Clear Sky Science · nl
Het versnellingsproces van deep reinforcement learning-algoritmen bij het herconfigureren van distributienetwerken met een innovatieve replay-methode
Slimmere elektriciteitsnetten voor het dagelijks leven
Elektriciteit is op veel plaatsen zo betrouwbaar dat we nauwelijks nadenken over hoe het onze huizen en werkplekken bereikt. Achter de schermen jongleren energiebedrijven echter voortdurend met welke lijnen actief zijn, zodat ze energie met zo min mogelijk verspilling kunnen leveren. Dit artikel onderzoekt een nieuwe manier waarop een systeem voor kunstmatige intelligentie zelfstandig kan leren hoe lokale netwerken te herconfigureren om verliezen te verminderen, spanningen binnen veilige grenzen te houden en snel te reageren op veranderende omstandigheden zoals zonne-energie en dagelijkse vraagfluctuaties.
Waarom elektriciteitslijnen een beter plan nodig hebben
In een typisch distributienet stroomt elektriciteit van een onderstation via een web van lijnen en schakelaars naar duizenden afnemers. Sommige schakelaars zijn normaal gesproken gesloten, andere worden opengehouden zodat het totale patroon van lijnen op een boom lijkt in plaats van op een maaswerk, wat apparatuur beschermt en de exploitatie vereenvoudigt. In de loop der tijd hebben ingenieurs vele slimme mathematische en door de natuur geïnspireerde algoritmen ontworpen om te beslissen welke schakelaars open of dicht moeten zijn om energieverlies te minimaliseren en spanningen binnen veilige grenzen te houden. Deze methoden werken, maar ze zijn vaak afhankelijk van gedetailleerde modellen, kunnen aanzienlijke rekentijd vergen en moeten opnieuw worden uitgevoerd wanneer de omstandigheden veranderen.
Een AI-agent laten leren door trial-and-error
De auteurs behandelen het net in plaats daarvan als een leeromgeving voor een deep reinforcement learning-agent, een vorm van AI die verbetert via proberen en leren van fouten. Op elk moment bekijkt de agent de huidige staat van het netwerk: de spanningen op alle knooppunten en de status van elke lijn. Vervolgens kiest hij welke lijn in elke lus van het netwerk open te zetten en ontvangt een score op basis van hoeveel totaal vermogen verloren gaat en hoe ver een spanning afwijkt van de ideale waarde. Over vele gesimuleerde afleveringen leert de agent geleidelijk welke combinaties van schakelposities doorgaans leiden tot lage verliezen en stabiele spanningen, zonder ooit de onderliggende vergelijkingen van het power flow-model te kennen.
Een groot puzzelstuk opdelen in lussen
Een groot obstakel is het enorme aantal mogelijke schakelinstellingen in een echt distributienet; het aantal acties explodeert naarmate er meer lijnen bijkomen. Om dit aan te pakken introduceert het artikel een lus-gebaseerde strategie. In plaats van één gigantische beslisser die in één keer uit alle lijnen kiest, wordt het netwerk opgesplitst in lussen. Aan elke lus wordt een toegewijd leer-netwerk toegewezen dat uitsluitend verantwoordelijk is voor het beslissen welke lijn binnen die lus open gezet wordt. De auteurs passen de gebruikelijke leerregels aan zodat wanneer een lus een lijn kiest die gedeeld wordt met een andere lus, de latere lussen die lijn automatisch als niet-beschikbaar behandelen. Deze coördinatie stelt het systeem in staat om fysieke beperkingen van het net te respecteren terwijl de beslissingsruimte van elke leerling beheersbaar blijft.
