Kuantum bilgisayarlarla ilgili birçok beklenti, bunların sıradan makinelerin yapamadığı biçimlerde veriden öğrenebileceği fikrine dayanıyor. Ancak klasik algoritmalar geliştikçe, önerilen bazı kuantum avantajları ortadan kalkıyor. Bu makale net bir soru soruyor: bir kuantum öğrenme modeli ile onun en iyi klasik kopyası anlaşmazlığa düştüğünde, bu ayrışma gerçek bir kazancı mı işaret eder yoksa sadece bir yanılsama mı?
Aynı deseni takip eden iki tür öğrenici
Yazarlar, varyasyonel kuantum devrelerinden oluşturulmuş popüler bir kuantum makine öğrenimi ailesini inceliyor. Bu devreler veriyi alır, onu kuantum durumlarına kodlar ve ardından bir tahmin gibi davranan bir çıktı ölçer. Matematiksel olarak, hem kuantum modeli hem de uygun şekilde seçilmiş bir klasik model aynı özellikler kümesi üzerinde çalışan basit doğrusal formüller gibi görülebilir. Bu ortak yapı, kuantum modelini davranışını taklit etmeye çalışan bir “vekil” klasik modelle değiştirmeyi cazip kılar ve gerçekten kuantum donanımına gerek olup olmadığı konusunda şüpheler doğurur.
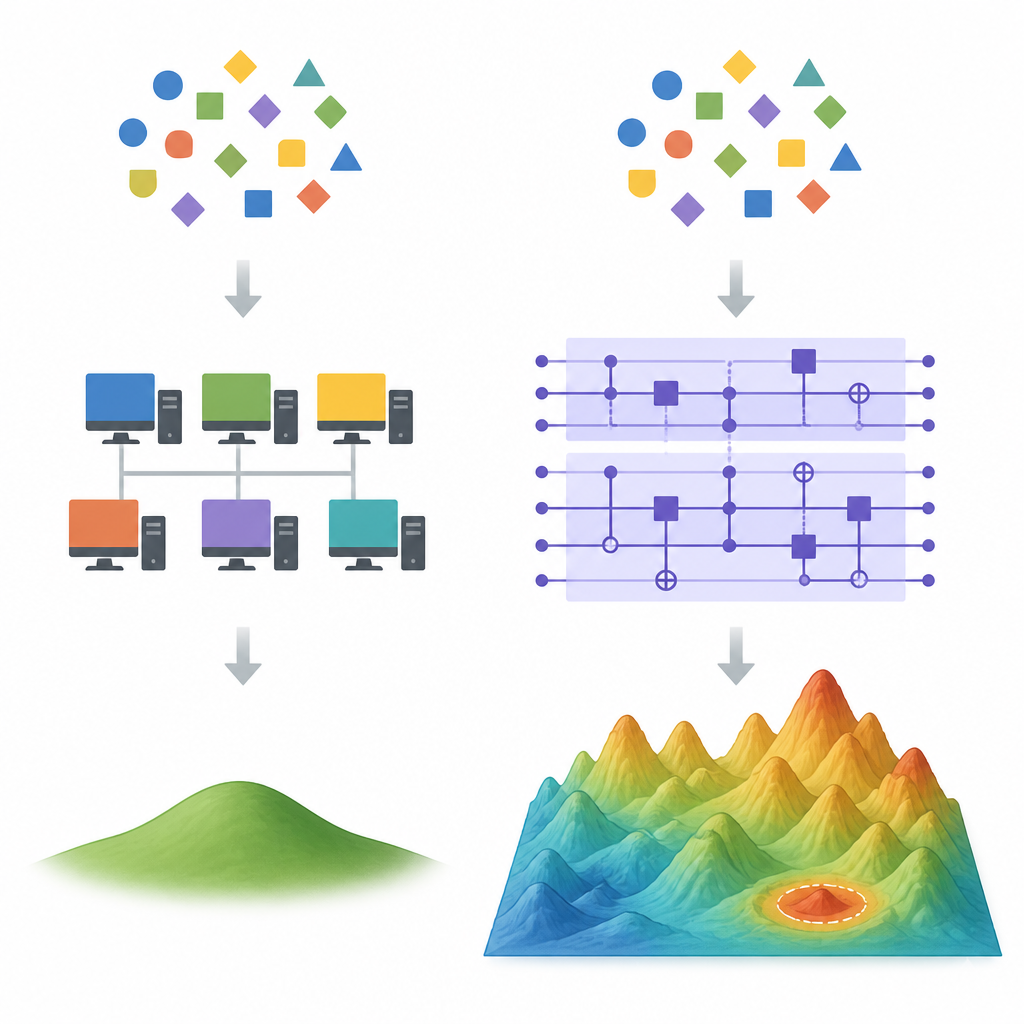
Klasik kestirmeler nerede başarısız olmaya başlar Figure 1. Birden çok farklı uyumun aynı verilere uygulanabildiği durumlarda kuantum ve klasik öğrenme modellerinin nasıl ayrıştığı
