Clear Sky Science · ru
Ускорение процесса обучения алгоритмов глубокого обучения с подкреплением при реконфигурации распределительной сети с использованием инновационного метода повторного воспроизведения
Более умные энергосети для повседневной жизни
В многих местах электроэнергия настолько надежна, что мы почти не задумываемся о том, как она попадает в наши дома и офисы. Между тем энергетические компании постоянно управляют тем, какие линии активны, чтобы доставлять энергию с минимальными потерями. В этой работе рассматривается новый подход, позволяющий системе искусственного интеллекта самостоятельно научиться реконфигурировать локальные энергетические сети для сокращения потерь, поддержания допустимых уровней напряжения и быстрой реакции на изменяющиеся условия, такие как солнечная генерация и суточные колебания спроса.
Почему линиям электропередачи нужен лучший план действий
В типичной распределительной сети электричество течет от подстанции через сеть линий и выключателей к тысячам потребителей. Некоторые переключатели обычно закрыты, другие удерживаются открытыми, чтобы общая структура линий напоминала дерево, а не сетку — это защищает оборудование и упрощает эксплуатацию. Со временем инженеры разработали множество умных математических и натуралистических алгоритмов для выбора положения переключателей с целью минимизации потерь энергии и поддержания напряжения в безопасных границах. Эти методы работают, но часто опираются на детальные модели, могут требовать значительных вычислительных ресурсов и должны повторно запускаться при изменении условий.
Позволить агенту ИИ учиться методом проб и ошибок
Авторы рассматривают сеть как игровую площадку для агента глубокого обучения с подкреплением — вида ИИ, который улучшается через пробу и ошибку. На каждом шаге агент оценивает текущее состояние сети: напряжения на всех шинах и статус каждой линии. Затем он выбирает, какую линию открыть в каждом цикле сети, и получает оценку на основе суммарных потерь мощности и отклонений напряжения от идеального значения. За множество смоделированных эпизодов агент постепенно выясняет, какие комбинации положений переключателей, как правило, дают низкие потери и стабильные напряжения, не зная при этом уравнений, описывающих потоки мощности.
Разбиение большой задачи на петли
Крупным препятствием является огромное число возможных настроек переключателей в реальной распределительной сети; число действий растет взрывным образом с добавлением линий. Для преодоления этой проблемы в работе предложена стратегия, основанная на петлях. Вместо одного большого решающего модуля, выбирающего среди всех линий одновременно, сеть декомпозируется на петли. Каждой петле назначается собственная обучаемая сеть, отвечающая только за выбор, какую линию открыть внутри этой петли. Авторы модифицируют стандартные правила обучения так, что когда одна петля выбирает линию, общую с другой петлей, последующие петли автоматически рассматривают эту линию как недоступную. Такая координация позволяет системе учитывать физические ограничения сети, сохраняя управляемый объем пространства решений для каждого обучаемого модуля.
