Clear Sky Science · en
Accelerating the learning process of deep reinforcement learning algorithms in distribution network reconfiguration using an innovative replay method
Smarter Power Grids for Everyday Life
Electricity is so reliable in many places that we barely think about how it reaches our homes and workplaces. Yet behind the scenes, power companies constantly juggle which lines are active so they can deliver energy with as little waste as possible. This paper explores a new way to let an artificial intelligence system learn, by itself, how to reconfigure local power networks to cut losses, keep voltages healthy, and react quickly to changing conditions such as solar power and daily demand swings.
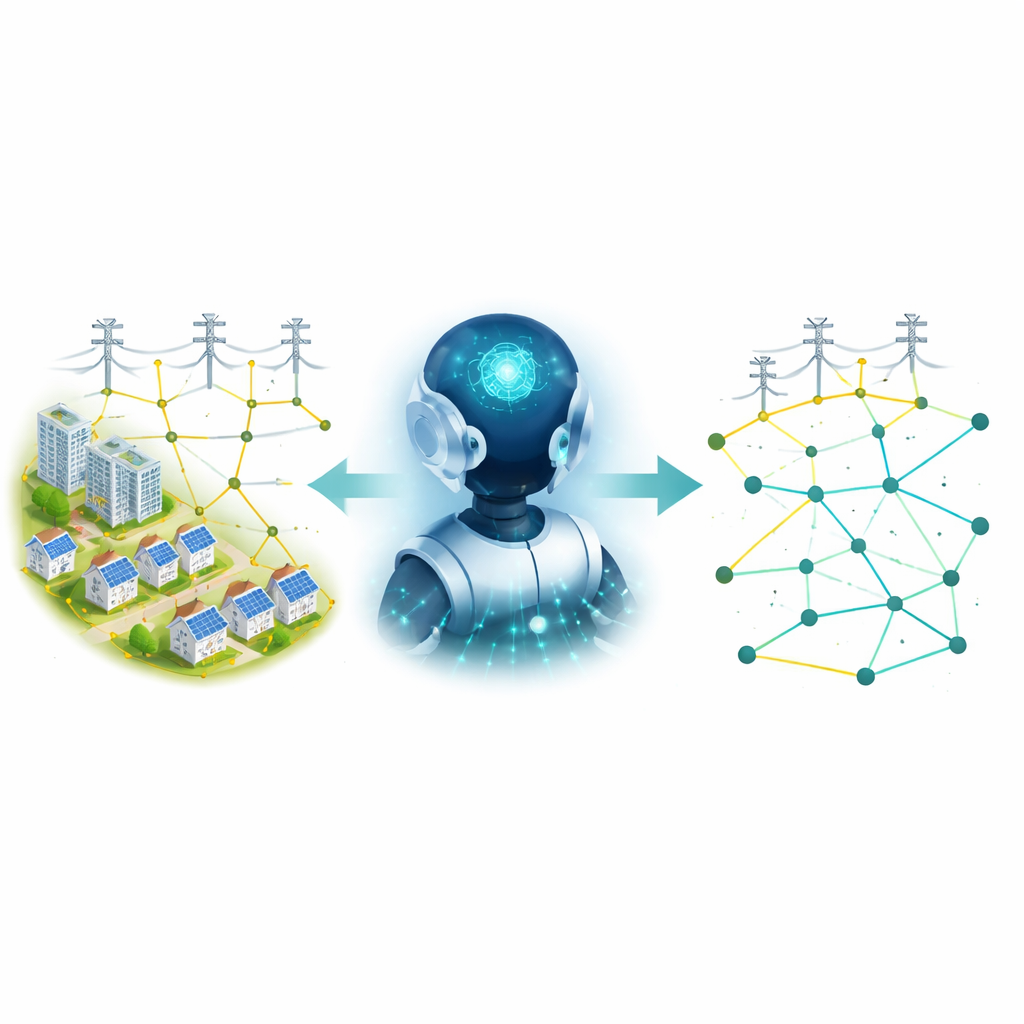
Why Power Lines Need a Better Game Plan
In a typical distribution network, electricity flows from a substation through a web of lines and switches to thousands of customers. Some switches are normally closed, others are kept open so the overall pattern of lines looks like a tree rather than a mesh, which helps protect equipment and simplifies operation. Over time, engineers have designed many clever mathematical and nature-inspired algorithms to decide which switches should be open or closed to minimize energy loss and keep voltages within safe limits. These methods work, but they often rely on detailed models, can take substantial computing time, and need to be rerun whenever conditions change.
Letting an AI Agent Learn by Trial and Error
The authors instead treat the grid like a learning playground for a deep reinforcement learning agent, a kind of AI that improves through trial and error. At every step, the agent looks at the current health of the network: the voltages at all buses and the status of every line. It then chooses which line to open in each loop of the network and receives a score based on how much total power is lost and how far any voltage strays from its ideal value. Over many simulated episodes, the agent gradually figures out which combinations of switch positions tend to produce low losses and stable voltages, without ever being told the underlying equations of power flow.
Breaking a Big Puzzle into Loops
A major obstacle is the sheer number of possible switch settings in a real distribution network; the number of actions explodes as more lines are added. To tackle this, the paper introduces a loop-based strategy. Instead of having one giant decision maker choose among all lines at once, the network is decomposed into loops. A dedicated learning network is assigned to each loop and is responsible only for deciding which line to open inside that loop. The authors modify the usual learning rules so that when one loop chooses a line that is shared with another loop, the later loops automatically treat that line as unavailable. This coordination allows the system to respect the physical constraints of the grid while keeping each learner’s decision space manageable.
