Perché questo è importante per i computer del futuro
Molte speranze riposte nei computer quantistici si basano sull’idea che potranno apprendere dai dati in modi che le macchine ordinarie non possono. Ma man mano che gli algoritmi classici migliorano, alcuni vantaggi quantistici proposti svaniscono. Questo articolo pone una domanda netta: quando un modello di apprendimento quantistico e la sua migliore controparte classica dissentono, quella divergenza può indicare un guadagno reale o è solo un’illusione?
Due tipi di apprendenti che inseguono lo stesso schema
Gli autori studiano una famiglia diffusa di modelli di machine learning quantistico costruiti con circuiti quantistici variazionali. Questi circuiti prendono dati, li codificano in stati quantistici e poi misurano un output che funge da predizione. Matematicamente, sia il modello quantistico sia un opportunamente scelto modello classico possono essere visti come semplici formule lineari che agiscono sullo stesso insieme di caratteristiche. Questa struttura condivisa rende allettante sostituire il modello quantistico con un surrogato classico che cerchi di imitarne il comportamento, sollevando dubbi sul fatto che l’hardware quantistico sia davvero necessario.
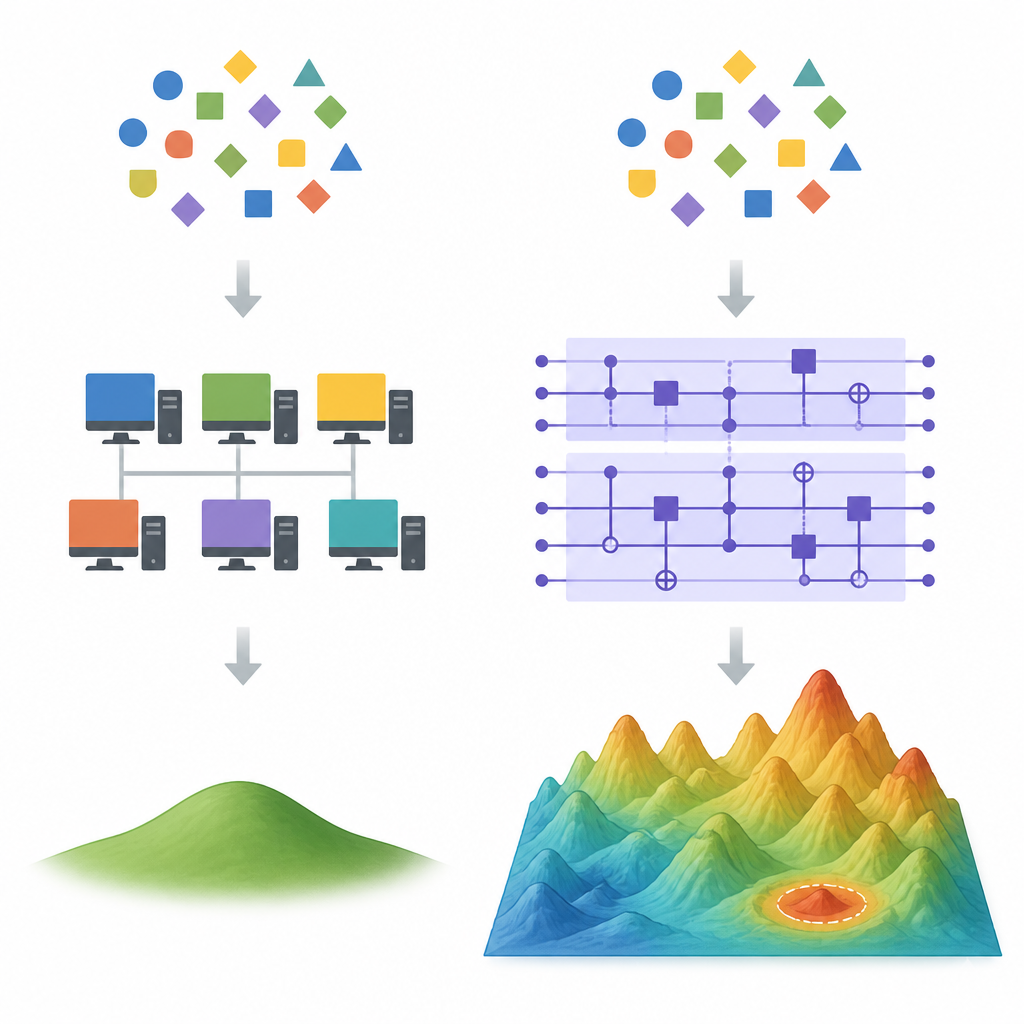
Dove le scorciatoie classiche iniziano a fallire Figure 1. Come i modelli di apprendimento quantistici e classici divergono quando sono possibili molteplici fit diversi sugli stessi dati
In ambienti ad alta dimensionalità esistono molte formule diverse che si adattano perfettamente agli stessi dati di addestramento. I metodi di apprendimento classici come la discesa del gradiente tendono a favorire una soluzione particolare: quella con il peso complessivo più piccolo, nota come scelta dei minimi quadrati a norma minima. Potenti stratagemmi classici chiamati metodi a caratteristiche casuali possono approssimare questa soluzione favorita usando molte meno caratteristiche rispetto al modello completo, eliminando spesso qualsiasi vantaggio in termini di velocità o accuratezza che un dispositivo quantistico potrebbe avere. Gli autori mostrano che se un modello quantistico converge effettivamente sulla stessa soluzione a piccolo peso, allora tali metodi di dequantizzazione probabilmente funzioneranno bene.
Una ricetta per una separazione quantistica genuina
