Многие надежды на квантовые компьютеры основаны на том, что они будут учиться на данных способами, недоступными обычным машинам. Однако по мере усложнения классических алгоритмов некоторые предполагаемые квантовые преимущества исчезают. В этой статье задаётся прямой вопрос: когда квантовая модель обучения и её лучший классический аналог расходятся, указывает ли это на реальное преимущество, или это лишь иллюзия?
Два типа обучающихся, преследующие один и тот же паттерн
Авторы изучают популярный класс моделей квантового машинного обучения, построенных на вариационных квантовых цепях. Эти цепи принимают данные, кодируют их в квантовые состояния и затем измеряют выход, выполняющий роль предсказания. Математически и квантовая модель, и корректно подобранная классическая модель могут рассматриваться как простые линейные формулы, действующие на одном и том же наборе признаков. Эта общая структура заставляет задуматься о возможности замены квантовой модели «суррогатной» классической моделью, которая пытается имитировать её поведение, что порождает сомнения в необходимости квантового оборудования.
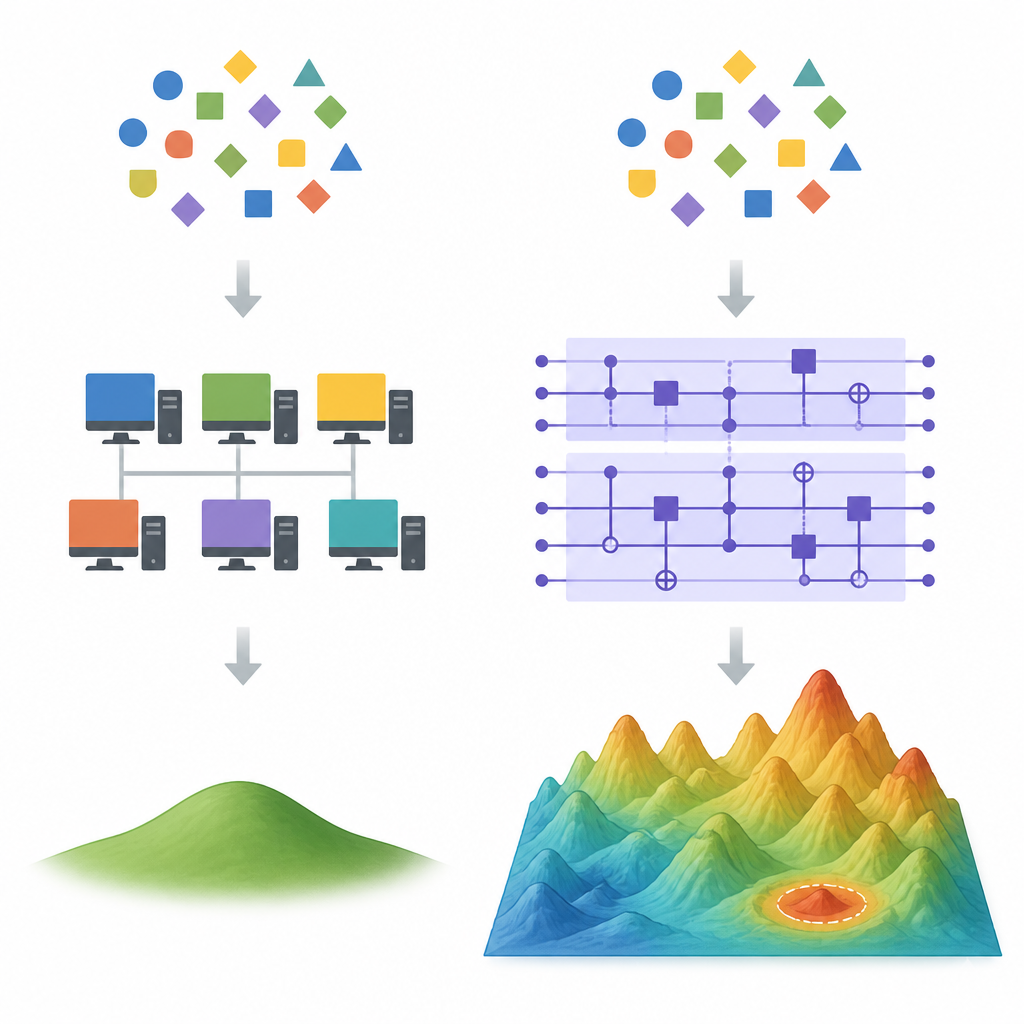
Где классические упрощения начинают подводить Figure 1. Как и почему квантовые и классические модели обучения расходятся, когда существует много различных приближений одних и тех же данных
В высокоразмерных задачах существует множество различных формул, которые идеально подгоняют одни и те же обучающие данные. Классические методы обучения, такие как градиентный спуск, как правило, отдают предпочтение одному особому решению: тому, у которого наименьшая общая норма весов, известному как решение наименьшей нормы для наименьших квадратов. Мощные классические приёмы, называемые методами случайных признаков, могут аппроксимировать это предпочитаемое решение, используя гораздо меньше признаков, чем полная модель, что часто устраняет любое преимущество по скорости или точности у квантового устройства. Авторы показывают, что если квантовая модель фактически сходится к тому же решению с малой нормой весов, то такие методы декавантования, скорее всего, будут работать хорошо.
