Clear Sky Science · de
Beschleunigung des Lernprozesses von Deep-Reinforcement-Learning-Algorithmen zur Rekonfiguration von Verteilnetzen durch eine innovative Replay-Methode
Intelligentere Stromnetze für den Alltag
In vielen Regionen ist Strom so verlässlich, dass wir kaum darüber nachdenken, wie er in unsere Häuser und Arbeitsstätten gelangt. Hinter den Kulissen jonglieren Versorgungsunternehmen jedoch ständig damit, welche Leitungen aktiv sind, um Energie mit möglichst wenig Verlust zu liefern. Dieses Papier untersucht eine neue Methode, mit der sich ein künstliches Intelligenzsystem selbst beibringen kann, lokale Stromnetze so umzuschalten, dass Verluste reduziert, Spannungen im gesunden Bereich gehalten und schnelle Reaktionen auf veränderliche Bedingungen wie Solarerzeugung und tägliche Lastschwankungen ermöglicht werden.
Warum Stromleitungen einen besseren Plan brauchen
In einem typischen Verteilnetz fließt der Strom von einer Umspanneinrichtung durch ein Geflecht von Leitungen und Schaltern zu tausenden Kunden. Einige Schalter sind normalerweise geschlossen, andere offen, sodass das Gesamtnetz eher wie ein Baum als wie ein Netz aussieht — das schützt Geräte und vereinfacht den Betrieb. Im Laufe der Zeit haben Ingenieure viele clevere mathematische und naturinspirierte Algorithmen entwickelt, um zu entscheiden, welche Schalter offen oder geschlossen sein sollten, um Energieverluste zu minimieren und Spannungen innerhalb sicherer Grenzen zu halten. Diese Methoden funktionieren, stützen sich jedoch oft auf detaillierte Modelle, können erhebliche Rechenzeit erfordern und müssen bei geänderten Bedingungen erneut ausgeführt werden.
Ein KI-Agent lernt durch Versuch und Irrtum
Die Autorinnen und Autoren behandeln das Netz stattdessen wie einen Lernspielplatz für einen Deep-Reinforcement-Learning-Agenten, eine Form der KI, die sich durch Versuch und Irrtum verbessert. In jedem Schritt betrachtet der Agent die aktuelle Netzwerkgesundheit: die Spannungen an allen Knotenpunkten und den Zustand jeder Leitung. Anschließend wählt er aus, welche Leitung in jeder Schleife des Netzes geöffnet werden soll, und erhält eine Bewertung basierend auf dem gesamten Leistungsverlust und davon, wie weit einzelne Spannungen vom Idealwert abweichen. Über viele simulierte Episoden hinweg findet der Agent allmählich heraus, welche Kombinationen von Schalterstellungen tendenziell zu niedrigen Verlusten und stabilen Spannungen führen, ohne jemals die zugrunde liegenden Leistungsfluss-Gleichungen vorgegeben zu bekommen.
Ein großes Problem in Schleifen zerlegen
Ein großes Hindernis ist die schiere Zahl möglicher Schalterstellungen in einem realen Verteilnetz; die Anzahl der Aktionen explodiert, je mehr Leitungen hinzukommen. Um dem zu begegnen, führt das Papier eine schleifenbasierte Strategie ein. Anstatt einen einzigen großen Entscheider über alle Leitungen gleichzeitig entscheiden zu lassen, wird das Netz in Schleifen zerlegt. Ein spezielles Lernnetzwerk übernimmt jede Schleife und ist nur dafür verantwortlich, zu entscheiden, welche Leitung innerhalb dieser Schleife geöffnet werden soll. Die Autorinnen und Autoren modifizieren die üblichen Lernregeln so, dass, wenn eine Schleife eine Leitung wählt, die mit einer anderen Schleife geteilt wird, die nachfolgenden Schleifen diese Leitung automatisch als nicht verfügbar behandeln. Diese Koordination erlaubt es dem System, die physikalischen Beschränkungen des Netzes zu respektieren und zugleich den Entscheidungsraum jedes Lerners handhabbar zu halten.