La proposta centrale è guardare alla dimensione del vettore di pesi del modello quantistico. Se, dopo un addestramento riuscito, i pesi quantistici sono molto più grandi di quelli della soluzione classica a norma minima, i due modelli devono trovarsi lontani nello spazio dei predittori possibili. In tal caso, un surrogato classico basato su caratteristiche casuali non può facilmente seguire il modello quantistico mantenendo comunque una buona capacità di generalizzazione. L’articolo sviluppa questa idea per mappe di caratteristiche quantistiche comuni costruite da componenti simili a Fourier e da cosiddetti circuiti di re-uploading, e la collega a esempi esistenti in crittografia nei quali gli apprendenti quantistici già superano quelli classici.
Bilanciare potere espressivo e addestrabilità pratica Figure 2. Visione passo dopo passo di un circuito quantistico che trova una soluzione ad alta dimensionalità diversa da quella di un apprendente classico
Spingere i modelli quantistici verso vettori di peso di grande entità comporta però un rovescio della medaglia. Circuiti casuali altamente espressivi spesso soffrono di “concentrazione”, per cui output e segnali di addestramento diventano quasi piatti, rendendo l’apprendimento impraticabilmente lento. Gli autori analizzano questa tensione e costruiscono famiglie di funzioni matematiche che sono sia lontane dalla soluzione classica a norma minima sia sufficientemente variabili da essere utili. Forniscono inoltre un modo pratico per stimare la grandezza del vettore di pesi quantistico direttamente dalle valutazioni del circuito, offrendo agli sperimentatori uno strumento per verificare se un circuito addestrato è probabile che sfugga all’imitazione classica.
Cosa significa questo per il vantaggio quantistico
Il lavoro non pretende che i modelli quantistici superino automaticamente quelli classici. Invece, offre condizioni chiare che mostrano quando un modello di apprendimento quantistico non può essere facilmente sostituito da un’approssimazione classica usando le stesse caratteristiche. Collegando il potenziale vantaggio a quanto la soluzione quantistica è distante dalla scelta classica a norma minima, e mettendo in luce il ruolo della dimensione dello spazio delle caratteristiche e degli effetti di concentrazione, l’articolo delinea una roadmap per progettare futuri circuiti quantistici che non siano solo diversi dai modelli classici, ma potenzialmente più utili.
Citazione: Thabet, S., Monbroussou, L., Mamon, E.Z. et al. When quantum and classical models disagree: learning beyond minimum norm least square.
npj Quantum Inf12, 81 (2026). https://doi.org/10.1038/s41534-026-01217-y