Clear Sky Science · es
Aceleración del proceso de aprendizaje de algoritmos de aprendizaje por refuerzo profundo en la reconfiguración de redes de distribución mediante un método innovador de repetición
Redes eléctricas más inteligentes para la vida cotidiana
La electricidad es tan fiable en muchos lugares que apenas pensamos en cómo llega a nuestros hogares y centros de trabajo. Sin embargo, entre bastidores, las compañías eléctricas gestionan constantemente qué líneas están activas para entregar energía con el menor desperdicio posible. Este artículo explora una nueva forma de permitir que un sistema de inteligencia artificial aprenda, por sí solo, cómo reconfigurar redes eléctricas locales para reducir pérdidas, mantener tensiones saludables y reaccionar rápidamente a condiciones cambiantes como la energía solar y las oscilaciones diarias de la demanda.
Por qué las líneas eléctricas necesitan una mejor estrategia
En una red de distribución típica, la electricidad fluye desde una subestación a través de una red de líneas e interruptores hasta miles de clientes. Algunos interruptores están normalmente cerrados, otros se mantienen abiertos para que el patrón general de líneas tenga forma de árbol en lugar de malla, lo que ayuda a proteger el equipo y simplifica la operación. Con el tiempo, los ingenieros han diseñado muchos algoritmos ingeniosos, matemáticos e inspirados en la naturaleza, para decidir qué interruptores deben abrirse o cerrarse para minimizar la pérdida de energía y mantener las tensiones dentro de límites seguros. Estos métodos funcionan, pero a menudo dependen de modelos detallados, pueden requerir un tiempo de cálculo considerable y deben ejecutarse de nuevo cada vez que cambian las condiciones.
Dejar que un agente de IA aprenda por ensayo y error
Los autores, en cambio, tratan la red como un campo de aprendizaje para un agente de aprendizaje por refuerzo profundo, un tipo de IA que mejora mediante ensayo y error. En cada paso, el agente observa la salud actual de la red: las tensiones en todas las barras y el estado de cada línea. Luego elige qué línea abrir en cada lazo de la red y recibe una puntuación basada en cuánto se pierde de potencia total y cuánto se desvía cualquier tensión de su valor ideal. A lo largo de muchos episodios simulados, el agente va descubriendo gradualmente qué combinaciones de posiciones de interruptores tienden a producir bajas pérdidas y tensiones estables, sin que nunca se le indiquen las ecuaciones subyacentes del flujo de potencia.
Dividir un gran rompecabezas en lazos
Un obstáculo importante es la enorme cantidad de posibles configuraciones de interruptores en una red de distribución real; el número de acciones se dispara a medida que se añaden más líneas. Para abordar esto, el artículo introduce una estrategia basada en lazos. En lugar de tener un único tomador de decisiones gigante que elija entre todas las líneas a la vez, la red se descompone en lazos. A cada lazo se le asigna una red de aprendizaje dedicada y es responsable solo de decidir qué línea abrir dentro de ese lazo. Los autores modifican las reglas habituales de aprendizaje de modo que, cuando un lazo elige una línea que se comparte con otro lazo, los lazos posteriores tratan automáticamente esa línea como no disponible. Esta coordinación permite al sistema respetar las restricciones físicas de la red mientras mantiene manejable el espacio de decisión de cada aprendiz.
