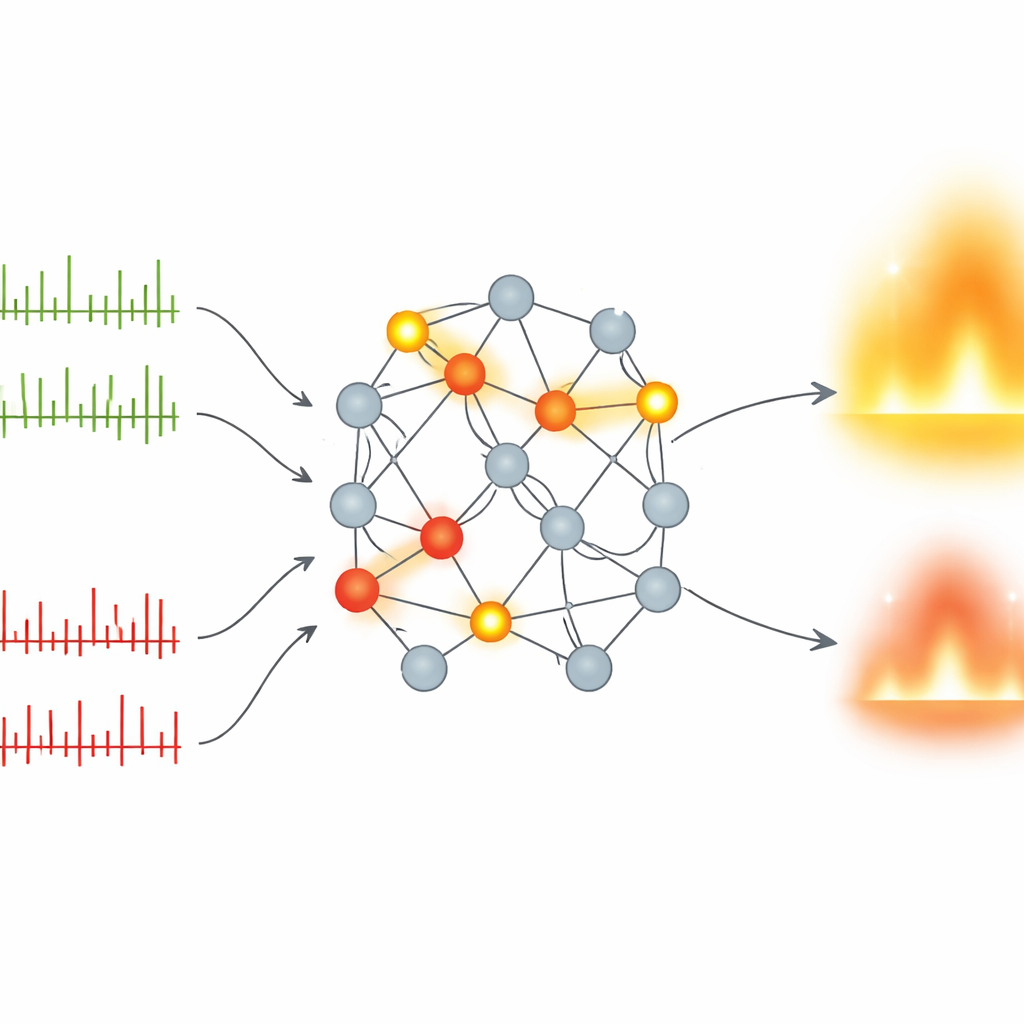
Bu Dikenli Yöntem Ne Kadar İyi?
Yaklaşımı test etmek için yazarlar, el yazısı rakamlar (MNIST), moda ürünleri, Japon karakterleri ve renkli nesne görüntüleri (CIFAR-10) gibi bir dizi standart görsel benchmark üzerinde kompakt dikenli ağlar eğitir; ayrıca girişlerin zaten dikenler halinde geldiği nöromorfik veri setleri—olay tabanlı rakam kayıtları (N-MNIST) ve diken dizileri olarak kodlanmış konuşulan rakamlar (SHD) gibi—kullanılır. Yalnızca iki gizli katman ve en az 10 zaman adımı kullanmalarına rağmen, ileri–ileri dikenli modelleri diğer ileri–ileri dikenli sistemlerle eşleşir veya onları aşar ve geri yayılma ile eğitilmiş en iyi dikenli ağlara yaklaşır. SHD gibi daha zorlu zamansal görevlerde yöntemleri bazı geri yayılma tabanlı dikenli modelleri bile geride bırakır; tüm bunlar daha az parametre kullanırken olaya dayalı donanımlara daha kolay eşlenebilir olmalarını sağlar.
Geleceğin Beyin Benzeri Makineleri İçin Anlamı
Gayri uzman bir okuyucu için kilit mesaj şudur: geri yayılmanın ağır mekanizmasına dayanmadan beyin ilhamlı, diken tabanlı ağları eğitmenin umut verici bir yolu artık mevcut. Her katmanı iyi ve kötü örneklere karşı ne kadar güçlü yanıt verdiğine göre değerlendirip, öğrenmeyi tamamen ileri geçişlerle yürütmek, ileri–ileri yaklaşımının öğrenmeyi yerel ve modüler tutmasını sağlarken rekabetçi doğruluk elde etmesine olanak tanır. Surrogate gradyanlar ve açık etiket gömme gibi bazı bileşenler katı anlamda biyolojik olmasa da, bu çerçeve makine öğrenimini gerçek sinir sistemlerinin nasıl uyum sağladığına bir adım daha yaklaştırıyor ve akış halindeki duyusal verilerden gerçek zamanlı öğrenen, daha verimli düşük güçlü aygıtlara giden yolu açıyor.
Atıf: Ghader, M., Kheradpisheh, S.R., Farahani, B. et al. Backpropagation-free spiking neural networks with the forward–forward algorithm. Sci Rep 16, 14294 (2026). https://doi.org/10.1038/s41598-026-41671-4
Anahtar kelimeler: dikenli sinir ağları, ileri-ileri öğrenme, nöromorfik hesaplama, biyolojik ilhamlı yapay zekâ, geri yayılma alternatifleri