Viele Hoffnungen in Quantencomputer beruhen auf der Vorstellung, dass sie aus Daten auf Weisen lernen, die gewöhnliche Rechner nicht erreichen können. Doch je raffinierter klassische Algorithmen werden, desto mehr verschwinden einige der vorgeschlagenen Quantenvorteile. Dieser Artikel stellt eine präzise Frage: Wenn ein Quanten-Lernmodell und sein bester klassischer Vertreter auseinandergehen, signalisiert diese Diskrepanz einen tatsächlichen Gewinn, oder ist sie nur eine Fata Morgana?
Zwei Arten von Lernern, die demselben Muster folgen
Die Autorinnen und Autoren untersuchen eine verbreitete Familie von Quanten-Maschinenlernmodellen, die auf variationalen Quanten-Schaltkreisen basieren. Diese Schaltkreise nehmen Daten, kodieren sie in Quantenzustände und messen dann eine Ausgabe, die wie eine Vorhersage wirkt. Mathematisch lassen sich sowohl das Quantenmodell als auch ein geeignet gewähltes klassisches Modell als einfache lineare Formeln über denselben Merkmalsraum auffassen. Diese gemeinsame Struktur macht es verlockend, das Quantenmodell durch einen klassischen „Surrogat“-Ansatz zu ersetzen, der versucht, sein Verhalten zu imitieren, und wirft Zweifel auf, ob Quanten-Hardware wirklich nötig ist.
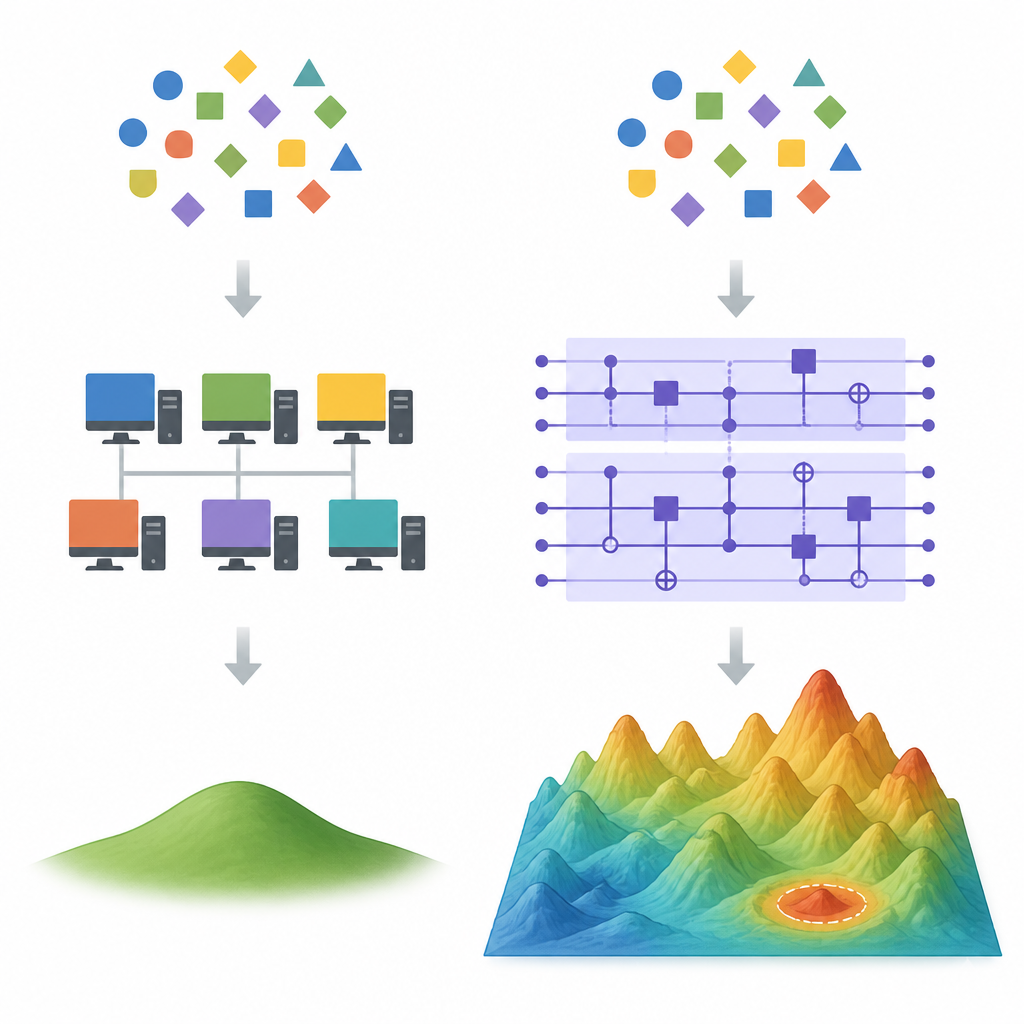
Wo klassische Abkürzungen zu versagen beginnen Figure 1. Wie Quanten- und klassische Lernmodelle auseinandergehen, wenn viele verschiedene Anpassungen an dieselben Daten möglich sind
