Clear Sky Science · fr
Accélérer le processus d’apprentissage des algorithmes d’apprentissage profond par renforcement pour la reconfiguration des réseaux de distribution grâce à une méthode innovante de relecture d’expériences
Des réseaux électriques plus intelligents pour la vie quotidienne
L’électricité est si fiable dans de nombreux endroits que l’on réfléchit rarement à la façon dont elle parvient à nos maisons et lieux de travail. Pourtant, en coulisses, les compagnies d’électricité jonglent en permanence avec les lignes actives pour livrer l’énergie en minimisant le gaspillage. Cet article explore une nouvelle manière de permettre à un système d’intelligence artificielle d’apprendre, de façon autonome, comment reconfigurer les réseaux locaux de distribution afin de réduire les pertes, maintenir des tensions saines et réagir rapidement à des conditions changeantes telles que l’apport solaire et les variations quotidiennes de la demande.
Pourquoi les lignes électriques ont besoin d’une meilleure stratégie
Dans un réseau de distribution typique, l’électricité circule depuis une sous-station à travers un maillage de lignes et d’interrupteurs jusqu’à des milliers de clients. Certains interrupteurs sont normalement fermés, d’autres restent ouverts pour que la topologie globale ressemble davantage à un arbre qu’à un maillage, ce qui protège l’équipement et simplifie l’exploitation. Au fil du temps, les ingénieurs ont conçu de nombreux algorithmes mathématiques et inspirés de la nature pour décider quels interrupteurs doivent être ouverts ou fermés afin de minimiser les pertes d’énergie et de maintenir les tensions dans des limites sûres. Ces méthodes fonctionnent, mais elles reposent souvent sur des modèles détaillés, peuvent nécessiter beaucoup de temps de calcul et doivent être relancées chaque fois que les conditions évoluent.
Laisser un agent IA apprendre par essai et erreur
Les auteurs traitent plutôt le réseau comme un terrain d’apprentissage pour un agent d’apprentissage profond par renforcement, un type d’IA qui s’améliore par essais et erreurs. À chaque étape, l’agent observe l’état actuel du réseau : les tensions à toutes les barres et le statut de chaque ligne. Il choisit ensuite quelle ligne ouvrir dans chaque boucle du réseau et reçoit un score basé sur la perte de puissance totale et l’écart de toute tension par rapport à sa valeur idéale. Au fil de nombreux épisodes simulés, l’agent découvre progressivement quelles combinaisons de positions d’interrupteurs tendent à produire de faibles pertes et des tensions stables, sans jamais se voir fournir les équations sous-jacentes du flux de puissance.
Diviser un grand puzzle en boucles
Un obstacle majeur est le nombre considérable de configurations possibles d’interrupteurs dans un réseau de distribution réel ; le nombre d’actions explose à mesure que des lignes sont ajoutées. Pour y remédier, l’article introduit une stratégie basée sur les boucles. Plutôt que d’avoir un unique décideur géant qui choisit parmi toutes les lignes en une seule fois, le réseau est décomposé en boucles. Un réseau d’apprentissage dédié est assigné à chaque boucle et n’est responsable que de décider quelle ligne ouvrir à l’intérieur de cette boucle. Les auteurs modifient les règles d’apprentissage usuelles de sorte que lorsqu’une boucle choisit une ligne partagée avec une autre boucle, les boucles ultérieures considèrent automatiquement cette ligne comme indisponible. Cette coordination permet au système de respecter les contraintes physiques du réseau tout en maintenant l’espace de décision de chaque apprenant raisonnable.