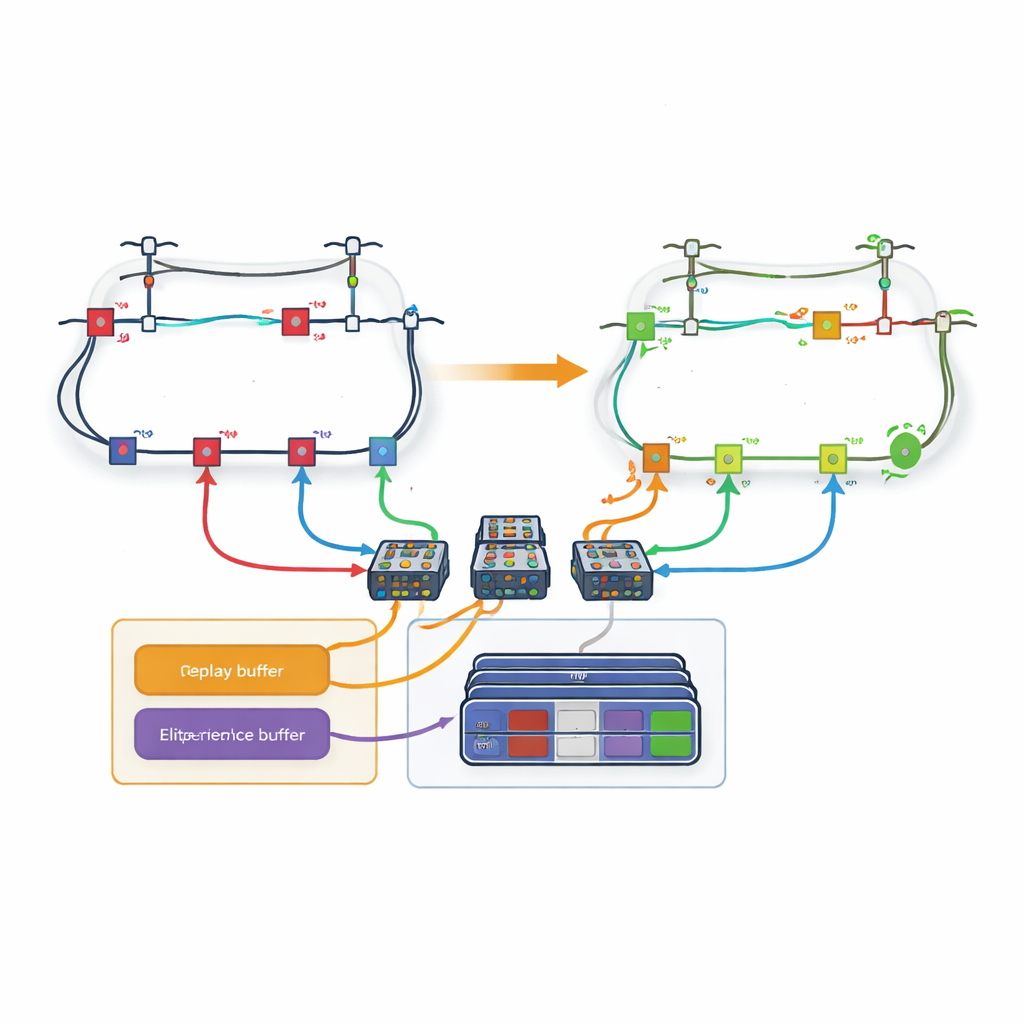
Recordar solo las experiencias más valiosas
Aun con lazos, el aprendizaje puede ser lento si todas las experiencias pasadas se tratan por igual. Por ello, los autores diseñan un nuevo mecanismo de “repetición de experiencias basada en la pérdida”. Durante el entrenamiento, el agente almacena episodios completos—secuencias completas de acciones y estados resultantes de la red—en memoria. Tras cada episodio, la pérdida de potencia final se compara con las mejores experiencias vistas hasta el momento. Solo los episodios que quedan en el porcentaje más alto se copian en un búfer especial. Cuando el agente entrena sus redes neuronales, extrae algunos ejemplos de este conjunto de élite y otros de la experiencia ordinaria, logrando un equilibrio entre centrarse en patrones prometedores y evitar sesgos. Esta repetición dirigida ayuda al agente a converger más rápido hacia estrategias de alta calidad.
Demostrar la idea en redes de prueba realistas
Los investigadores prueban su enfoque en tres sistemas de referencia bien conocidos con 33, 69 y 119 barras, incluidas versiones con paneles solares en tejados y demanda variable a lo largo de un día completo. Comparan varias variantes de aprendizaje profundo—con y sin el nuevo búfer de repetición—frente a métodos previos, tanto de IA como matemáticos. En todas las redes, los agentes basados en lazos que usan la repetición centrada en la pérdida reducen consistentemente las pérdidas de potencia más que sus homólogos simples y igualan o superan las mejores técnicas existentes. También lo hacen con tiempos de cálculo competitivos o mejores una vez completado el entrenamiento, lo cual es crucial para reconfiguraciones en tiempo real o frecuentes.
Qué significa esto para las redes del futuro
En términos sencillos, el estudio muestra que un sistema de aprendizaje cuidadosamente diseñado puede aprender por sí mismo cómo reorganizar las “rutas” de la red eléctrica para que la electricidad viaje con mayor eficiencia y se mantenga dentro de límites seguros, incluso cuando la energía solar y la demanda cambian a lo largo del día. Al dividir el problema en lazos y entrenar con las experiencias pasadas más exitosas, el método evita simplificaciones groseras mientras mantiene el aprendizaje práctico. Aunque el entrenamiento todavía requiere tiempo en redes muy grandes, este enfoque apunta hacia sistemas de distribución futuros donde agentes inteligentes afinan continuamente las posiciones de los interruptores en segundo plano, recortando pérdidas, apoyando las energías renovables y haciendo nuestra electricidad más fiable y económica de forma discreta.
Cita: Ghaemipour, A., Mashhadi, H.R. & Mostafavi, S.H. Accelerating the learning process of deep reinforcement learning algorithms in distribution network reconfiguration using an innovative replay method. Sci Rep 16, 12660 (2026). https://doi.org/10.1038/s41598-026-40508-4
Palabras clave: distribución de energía, red inteligente, aprendizaje por refuerzo, optimización de redes, integración solar