Рецепт для подлинного квантового разделения
Ключевое предложение — смотреть на величину вектора весов квантовой модели. Если после успешного обучения веса квантовой модели намного больше, чем у классического решения наименьшей нормы, то две модели обязательно находятся далеко друг от друга в пространстве возможных предикторов. В этом случае классический суррогат на основе случайных признаков не сможет легко отслеживать квантовую модель, оставаясь при этом хорошо обобщающим. В статье развивают эту идею для распространённых квантовых отображений признаков, построенных из фурье-подобных компонент и так называемых цепей с повторной загрузкой (re-uploading), и связывают её с существующими примерами из криптографии, в которых квантовые обучающиеся уже опережают классические.
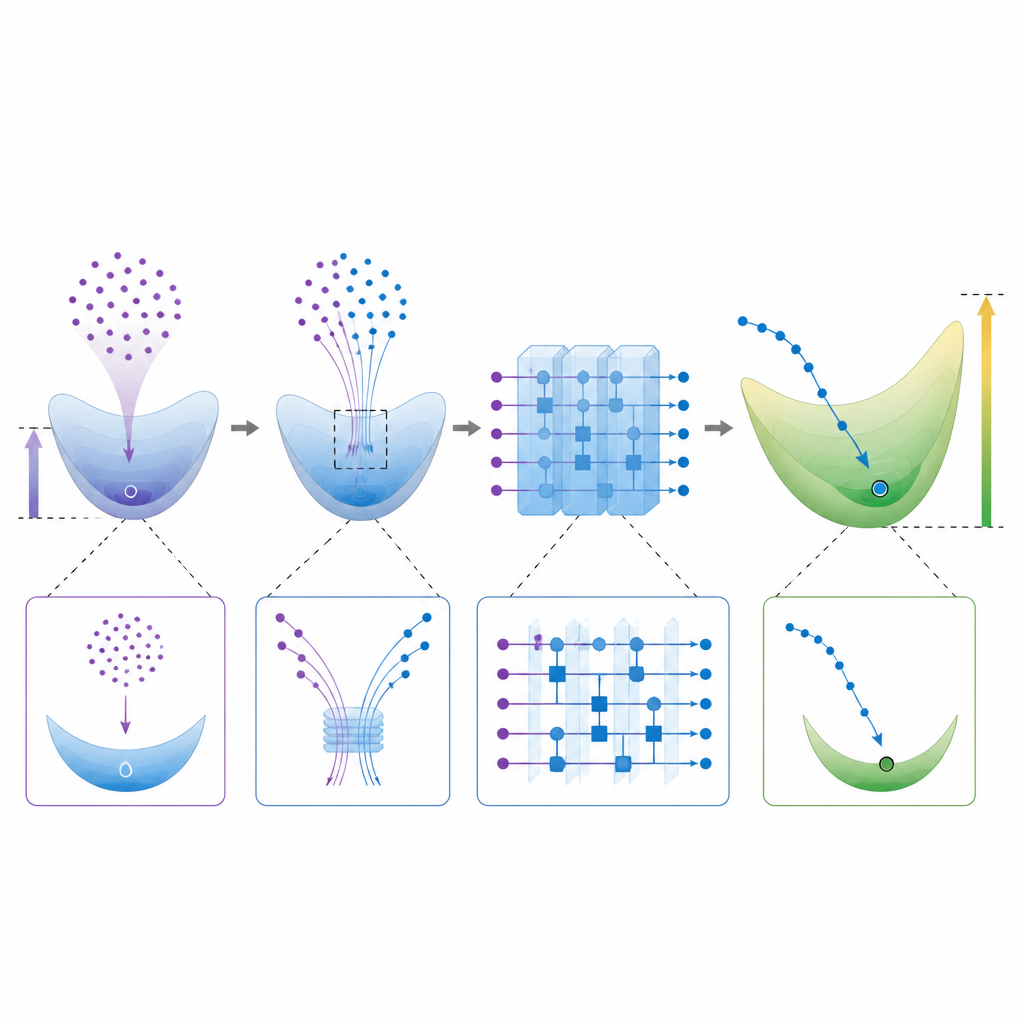
Баланс между выразительной силой и практической обучаемостью Figure 2. Пошаговый взгляд на то, как квантовая цепь находит другое высокоразмерное решение по сравнению с классическим обучающимся
Стремление направить квантовые модели к большим векторам весов имеет ограничение. Сильновыразительные случайные цепи часто страдают от «концентрации», когда выходы и сигналы обучения становятся почти плоскими, что делает обучение непрактично медленным. Авторы анализируют это напряжение и строят семьи математических функций, которые одновременно сильно отличаются от классического решения наименьшей нормы и при этом достаточно изменчивы, чтобы быть полезными. Они также предлагают практический способ оценить размер вектора весов квантовой модели непосредственно по вычислениям цепи, давая экспериментаторам инструмент для проверки того, вероятно ли, что обученная цепь ускользнёт от классической имитации.
Что это значит для квантового преимущества
Работа не утверждает, что квантовые модели автоматически превосходят классические. Вместо этого она предлагает ясные условия, показывающие, когда квантовую модель обучения нельзя дешёво заменить классической аппроксимацией, использующей те же признаки. Связывая потенциальное преимущество с тем, насколько далеко квантовое решение находится от классического выбора наименьшей нормы, и подчёркивая роль размера пространства признаков и эффектов концентрации, статья наметила дорожную карту по проектированию будущих квантовых цепей, которые не просто отличаются от классических моделей, но и потенциально более полезны.
Цитирование: Thabet, S., Monbroussou, L., Mamon, E.Z. et al. When quantum and classical models disagree: learning beyond minimum norm least square.
npj Quantum Inf12, 81 (2026). https://doi.org/10.1038/s41534-026-01217-y