Clear Sky Science · it
Accelerare il processo di apprendimento di algoritmi di deep reinforcement learning nella riconfigurazione delle reti di distribuzione usando un metodo innovativo di replay
Reti elettriche più intelligenti per la vita quotidiana
L’elettricità è così affidabile in molti luoghi che difficilmente pensiamo a come raggiunga le nostre case e i nostri posti di lavoro. Eppure dietro le quinte le compagnie elettriche gestiscono costantemente quali linee sono attive per fornire energia con il minor spreco possibile. Questo articolo esplora un nuovo modo per consentire a un sistema di intelligenza artificiale di apprendere, autonomamente, come riconfigurare le reti elettriche locali per ridurre le perdite, mantenere le tensioni entro limiti sani e reagire rapidamente a condizioni variabili come il solare e le oscillazioni della domanda giornaliera.
Perché le linee elettriche hanno bisogno di un piano migliore
In una rete di distribuzione tipica, l’elettricità fluisce da una cabina di trasformazione attraverso una rete di linee e interruttori fino a migliaia di clienti. Alcuni interruttori sono normalmente chiusi, altri sono tenuti aperti in modo che lo schema complessivo delle linee assomigli a un albero piuttosto che a una maglia, cosa che aiuta a proteggere le apparecchiature e semplifica l’esercizio. Nel tempo gli ingegneri hanno progettato molti algoritmi matematici e ispirati alla natura per decidere quali interruttori debbano essere aperti o chiusi per minimizzare le perdite di energia e mantenere le tensioni entro limiti sicuri. Questi metodi funzionano, ma spesso si basano su modelli dettagliati, possono richiedere tempi di calcolo notevoli e devono essere rieseguiti ogni volta che cambiano le condizioni.
Lasciare che un agente IA impari per tentativi ed errori
Gli autori trattano invece la rete come un ambiente di apprendimento per un agente di deep reinforcement learning, un tipo di IA che migliora tramite tentativi ed errori. A ogni passo l’agente osserva lo stato attuale della rete: le tensioni a tutti i nodi e lo stato di ogni linea. Decide quindi quale linea aprire in ciascun anello della rete e riceve un punteggio basato su quanta potenza totale viene persa e su quanto ogni tensione si discosti dal valore ideale. Nel corso di molti episodi simulati, l’agente impara gradualmente quali combinazioni di posizioni degli interruttori tendono a produrre basse perdite e tensioni stabili, senza mai essere istruito sulle equazioni sottostanti del flusso di potenza.
Spezzare un grande puzzle in anelli
Un ostacolo importante è il numero enorme di possibili configurazioni degli interruttori in una rete di distribuzione reale; il numero di azioni esplode all’aumentare delle linee. Per affrontare questo problema l’articolo introduce una strategia basata sugli anelli. Invece di avere un unico decisore che sceglie tra tutte le linee contemporaneamente, la rete viene scomposta in anelli. A ciascun anello viene assegnata una rete di apprendimento dedicata responsabile solo di decidere quale linea aprire all’interno di quell’anello. Gli autori modificano le regole di apprendimento usuali in modo che quando un anello sceglie una linea condivisa con un altro anello, gli anelli successivi considerino automaticamente quella linea non disponibile. Questa coordinazione permette al sistema di rispettare i vincoli fisici della rete mantenendo lo spazio decisionale di ogni apprendente gestibile.