Yüksek boyutlu ortamlarda, aynı eğitim verisini mükemmel şekilde uyan çok sayıda farklı formül vardır. Gradient descent gibi klasik öğrenme yöntemleri genellikle bir özel çözümü tercih etme eğilimindedir: toplam ağırlığı en küçük olan çözüm, yani minimum normlu en küçük kareler seçimi. Rastgele özellik yöntemleri olarak adlandırılan güçlü klasik numaralar, bu tercih edilen çözümü tam modelin gerektirdiği özelliklerden çok daha azıyla yaklaşık olarak elde edebilir; bu da genellikle bir kuantum cihazının hız veya doğruluk üstünlüğünü ortadan kaldırır. Yazarlar, eğer bir kuantum modeli etkili biçimde aynı küçük ağırlıklı çözüme ulaşırsa, bu tür dekuantizasyon yöntemlerinin iyi çalışmasının muhtemel olduğunu gösteriyor.
Gerçek kuantum ayrışması için bir reçete
Ana öneri, kuantum modelinin ağırlık vektörünün büyüklüğüne bakmaktır. Başarılı eğitimden sonra kuantum ağırlıkları klasik minimum norm çözümün ağırlıklarından çok daha büyükse, iki model tahminciler uzayında birbirinden uzak durmak zorundadır. Bu durumda, rastgele özelliklere dayanan bir klasik vekil kuantum modelini hem takip edemez hem de iyi genelleme yapamaz. Makale bu fikri Fourier benzeri bileşenlerden ve yeniden yükleme (re-uploading) devrelerinden oluşturulmuş yaygın kuantum özellik haritaları için geliştirir ve kuantum öğrenicilerin şimdiden klasikleri geride bıraktığı kriptografi örnekleriyle bağlantı kurar.
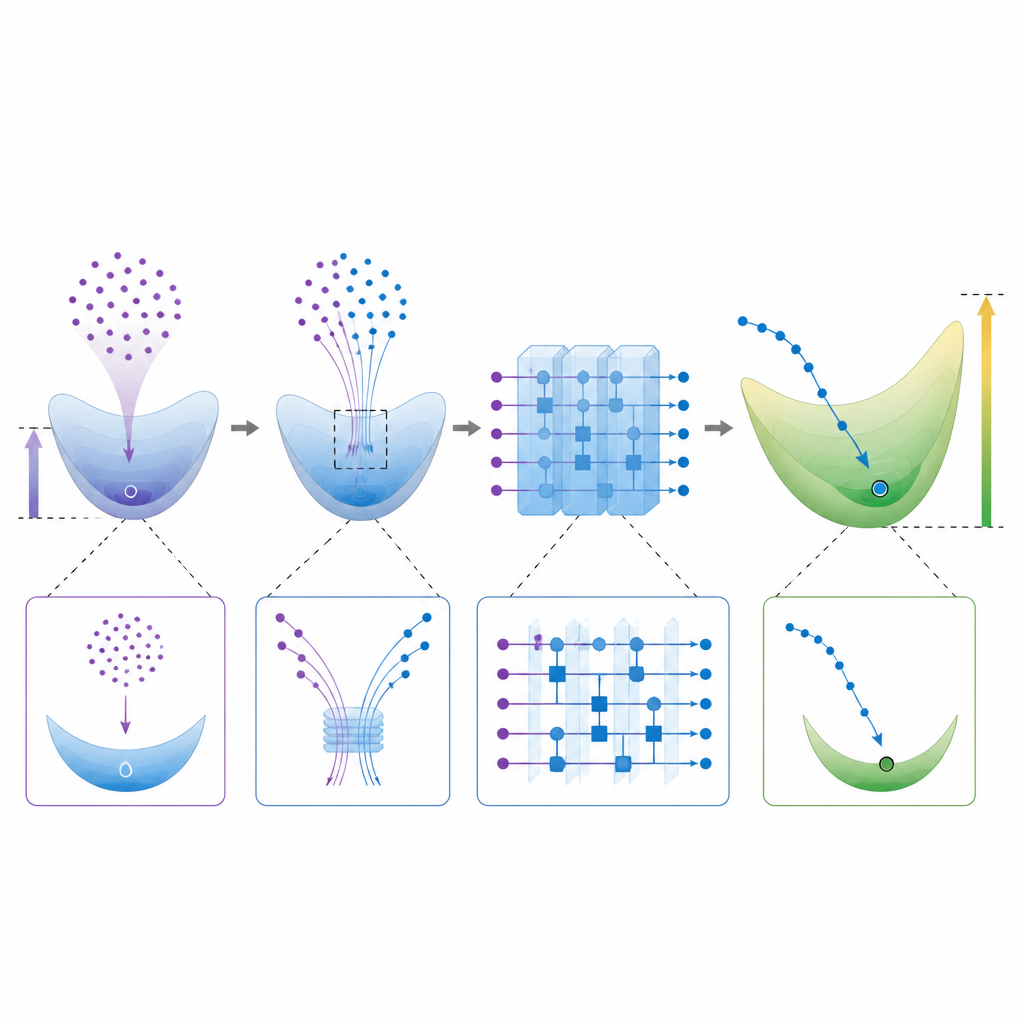
İfade gücü ile pratik eğitilebilirliği dengelemek Figure 2. Bir kuantum devresinin klasik bir öğreniciden farklı, yüksek boyutlu bir çözüm bulmasının adım adım görünümü