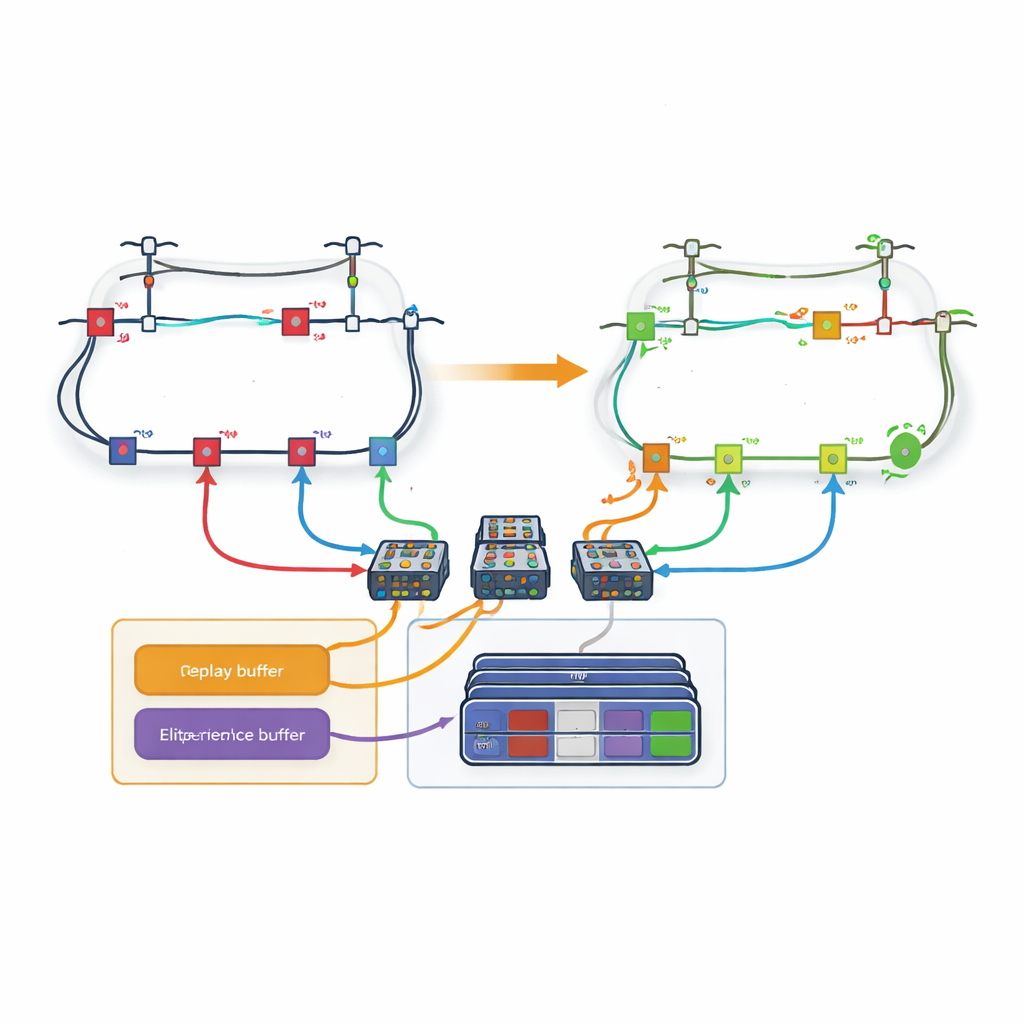
Remembering Only the Most Valuable Experiences
Even with loops, learning can be slow if every past experience is treated equally. The authors therefore design a new “loss-based experience replay” mechanism. During training, the agent stores whole episodes—complete sequences of actions and resulting grid states—in memory. After each episode, the final power loss is compared with the best experiences seen so far. Only the episodes that land in the top few percent are copied into a special buffer. When the agent trains its neural networks, it draws some examples from this elite set and some from ordinary experience, striking a balance between focusing on promising patterns and avoiding bias. This targeted replay helps the agent converge faster to high-quality strategies.
Proving the Idea on Realistic Test Networks
The researchers test their approach on three well-known benchmark systems with 33, 69, and 119 buses, including versions with rooftop solar panels and time-varying demand over a full day. They compare several deep learning variants—with and without the new replay buffer—against earlier artificial intelligence and mathematical methods. Across all networks, the loop-based agents using the loss-focused replay consistently reduce power losses more than their plain counterparts and match or surpass the best existing techniques. They also do so with competitive or better computation times once training is complete, which is crucial for real-time or frequent reconfiguration.
What This Means for Future Grids
In simple terms, the study shows that a carefully designed learning system can teach itself how to rearrange the “roads” of the power grid so electricity travels more efficiently and stays within safe limits, even as solar power and demand change throughout the day. By breaking the problem into loops and training on the most successful past experiences, the method avoids crude simplifications while keeping learning practical. Although training still takes time for very large networks, this approach points toward future distribution systems where smart agents continuously fine-tune switch settings in the background, trimming losses, supporting renewable energy, and quietly making our power more reliable and economical.
Citation: Ghaemipour, A., Mashhadi, H.R. & Mostafavi, S.H. Accelerating the learning process of deep reinforcement learning algorithms in distribution network reconfiguration using an innovative replay method. Sci Rep 16, 12660 (2026). https://doi.org/10.1038/s41598-026-40508-4
Keywords: power distribution, smart grid, reinforcement learning, network optimization, solar integration