Clear Sky Science · pt
Acelerando o processo de aprendizado de algoritmos de aprendizado por reforço profundo na reconfiguração de redes de distribuição usando um método inovador de replay
Redes de energia mais inteligentes para o dia a dia
A eletricidade é tão confiável em muitos lugares que raramente pensamos em como ela chega às nossas casas e locais de trabalho. Ainda assim, nos bastidores, as empresas de energia reorganizam constantemente quais linhas estão ativas para entregar energia com o mínimo de desperdício possível. Este artigo explora uma nova forma de permitir que um sistema de inteligência artificial aprenda, por conta própria, como reconfigurar redes elétricas locais para reduzir perdas, manter tensões saudáveis e reagir rapidamente a condições variáveis, como geração solar e oscilações diárias da demanda.
Por que as linhas de energia precisam de um plano melhor
Em uma rede de distribuição típica, a eletricidade flui de uma subestação por uma teia de linhas e chaves até milhares de consumidores. Algumas chaves ficam normalmente fechadas, outras são mantidas abertas para que o padrão geral de linhas se pareça com uma árvore em vez de uma malha, o que ajuda a proteger equipamentos e simplifica a operação. Ao longo do tempo, engenheiros desenvolveram muitos algoritmos matemáticos e inspirados na natureza para decidir quais chaves devem ficar abertas ou fechadas a fim de minimizar perdas de energia e manter as tensões dentro de limites seguros. Esses métodos funcionam, mas frequentemente dependem de modelos detalhados, podem exigir tempo de cálculo substancial e precisam ser reexecutados sempre que as condições mudam.
Deixar um agente de IA aprender por tentativa e erro
Os autores tratam a rede como um campo de aprendizado para um agente de aprendizado por reforço profundo, um tipo de IA que melhora por tentativa e erro. A cada passo, o agente observa a condição atual da rede: as tensões em todos os barramentos e o status de cada linha. Em seguida, escolhe qual linha abrir em cada laço da rede e recebe uma pontuação com base em quanto de potência total é perdida e o quanto alguma tensão se afasta do valor ideal. Ao longo de muitos episódios simulados, o agente gradualmente descobre quais combinações de posições de chaves tendem a produzir baixas perdas e tensões estáveis, sem jamais ser informado sobre as equações subjacentes do fluxo de potência.
Dividindo um grande quebra-cabeça em laços
Um obstáculo importante é o grande número de configurações possíveis de chaves em uma rede de distribuição real; o número de ações explode à medida que mais linhas são adicionadas. Para enfrentar isso, o artigo introduz uma estratégia baseada em laços. Em vez de ter um decisor gigante que escolhe entre todas as linhas de uma só vez, a rede é decomposta em laços. Uma rede de aprendizado dedicada é atribuída a cada laço e é responsável apenas por decidir qual linha abrir dentro desse laço. Os autores modificam as regras habituais de aprendizado de forma que, quando um laço escolhe uma linha que é compartilhada com outro laço, os laços posteriores automaticamente tratem essa linha como indisponível. Essa coordenação permite que o sistema respeite as restrições físicas da rede ao mesmo tempo em que mantém o espaço de decisão de cada aprendiz manejável.