In hochdimensionalen Settings gibt es viele verschiedene Formeln, die dieselben Trainingsdaten perfekt erklären. Klassische Lernverfahren wie Gradientenabstieg tendieren dazu, eine besondere Lösung zu bevorzugen: jene mit dem kleinsten Gesamtgewicht, bekannt als Minimum-Norm-Quadratsummen-Lösung. Leistungsfähige klassische Tricks, sogenannte Random-Feature-Methoden, können diese bevorzugte Lösung mit weit weniger Merkmalen als das vollständige Modell approximieren, was oft jede Geschwindigkeits- oder Genauigkeitsvorteil eines Quanten-Geräts aufhebt. Die Autorinnen und Autoren zeigen, dass, wenn ein Quantenmodell effektiv auf derselben kleinen Gewichtslösung landet, solche Dequantisierungs-Methoden wahrscheinlich gut funktionieren.
Ein Rezept für echte Quanten-Trennung
Der zentrale Vorschlag ist, die Größe des Gewichtvektors des Quantenmodells zu betrachten. Wenn die Quantengewichte nach erfolgtem Training deutlich größer sind als die des klassischen Minimum-Norm-Lösungsvektors, müssen sich die beiden Modelle im Raum möglicher Prädiktoren weit auseinander befinden. In diesem Fall kann ein klassischer Surrogat-Ansatz auf Basis von Random Features das Quantenmodell nicht leicht verfolgen und gleichzeitig gut generalisieren. Die Arbeit entwickelt diese Idee für gängige Quanten-Feature-Maps, die aus Fourier-ähnlichen Komponenten oder aus sogenannten Re-Uploading-Schaltkreisen aufgebaut sind, und verbindet sie mit existierenden Beispielen aus der Kryptographie, in denen Quanten-Lerner bereits klassische übertreffen.
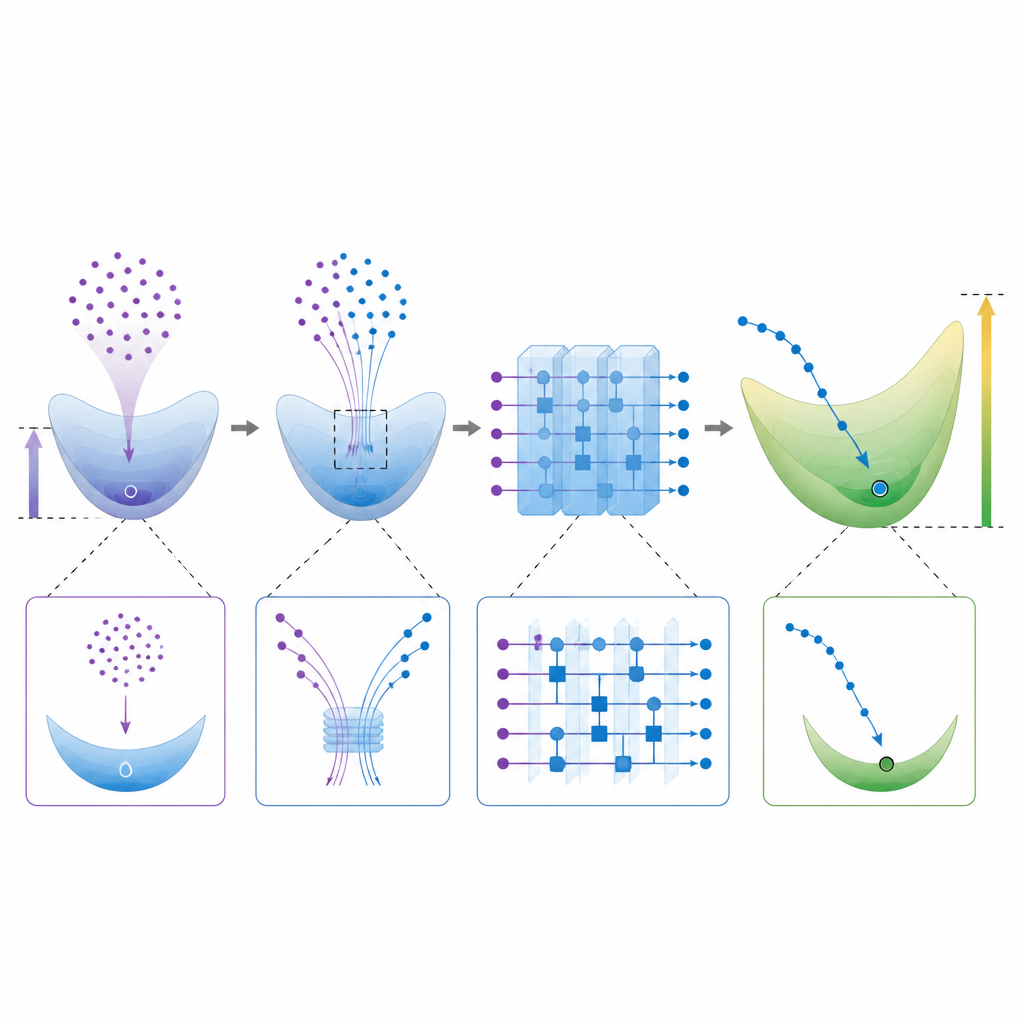
Ausgewogenheit von Ausdruckskraft und praktischer Trainierbarkeit Figure 2. Schritt-für-Schritt-Betrachtung, wie ein Quanten-Schaltkreis eine andere hochdimensionale Lösung findet als ein klassischer Lerner
