Clear Sky Science · sv
Påskyndning av inlärningsprocessen för djupa förstärkningsinlärningsalgoritmer vid omkonfigurering av distributionsnät med en innovativ replay-metod
Smartare elnät för vardagslivet
El är så tillförlitligt på många platser att vi knappt reflekterar över hur det når våra hem och arbetsplatser. Men bakom kulisserna jonglerar kraftbolagen konstant med vilka ledningar som är aktiva för att leverera energi med så lite spill som möjligt. Denna artikel undersöker ett nytt sätt för ett artificiellt intelligenssystem att själv lära sig hur man omkonfigurerar lokala elnät för att minska förluster, hålla spänningarna inom hälsosamma gränser och reagera snabbt på förändrade förhållanden såsom solkraft och dagliga efterfrågesvängningar.
Varför kraftledningar behöver en bättre spelplan
I ett typiskt distributionsnät flödar elektricitet från en transformatorstation genom ett nät av ledningar och brytare till tusentals kunder. Vissa brytare är normalt slutna, andra hålls öppna så att den övergripande ledningsstrukturen bildar ett träd snarare än ett nätverk, vilket skyddar utrustning och förenklar drift. Över tid har ingenjörer utvecklat många skickliga matematiska och naturinspirerade algoritmer för att avgöra vilka brytare som bör vara öppna eller stängda för att minimera energiförluster och hålla spänningarna inom säkra gränser. Dessa metoder fungerar, men de bygger ofta på detaljerade modeller, kan kräva betydande beräkningstid och måste köras om varje gång förhållandena förändras.
Låta en AI-agent lära genom försök och misstag
Författarna behandlar i stället nätet som en inlärningslekplats för en djup förstärkningsinlärningsagent, en typ av AI som förbättras genom försök och misstag. I varje steg betraktar agenten nätets aktuella hälsa: spänningarna vid alla noder och statusen för varje ledning. Därefter väljer den vilken ledning som ska öppnas i varje slinga i nätet och får en poäng baserat på hur stor den totala effektförlusten är och hur långt någon spänning avviker från sitt ideala värde. Under många simulerade episoder lär sig agenten gradvis vilka kombinationer av brytarlägen som tenderar att ge låga förluster och stabila spänningar, utan att någonsin få de underliggande ekvationerna för effektflöde presenterade för sig.
Dela upp ett stort pussel i slingor
Ett stort hinder är det enorma antalet möjliga brytarinställningar i ett verkligt distributionsnät; antalet åtgärder exploderar när fler ledningar adderas. För att hantera detta introducerar artikeln en slinga-baserad strategi. Istället för att ha en enda jättelik beslutsfattare som väljer bland alla ledningar på en gång, dekomponeras nätet i slingor. Ett dedikerat inlärningsnätverk tilldelas varje slinga och ansvarar endast för att avgöra vilken ledning som ska öppnas inom den slingan. Författarna modifierar de vanliga inlärningsreglerna så att när en slinga väljer en ledning som delas med en annan slinga, behandlar de efterföljande slingorna automatiskt den ledningen som otillgänglig. Denna samordning gör det möjligt för systemet att respektera nätets fysiska begränsningar samtidigt som varje lärares beslutsspektrum hålls hanterbart.