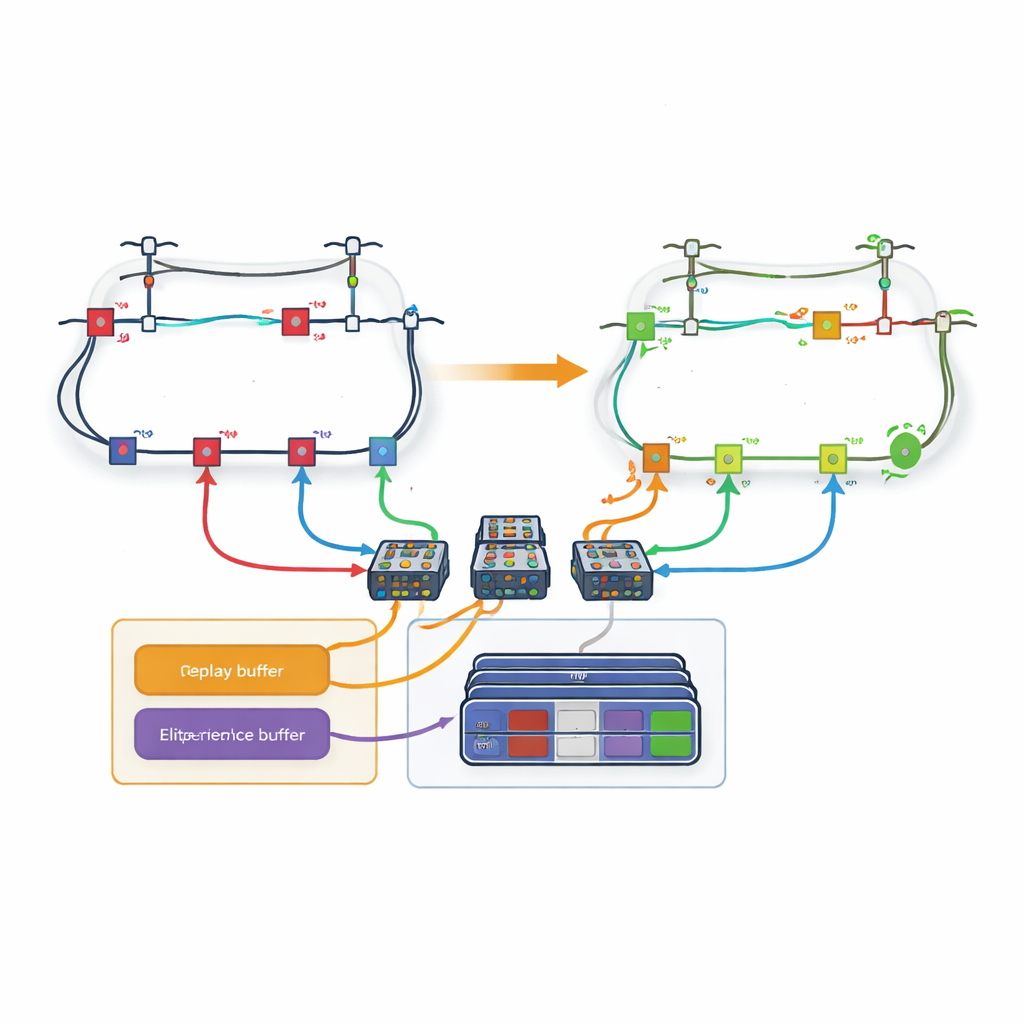
Lembrando apenas as experiências mais valiosas
Mesmo com os laços, o aprendizado pode ser lento se cada experiência passada for tratada igualmente. Os autores, portanto, projetam um novo mecanismo de “replay de experiência baseado em perda”. Durante o treinamento, o agente armazena episódios inteiros — sequências completas de ações e estados resultantes da rede — na memória. Após cada episódio, a perda de potência final é comparada com as melhores experiências vistas até então. Apenas os episódios que entram nos poucos por cento superiores são copiados para um buffer especial. Quando o agente treina suas redes neurais, ele seleciona alguns exemplos desse conjunto de elite e outros da experiência comum, equilibrando o foco em padrões promissores e a evitação de viés. Esse replay direcionado ajuda o agente a convergir mais rápido para estratégias de alta qualidade.
Comprovando a ideia em redes de teste realistas
Os pesquisadores testam sua abordagem em três sistemas de referência bem conhecidos com 33, 69 e 119 barramentos, incluindo versões com painéis solares em telhados e demanda variável ao longo de um dia inteiro. Eles comparam várias variantes de aprendizado profundo — com e sem o novo buffer de replay — contra métodos anteriores de inteligência artificial e matemáticos. Em todas as redes, os agentes baseados em laços usando o replay focado em perdas reduzem consistentemente as perdas de energia mais do que suas contrapartes simples e igualam ou superam as melhores técnicas existentes. Eles também o fazem com tempos de computação competitivos ou melhores uma vez que o treinamento é concluído, o que é crucial para reconfiguração em tempo real ou frequente.
O que isso significa para redes futuras
Em termos simples, o estudo mostra que um sistema de aprendizado cuidadosamente projetado pode ensinar a si mesmo como rearranjar as “estradas” da rede de energia para que a eletricidade viaje com mais eficiência e permaneça dentro de limites seguros, mesmo com a geração solar e a demanda mudando ao longo do dia. Ao dividir o problema em laços e treinar nas experiências passadas mais bem-sucedidas, o método evita simplificações grosseiras enquanto mantém o aprendizado prático. Embora o treinamento ainda leve tempo para redes muito grandes, essa abordagem aponta para sistemas de distribuição futuros onde agentes inteligentes ajustam continuamente as posições das chaves em segundo plano, reduzindo perdas, apoiando fontes renováveis e tornando nossa energia mais confiável e econômica.
Citação: Ghaemipour, A., Mashhadi, H.R. & Mostafavi, S.H. Accelerating the learning process of deep reinforcement learning algorithms in distribution network reconfiguration using an innovative replay method. Sci Rep 16, 12660 (2026). https://doi.org/10.1038/s41598-026-40508-4
Palavras-chave: distribuição de energia, rede inteligente, aprendizado por reforço, otimização de rede, integração solar