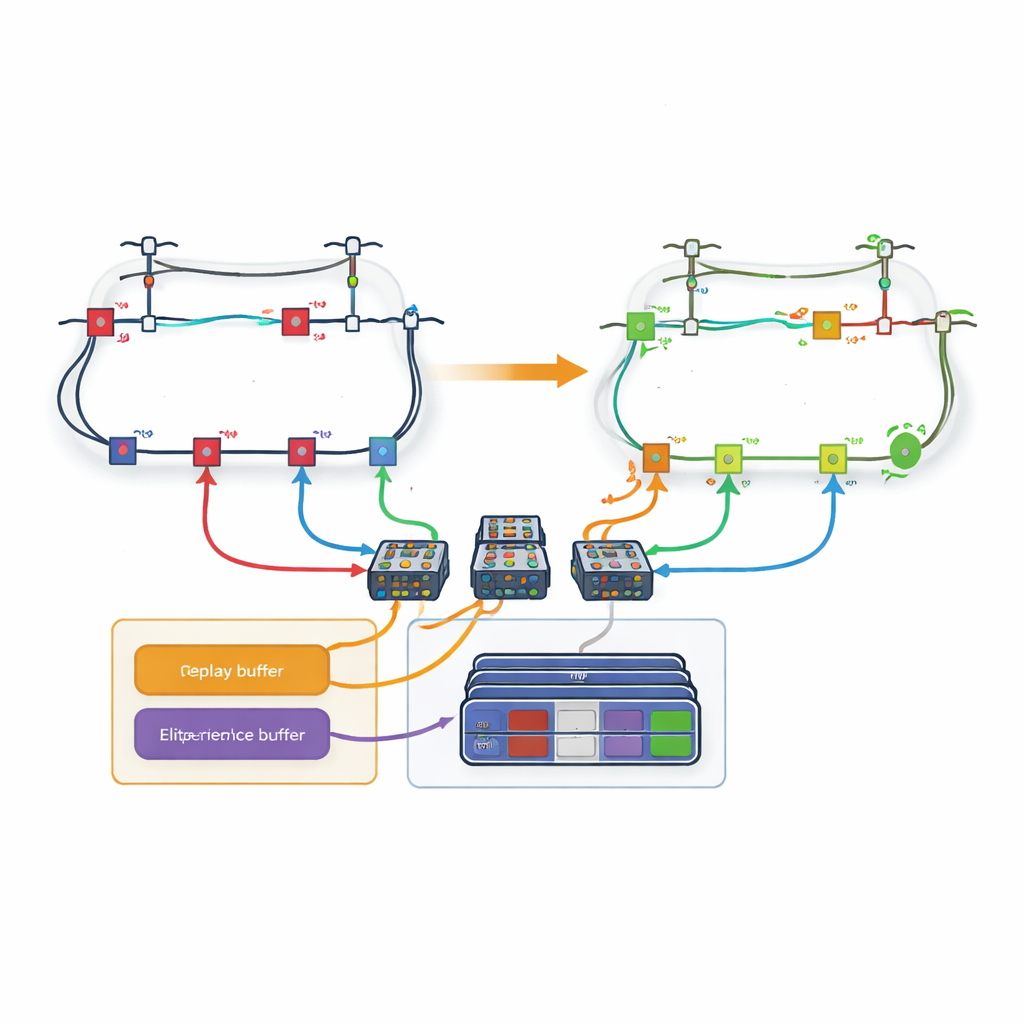
Nur die wertvollsten Erfahrungen merken
Selbst mit Schleifen kann das Lernen langsam verlaufen, wenn jede vergangene Erfahrung gleich behandelt wird. Daher entwerfen die Autorinnen und Autoren einen neuen „verlustbasierten Experience Replay“-Mechanismus. Während des Trainings speichert der Agent ganze Episoden — vollständige Aktionssequenzen und resultierende Netz-Zustände — im Speicher. Nach jeder Episode wird der finale Leistungsverlust mit den besten bisher gesehenen Erfahrungen verglichen. Nur die Episoden, die zu den obersten wenigen Prozent gehören, werden in einen speziellen Puffer kopiert. Wenn der Agent seine neuronalen Netze trainiert, entnimmt er einige Beispiele aus diesem Elite-Set und einige aus der gewöhnlichen Erfahrung, sodass ein Gleichgewicht zwischen dem Fokussieren auf vielversprechende Muster und dem Vermeiden von Verzerrungen entsteht. Dieses zielgerichtete Replay hilft dem Agenten, schneller zu hochwertigen Strategien zu konvergieren.
Die Idee an realistischen Testnetzen beweisen
Die Forschenden testen ihren Ansatz an drei bekannten Benchmark-Systemen mit 33, 69 und 119 Knoten, einschließlich Varianten mit Photovoltaik auf Dächern und zeitlich variierender Nachfrage über einen ganzen Tag. Sie vergleichen mehrere Deep-Learning-Varianten — mit und ohne den neuen Replay-Puffer — gegenüber früheren KI- und mathematischen Methoden. In allen Netzen reduzieren die schleifenbasierten Agenten mit dem verlustfokussierten Replay konsequent die Leistungsverluste stärker als ihre einfachen Gegenstücke und erreichen oder übertreffen die besten vorhandenen Techniken. Außerdem tun sie dies mit konkurrenzfähigen oder besseren Rechenzeiten, sobald das Training abgeschlossen ist, was für Echtzeit- oder häufige Rekonfigurationen entscheidend ist.
Was das für zukünftige Netze bedeutet
Einfach ausgedrückt zeigt die Studie, dass ein sorgfältig gestaltetes Lernsystem sich selbst beibringen kann, wie es die „Straßen“ des Stromnetzes so umordnet, dass der Strom effizienter fließt und Spannungen innerhalb sicherer Grenzen bleiben, selbst wenn Solarstrom und Nachfrage im Tagesverlauf schwanken. Durch das Zerlegen des Problems in Schleifen und das Trainieren an den erfolgreichsten vergangenen Erfahrungen vermeidet die Methode grobe Vereinfachungen und hält das Lernen zugleich praktikabel. Obwohl das Training bei sehr großen Netzen weiterhin Zeit in Anspruch nimmt, weist dieser Ansatz in Richtung künftiger Verteilungsnetze, in denen intelligente Agenten im Hintergrund kontinuierlich Schalterstellungen feinjustieren, Verluste reduzieren, erneuerbare Energien unterstützen und unsere Stromversorgung still und effizient zuverlässiger machen.
Zitation: Ghaemipour, A., Mashhadi, H.R. & Mostafavi, S.H. Accelerating the learning process of deep reinforcement learning algorithms in distribution network reconfiguration using an innovative replay method. Sci Rep 16, 12660 (2026). https://doi.org/10.1038/s41598-026-40508-4
Schlüsselwörter: Stromverteilung, Smart Grid, Reinforcement Learning, Netzwerkoptimierung, Solarintegration