Clear Sky Science · tr
Yenilikçi bir tekrar oynatma yöntemi kullanarak dağıtım ağı yeniden yapılandırmasında derin pekiştirmeli öğrenme algoritmalarının öğrenme sürecinin hızlandırılması
Günlük Hayat İçin Daha Akıllı Elektrik Şebekeleri
Elektrik birçok yerde o kadar güvenilir ki evimize ve iş yerlerimize nasıl ulaştığını neredeyse düşünmüyoruz. Oysa perde arkasında, enerji şirketleri enerjiyi mümkün olduğunca az kayıpla iletmek için hangi hatların aktif olacağını sürekli düzenliyor. Bu makale, yapay zekâ tabanlı bir sistemin yerel enerji ağlarını kayıpları azaltmak, gerilimleri sağlıklı tutmak ve güneş enerjisi ile günlük talep dalgalanmaları gibi değişen koşullara hızlı yanıt vermek amacıyla kendi başına nasıl yeniden yapılandırmayı öğrenebileceğini keşfediyor.
Elektrik Hatlarının Daha İyi Bir Stratejiye Neden İhtiyacı Var
Tipik bir dağıtım şebekesinde elektrik, bir trafo merkezinden binlerce müşteriye hatlar ve anahtarlar ağı aracılığıyla akar. Bazı anahtarlar normale göre kapalıdır, bazıları ise açık tutulur; böylece hatların genel düzeni ağ yerine ağaç biçiminde görünür, bu da ekipmanı korumaya ve işletmeyi basitleştirmeye yardımcı olur. Zaman içinde mühendisler, hangi anahtarların açık veya kapalı olması gerektiğini belirlemek için enerji kaybını en aza indirip gerilimleri güvenli sınırlar içinde tutan birçok matematiksel ve doğadan ilham alan akıllı algoritma geliştirdiler. Bu yöntemler işe yarıyor, ancak sıklıkla ayrıntılı modellere dayanıyor, önemli hesaplama zamanı gerektirebiliyor ve koşullar değiştiğinde yeniden çalıştırılmaları gerekiyor.
Bir Yapay Zekâ Ajanının Deneme Yanılma ile Öğrenmesine İzin Vermek
Yazarlar bunun yerine şebekeyi bir derin pekiştirmeli öğrenme ajanı için öğrenme oyun alanı gibi ele alıyor; bu, deneme yanılma yoluyla gelişen bir yapay zekâ türü. Her adımda ajan, şebekenin güncel durumuna bakıyor: tüm düğümlerdeki gerilimler ve her hattın durumu. Ardından her döngüde hangi hattın açılacağını seçiyor ve toplam enerji kaybı ile herhangi bir gerilimin ideal değerinden ne kadar sapmış olduğuna göre bir puan alıyor. Çok sayıda simüle edilmiş bölüm (episode) boyunca ajan, güç akışının temel denklemleri kendisine öğretilmeden hangi anahtar kombinasyonlarının genellikle düşük kayıp ve kararlı gerilimler ürettiğini kademeli olarak öğreniyor.
Büyük Bir Bulmacayı Döngülere Bölmek
Büyük bir engel, gerçek bir dağıtım şebekesindeki olası anahtar ayarlarının sayısının muazzam oluşudur; hatlar arttıkça eylem sayısı patlar. Bunu ele almak için makale döngü tabanlı bir strateji sunuyor. Tüm hatlar arasından tek bir dev karar vericinin seçmesi yerine ağ döngülere ayrılıyor. Her döngüye yalnızca o döngü içindeki hangi hattın açılacağını seçmekten sorumlu özel bir öğrenme ağı atanıyor. Yazarlar, bir döngünün diğer bir döngüyle paylaşılan bir hat seçtiğinde, sonraki döngülerin o hattı otomatik olarak kullanılamaz sayması için olağan öğrenme kurallarını değiştiriyor. Bu koordinasyon, her öğrenenin karar alanını yönetilebilir tutarken şebekenin fiziksel kısıtlamalarına uyulmasını sağlıyor.