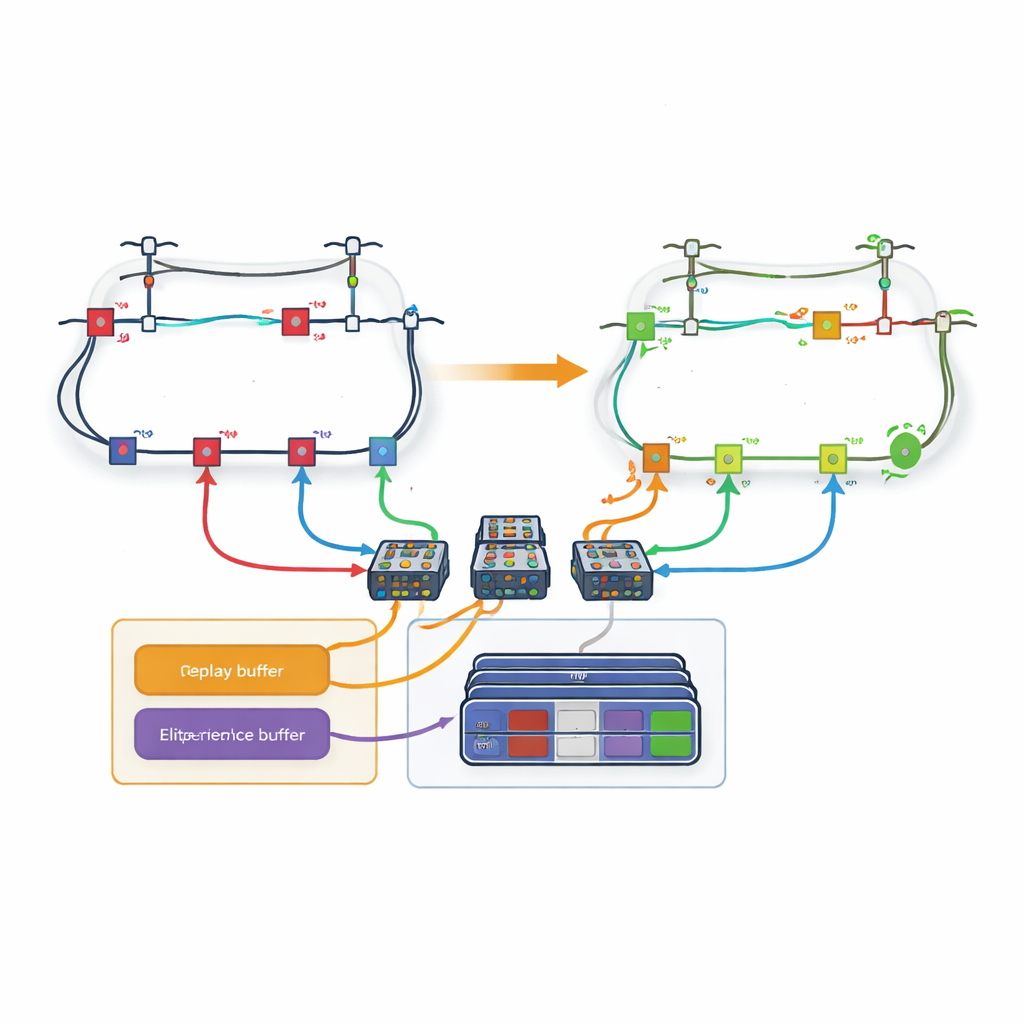
Memorizzare solo le esperienze più preziose
Anche con la suddivisione in anelli, l’apprendimento può essere lento se ogni esperienza passata viene trattata allo stesso modo. Gli autori propongono quindi un nuovo meccanismo di “replay delle esperienze basato sulla perdita”. Durante l’addestramento, l’agente conserva interi episodi—sequenze complete di azioni e stati risultanti della rete—in memoria. Dopo ogni episodio, la perdita di potenza finale viene confrontata con le migliori esperienze osservate finora. Solo gli episodi che rientrano nei primi pochi percentili vengono copiati in un buffer speciale. Quando l’agente addestra le sue reti neurali, pesca alcuni esempi da questo insieme d’élite e alcuni dall’esperienza ordinaria, trovando un equilibrio tra il concentrarsi sui modelli promettenti e l’evitare bias. Questo replay mirato aiuta l’agente a convergere più rapidamente verso strategie di alta qualità.
Dimostrare l’idea su reti di prova realistiche
I ricercatori testano l’approccio su tre sistemi di riferimento noti con 33, 69 e 119 nodi, incluse versioni con pannelli solari sui tetti e domanda variabile nel corso di un’intera giornata. Confrontano diverse varianti di deep learning—con e senza il nuovo buffer di replay—contro metodi precedenti di intelligenza artificiale e matematici. Su tutte le reti, gli agenti basati sugli anelli che usano il replay orientato alle perdite riducono costantemente le perdite di potenza più delle controparti semplici e eguagliano o superano le migliori tecniche esistenti. Inoltre lo fanno con tempi di calcolo competitivi o migliori una volta completato l’addestramento, aspetto cruciale per riconfigurazioni in tempo reale o frequenti.
Cosa significa questo per le reti future
In termini semplici, lo studio mostra che un sistema di apprendimento progettato con cura può insegnare a sé stesso come riorganizzare le “strade” della rete elettrica in modo che l’elettricità viaggi con maggiore efficienza e rimanga entro limiti di sicurezza, anche quando il solare e la domanda cambiano nel corso della giornata. Suddividendo il problema in anelli e addestrando l’agente sulle esperienze passate più riuscite, il metodo evita semplificazioni grossolane mantenendo al contempo l’apprendimento praticabile. Sebbene l’addestramento richieda ancora tempo per reti molto grandi, questo approccio apre la strada a sistemi di distribuzione futuri in cui agenti intelligenti ottimizzano continuamente in background le impostazioni degli interruttori, riducendo le perdite, supportando le rinnovabili e rendendo l’energia più affidabile ed economica.
Citazione: Ghaemipour, A., Mashhadi, H.R. & Mostafavi, S.H. Accelerating the learning process of deep reinforcement learning algorithms in distribution network reconfiguration using an innovative replay method. Sci Rep 16, 12660 (2026). https://doi.org/10.1038/s41598-026-40508-4
Parole chiave: distribuzione di energia, rete intelligente, apprendimento per rinforzo, ottimizzazione di rete, integrazione solare