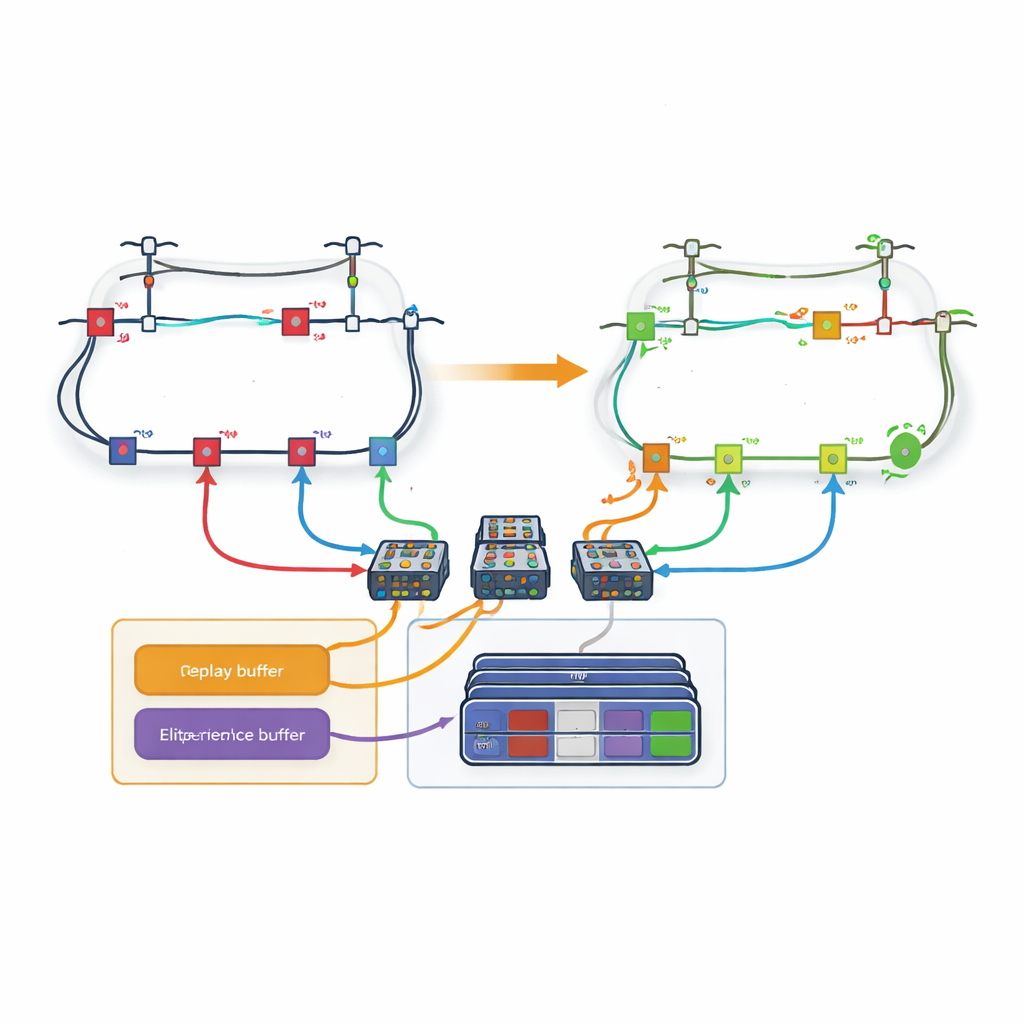
Komma ihåg bara de mest värdefulla erfarenheterna
Även med slingor kan inlärningen gå långsamt om varje tidigare erfarenhet behandlas lika. Författarna utformar därför en ny "loss-baserad experience replay"-mekanism. Under träning sparar agenten hela episoder—kompletta sekvenser av åtgärder och resulterande nätstatéer—in i minnet. Efter varje episod jämförs den slutliga effektförlusten med de bästa erfarenheterna som setts hittills. Endast de episoder som hamnar i den översta några procenten kopieras in i en särskild buffert. När agenten tränar sina neurala nät drar den några exempel från denna elitmängd och några från ordinarie erfarenhet, vilket skapar en balans mellan att fokusera på lovande mönster och att undvika snedvridning. Denna riktade replay hjälper agenten att konvergera snabbare till högkvalitativa strategier.
Bevisa idén på realistiska testnät
Forskarlaget testar sitt angreppssätt på tre välkända referenssystem med 33, 69 och 119 noder, inklusive varianter med takmonterade solpaneler och tidsvarierande efterfrågan över ett helt dygn. De jämför flera djupa inlärningsvarianter—med och utan den nya replay-bufferten—mot tidigare AI- och matematiska metoder. I samtliga nät minskar de slinga-baserade agenterna med den loss-fokuserade replayen konsekvent effektförlusterna mer än sina enklare motsvarigheter och matchar eller överträffar de bästa befintliga teknikerna. De gör det också med konkurrenskraftiga eller bättre beräkningstider när träningen väl är klar, vilket är avgörande för realtid eller frekvent omkonfigurering.
Vad detta betyder för framtidens nät
Enkelt uttryckt visar studien att ett omsorgsfullt utformat inlärningssystem kan lära sig att omorganisera nätets "vägar" så att elektriciteten färdas mer effektivt och håller sig inom säkra gränser, även när solenergi och efterfrågan förändras under dagen. Genom att dela upp problemet i slingor och träna på de mest framgångsrika tidigare erfarenheterna undviker metoden grova förenklingar samtidigt som inlärningen hålls praktisk. Även om träningen fortfarande tar tid för mycket stora nät, pekar detta angreppssätt mot framtida distributionssystem där smarta agenter kontinuerligt finjusterar brytarinställningar i bakgrunden, minskar förluster, stödjer förnybar energi och tyst gör vår el mer pålitlig och ekonomisk.
Citering: Ghaemipour, A., Mashhadi, H.R. & Mostafavi, S.H. Accelerating the learning process of deep reinforcement learning algorithms in distribution network reconfiguration using an innovative replay method. Sci Rep 16, 12660 (2026). https://doi.org/10.1038/s41598-026-40508-4
Nyckelord: elkraftdistribution, smart nät, förstärkningsinlärning, nätverksoptimering, solintegration