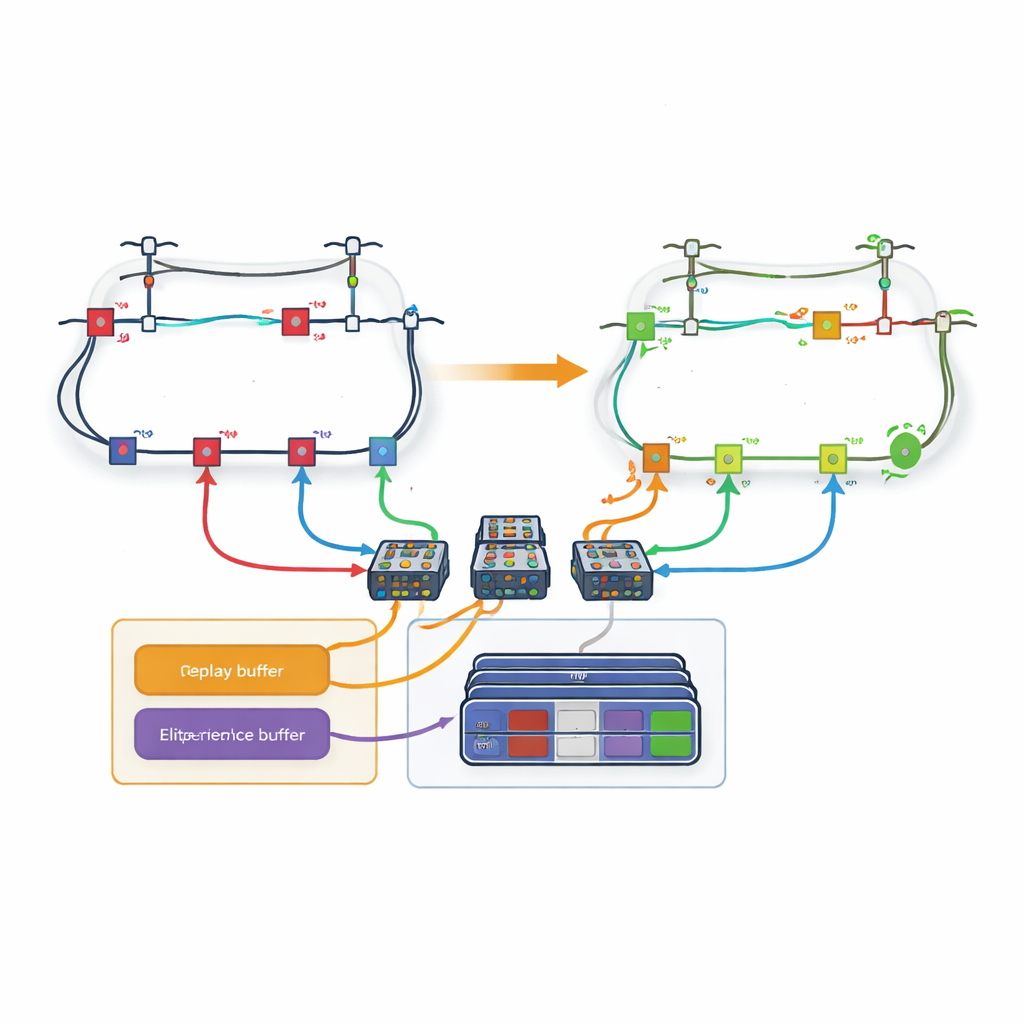
Sadece En Değerli Deneyimleri Hatırlamak
Döngüler olsa bile geçmiş her deneyim eşit muamele görürse öğrenme yavaş olabilir. Bu nedenle yazarlar yeni bir "kayıp-tabanlı deneyim tekrar oynatma" mekanizması tasarlıyor. Eğitim sırasında ajan, tamamlanmış bölümleri—eylem dizileri ve ortaya çıkan şebeke durumlarının tam sıralarını—hafızaya kaydediyor. Her bölümden sonra nihai güç kaybı, şimdiye kadar görülen en iyi deneyimlerle karşılaştırılıyor. Sadece en iyi birkaç yüzdeye giren bölümler özel bir arabelleğe kopyalanıyor. Ajan sinir ağlarını eğitirken bazı örnekleri bu seçkin kümeden, bazılarını ise sıradan deneyimden çekiyor; böylece umut verici desenlere odaklanma ile yanlılıktan kaçınma arasında bir denge kuruluyor. Bu hedeflenmiş tekrar oynatma ajanın yüksek kaliteli stratejilere daha hızlı yakınsamasına yardımcı oluyor.
Fikir Gerçekçi Test Şebekelerinde Kanıtlanıyor
Araştırmacılar yaklaşımı 33, 69 ve 119 düğümlü üç iyi bilinen kıyaslama sistemi üzerinde test ediyor; bunlar arasında çatı tipi güneş panelleri ve tam bir gün boyunca değişen talep içeren versiyonlar bulunuyor. Yeni tekrar arabelleği olan ve olmayan çeşitli derin öğrenme varyantlarını önceki yapay zekâ ve matematiksel yöntemlerle karşılaştırıyorlar. Tüm şebekelerde, kayıp-odaklı tekrar kullanan döngü tabanlı ajanlar, basit muadillerine kıyasla tutarlı şekilde daha fazla güç kaybı azaltıyor ve en iyi mevcut tekniklerle eşleşiyor veya onları geçiyor. Ayrıca eğitim tamamlandıktan sonra rekabetçi veya daha iyi hesaplama süreleri sunuyorlar; bu, gerçek zamanlı veya sık yeniden yapılandırma için kritik önemde.
Geleceğin Şebekeleri İçin Anlamı
Basitçe ifade etmek gerekirse, çalışma dikkatle tasarlanmış bir öğrenme sisteminin, güneş enerjisi ve talep gün içinde değişse bile elektriğin daha verimli akması ve güvenli sınırlar içinde kalması için şebekenin "yollarını" nasıl yeniden düzenleyeceğini kendi kendine öğretebileceğini gösteriyor. Problemi döngülere bölüp geçmişteki en başarılı deneyimler üzerinde eğiterek yöntem kaba basitleştirmelerden kaçınıyor ve öğrenmeyi pratik tutuyor. Çok büyük şebekeler için eğitim hâlâ zaman alıyor olsa da bu yaklaşım, akıllı ajanların arka planda anahtar ayarlarını sürekli ince ayar yaptığı, kayıpları azaltan, yenilenebilir enerjiyi destekleyen ve elektrikimizi daha güvenilir ve ekonomik yapan gelecekteki dağıtım sistemlerine işaret ediyor.
Atıf: Ghaemipour, A., Mashhadi, H.R. & Mostafavi, S.H. Accelerating the learning process of deep reinforcement learning algorithms in distribution network reconfiguration using an innovative replay method. Sci Rep 16, 12660 (2026). https://doi.org/10.1038/s41598-026-40508-4
Anahtar kelimeler: enerji dağıtımı, akıllı şebeke, pekiştirmeli öğrenme, ağ optimizasyonu, güneş entegrasyonu