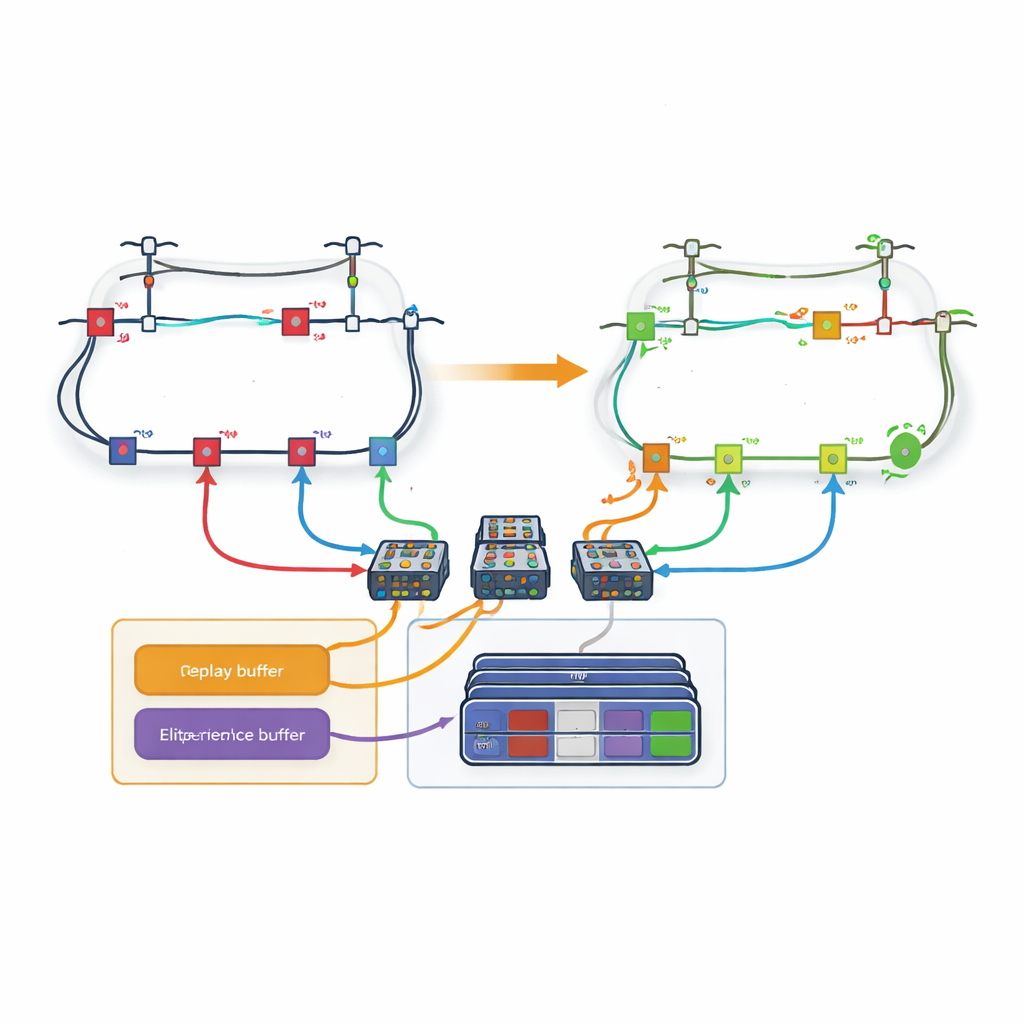
Запоминание только самых ценных опытов
Даже при разбиении на петли обучение может идти медленно, если к каждому прошлому опыту относятся одинаково. Поэтому авторы разработали новый механизм «повторного воспроизведения опыта на основе потерь». В процессе обучения агент сохраняет полные эпизоды — последовательности действий и полученных состояний сети — в памяти. По завершении эпизода итоговые потери мощности сравниваются с лучшими результатами, полученными ранее. В специальный буфер копируются только эпизоды, попавшие в верхние несколько процентов. При обучении нейронных сетей агент выбирает часть примеров из этого элитного набора и часть из обычного опыта, достигая баланса между фокусом на перспективных шаблонах и снижением смещения. Такое целенаправленное воспроизведение помогает агенту быстрее сходиться к качественным стратегиям.
Демонстрация идеи на реалистичных тестовых сетях
Исследователи протестировали свой подход на трех известных эталонных системах с 33, 69 и 119 шинами, включая варианты с солнечными панелями на крышах и изменяющимся во времени спросом в течение суток. Они сравнили несколько вариантов глубокого обучения — с новым буфером воспроизведения и без него — с ранними методами из области ИИ и математической оптимизации. Во всех сетях агенты, работающие по петлевому принципу и использующие воспроизведение, основанное на потерях, последовательно сокращали потери мощности больше, чем их упрощенные аналоги, и соответствовали или превосходили лучшие существующие техники. При этом по завершении обучения их вычислительные затраты были сопоставимы или лучше, что важно для реального времени или частой реконфигурации.
Что это значит для будущих сетей
Проще говоря, исследование показывает, что тщательно спроектированная система обучения может самостоятельно научиться перенастраивать «дороги» электросети так, чтобы электричество передавалось эффективнее и оставалось в пределах допустимых значений, даже при изменениях солнечной генерации и спроса в течение дня. Разбивая задачу на петли и обучаясь на самых успешных прошлых эпизодах, метод избегает грубых упрощений при сохранении практичности обучения. Хотя обучение всё ещё требует времени для очень больших сетей, этот подход указывает путь к будущим распределительным системам, где умные агенты постоянно точат настройки переключателей в фоновом режиме, снижая потери, поддерживая возобновляемую энергетику и незаметно делая энергоснабжение более надежным и экономичным.
Цитирование: Ghaemipour, A., Mashhadi, H.R. & Mostafavi, S.H. Accelerating the learning process of deep reinforcement learning algorithms in distribution network reconfiguration using an innovative replay method. Sci Rep 16, 12660 (2026). https://doi.org/10.1038/s41598-026-40508-4
Ключевые слова: распределение электроэнергии, умная сеть, обучение с подкреплением, оптимизация сети, интеграция солнечной энергии