Kuantum modelleri büyük ağırlık vektörlerine doğru zorlamak bir bedel getirir. Yüksek ifade gücüne sahip rastgele devreler genellikle çıktılar ve eğitim sinyallerinin neredeyse düzleştiği “konsantrasyon” sorunundan muzdarip olur; bu da öğrenmeyi pratikte çok yavaş hale getirir. Yazarlar bu gerilimi analiz eder ve hem klasik minimum norm çözümünden uzak olan hem de yine de faydalı olacak kadar değişken olan matematiksel fonksiyon aileleri kurar. Ayrıca, deneycilere eğitilmiş bir devrenin klasik taklitten kaçma olasılığını kontrol etmeleri için devre değerlendirmelerinden doğrudan kuantum ağırlık vektörünün büyüklüğünü tahmin etmeye yönelik pratik bir yol sunarlar.
Bu kuantum üstünlüğü için ne anlama geliyor
Çalışma kuantum modellerinin otomatik olarak klasik olanlardan daha iyi olduğunu iddia etmiyor. Bunun yerine, bir kuantum öğrenme modelinin aynı özellikleri kullanan ucuz bir klasik yaklaşımla ne zaman değiştirilemeyeceğini gösteren açık koşullar sunuyor. Potansiyel avantajı kuantum çözümünün klasik minimum norm seçimine ne kadar uzak olduğuna bağlayarak ve özellik uzayı büyüklüğü ile konsantrasyon etkilerinin rolünü vurgulayarak, makale yalnızca klasik modellerden farklı değil, aynı zamanda potansiyel olarak daha faydalı olacak gelecekteki kuantum devrelerini tasarlamak için bir yol haritası taslağı sunuyor.
Atıf: Thabet, S., Monbroussou, L., Mamon, E.Z. et al. When quantum and classical models disagree: learning beyond minimum norm least square.
npj Quantum Inf12, 81 (2026). https://doi.org/10.1038/s41534-026-01217-y