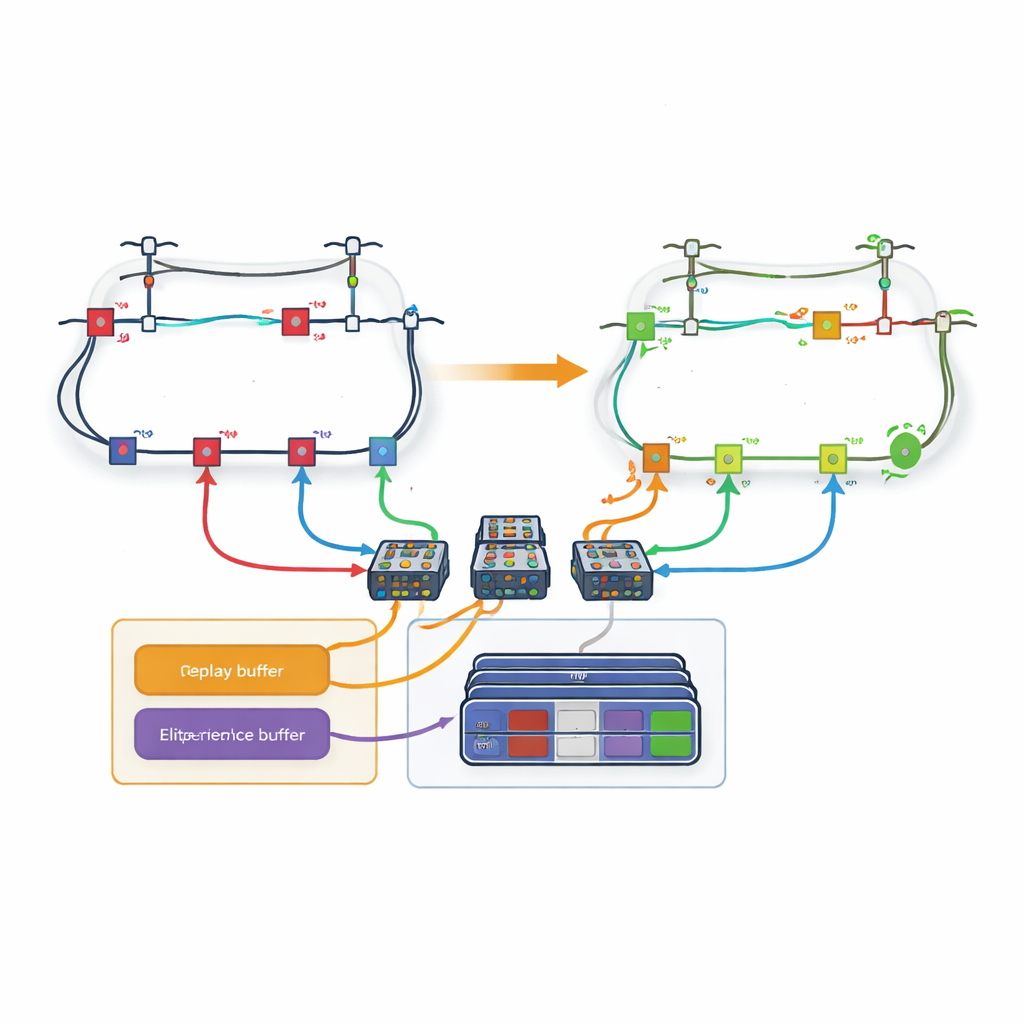
Ne retenir que les expériences les plus utiles
Même avec la décomposition en boucles, l’apprentissage peut être lent si chaque expérience passée est traitée de la même façon. Les auteurs conçoivent donc un nouveau mécanisme de « relecture d’expériences basé sur les pertes ». Pendant l’entraînement, l’agent stocke des épisodes complets — séquences entières d’actions et d’états du réseau résultants — en mémoire. Après chaque épisode, la perte finale de puissance est comparée aux meilleures expériences observées jusqu’alors. Seuls les épisodes figurant dans les quelques pourcents supérieurs sont copiés dans un tampon spécial. Lorsque l’agent entraîne ses réseaux neuronaux, il tire certains exemples de cet ensemble d’élite et d’autres de l’expérience ordinaire, trouvant un équilibre entre se concentrer sur des motifs prometteurs et éviter les biais. Cette relecture ciblée aide l’agent à converger plus rapidement vers des stratégies de haute qualité.
Valider l’idée sur des réseaux de test réalistes
Les chercheurs testent leur approche sur trois systèmes de référence bien connus comportant 33, 69 et 119 barres, incluant des versions avec panneaux solaires sur toiture et une demande variant au cours d’une journée complète. Ils comparent plusieurs variantes d’apprentissage profond — avec et sans le nouveau tampon de relecture — aux méthodes antérieures, tant en IA qu’en approches mathématiques. Sur l’ensemble des réseaux, les agents basés sur les boucles utilisant la relecture axée sur les pertes réduisent systématiquement les pertes d’énergie plus que leurs homologues simples et égalent ou surpassent les meilleures techniques existantes. Ils le font aussi avec des temps de calcul compétitifs ou meilleurs une fois l’entraînement terminé, ce qui est crucial pour une reconfiguration en temps réel ou fréquente.
Ce que cela signifie pour les réseaux du futur
Concrètement, l’étude montre qu’un système d’apprentissage soigneusement conçu peut s’enseigner comment réarranger les « routes » du réseau électrique pour que l’électricité circule plus efficacement et reste dans des limites sûres, même lorsque l’apport solaire et la demande varient au cours de la journée. En divisant le problème en boucles et en s’entraînant sur les expériences passées les plus performantes, la méthode évite les simplifications grossières tout en gardant l’apprentissage praticable. Bien que l’entraînement prenne encore du temps pour des réseaux très étendus, cette approche ouvre la voie à des systèmes de distribution futurs où des agents intelligents peaufinent en continu les positions d’interrupteurs en arrière-plan, réduisant les pertes, soutenant les énergies renouvelables et rendant notre électricité plus fiable et économique.
Citation: Ghaemipour, A., Mashhadi, H.R. & Mostafavi, S.H. Accelerating the learning process of deep reinforcement learning algorithms in distribution network reconfiguration using an innovative replay method. Sci Rep 16, 12660 (2026). https://doi.org/10.1038/s41598-026-40508-4
Mots-clés: distribution d’énergie, réseau intelligent, apprentissage par renforcement, optimisation de réseau, intégration solaire