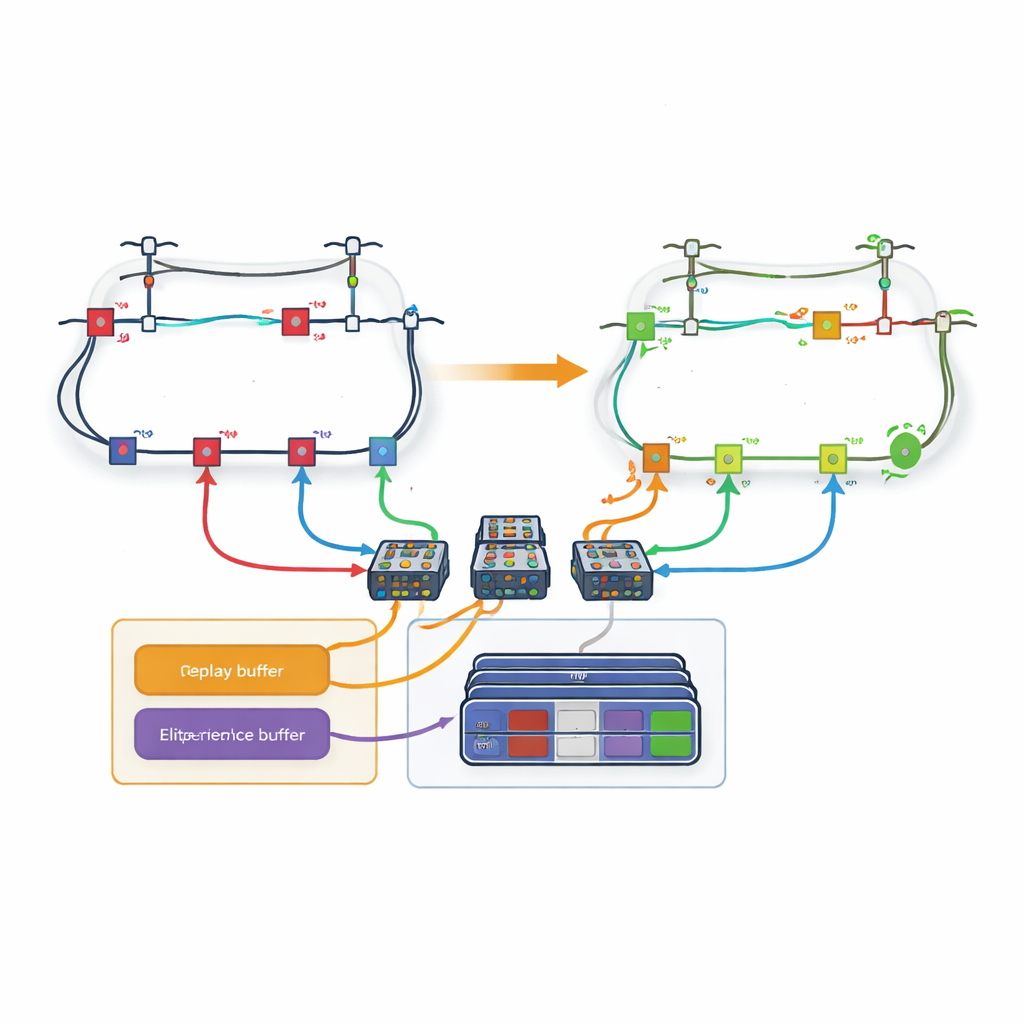
Alleen de meest waardevolle ervaringen onthouden
Zelfs met lussen kan het leren traag zijn als elke eerdere ervaring gelijk wordt behandeld. De auteurs ontwerpen daarom een nieuwe "loss-based experience replay"-mechanisme. Tijdens de training slaat de agent volledige afleveringen op—volledige reeksen van acties en resulterende netwerktrillingen—in het geheugen. Na elke aflevering wordt het uiteindelijke energieverlies vergeleken met de beste ervaringen tot nu toe. Alleen de afleveringen die in de toppercentielen terechtkomen, worden gekopieerd naar een speciaal buffer. Wanneer de agent zijn neurale netwerken traint, trekt hij enkele voorbeelden uit deze elite-set en enkele uit de gewone ervaringen, wat een balans creëert tussen focussen op veelbelovende patronen en het voorkomen van bias. Deze gerichte replay helpt de agent sneller te convergeren naar strategieën van hoge kwaliteit.
Het idee aantonen op realistische testnetwerken
De onderzoekers testen hun aanpak op drie bekende benchmarksystemen met 33, 69 en 119 knooppunten, inclusief versies met zonnepanelen op daken en tijdsvariërende vraag over een volledige dag. Ze vergelijken meerdere deep learning-varianten—met en zonder de nieuwe replay-buffer—met eerdere AI- en wiskundige methoden. In alle netwerken verminderen de lus-gebaseerde agenten met de loss-gerichte replay consequent de energieverliezen meer dan hun eenvoudige tegenhangers en evenaren of overtreffen ze de beste bestaande technieken. Ze doen dit ook met concurrerende of betere rekentijden zodra de training voltooid is, wat cruciaal is voor real-time of frequente herconfiguratie.
Wat dit betekent voor toekomstige netten
In eenvoudige bewoordingen toont de studie aan dat een zorgvuldig ontworpen leersysteem zichzelf kan leren hoe de "wegen" van het elektriciteitsnet her te rangschikken, zodat elektriciteit efficiënter transporteert en binnen veilige grenzen blijft, zelfs wanneer zonne-energie en vraag door de dag heen veranderen. Door het probleem in lussen op te delen en te trainen op de meest succesvolle ervaringen uit het verleden, vermijdt de methode ruwe vereenvoudigingen terwijl leren praktisch blijft. Hoewel training voor zeer grote netten nog steeds tijd kost, wijst deze aanpak op toekomstige distributiesystemen waarin slimme agenten voortdurend op de achtergrond schakelaars bijstellen, verliezen terugdringen, hernieuwbare energie ondersteunen en onze stroomvoorziening stiller, betrouwbaarder en economischer maken.
Bronvermelding: Ghaemipour, A., Mashhadi, H.R. & Mostafavi, S.H. Accelerating the learning process of deep reinforcement learning algorithms in distribution network reconfiguration using an innovative replay method. Sci Rep 16, 12660 (2026). https://doi.org/10.1038/s41598-026-40508-4
Trefwoorden: verdeelnetwerk, smart grid, reinforcement learning, netwerkoptimalisatie, zonne-integratie