Quantenmodelle in Richtung großer Gewichtvektoren zu treiben, hat einen Haken. Hoch expressive zufällige Schaltkreise leiden oft unter „Konzentration“, wobei Ausgaben und Trainingssignale nahezu flach werden und das Lernen unpraktisch langsam machen. Die Autorinnen und Autoren analysieren diese Spannung und konstruieren Familien mathematischer Funktionen, die sowohl weit von der klassischen Minimum-Norm-Lösung entfernt sind als auch noch genug Variation aufweisen, um nützlich zu sein. Sie bieten außerdem eine praktische Methode an, die Größe des Quanten-Gewichtvektors direkt aus Schaltkreisauswertungen abzuschätzen und geben Experimentalgruppen ein Werkzeug an die Hand, um zu überprüfen, ob ein trainierter Schaltkreis wahrscheinlich der klassischen Nachahmung entgeht.
Was das für den Quanten-Vorteil bedeutet
Die Arbeit behauptet nicht, dass Quantenmodelle automatisch klassische übertreffen. Stattdessen liefert sie klare Bedingungen, die zeigen, wann ein Quanten-Lernmodell nicht kostengünstig durch eine klassische Approximation mit denselben Features ersetzt werden kann. Indem sie einen möglichen Vorteil daran knüpft, wie weit die Quantenlösung von der klassischen Minimum-Norm-Wahl entfernt liegt, und die Rolle der Feature-Raum-Größe sowie Konzentrationseffekte hervorhebt, skizziert das Papier einen Fahrplan zum Entwurf künftiger Quanten-Schaltkreise, die nicht nur anders sind als klassische Modelle, sondern potenziell nützlicher.
Zitation: Thabet, S., Monbroussou, L., Mamon, E.Z. et al. When quantum and classical models disagree: learning beyond minimum norm least square.
npj Quantum Inf12, 81 (2026). https://doi.org/10.1038/s41534-026-01217-y
Schlüsselwörter: Quanten-Maschinelles Lernen, variationale Quanten-Schaltkreise, Random Features, klassische Surrogate, Quanten-Vorteil