Veel verwachtingen rond kwantumcomputers zijn gebaseerd op het idee dat ze uit data kunnen leren op manieren die gewone machines niet aankunnen. Maar naarmate klassieke algoritmen slimmer worden, vervaagt soms het vermeende kwantumvoordeel. Dit artikel stelt een scherpe vraag: wanneer een kwantumleermodel en zijn beste klassieke tegenhanger het oneens zijn, wijst die kloof dan op een reële winst, of is het een illusie?
Twee soorten leerlingen die hetzelfde patroon najagen
De auteurs bestuderen een populaire familie van kwantum-machine-learningmodellen opgebouwd uit variationale kwantumcircuits. Deze circuits nemen data, coderen die in kwantumtoestanden en meten vervolgens een output die als voorspelling fungeert. Wiskundig gezien kunnen zowel het kwantummodel als een passend gekozen klassiek model worden gezien als eenvoudige lineaire formules op dezelfde set features. Die gedeelde structuur maakt het verleidelijk het kwantummodel te vervangen door een klassiek “surrogaat” dat zijn gedrag probeert na te bootsen, wat vragen oproept of kwantumhardware echt noodzakelijk is.
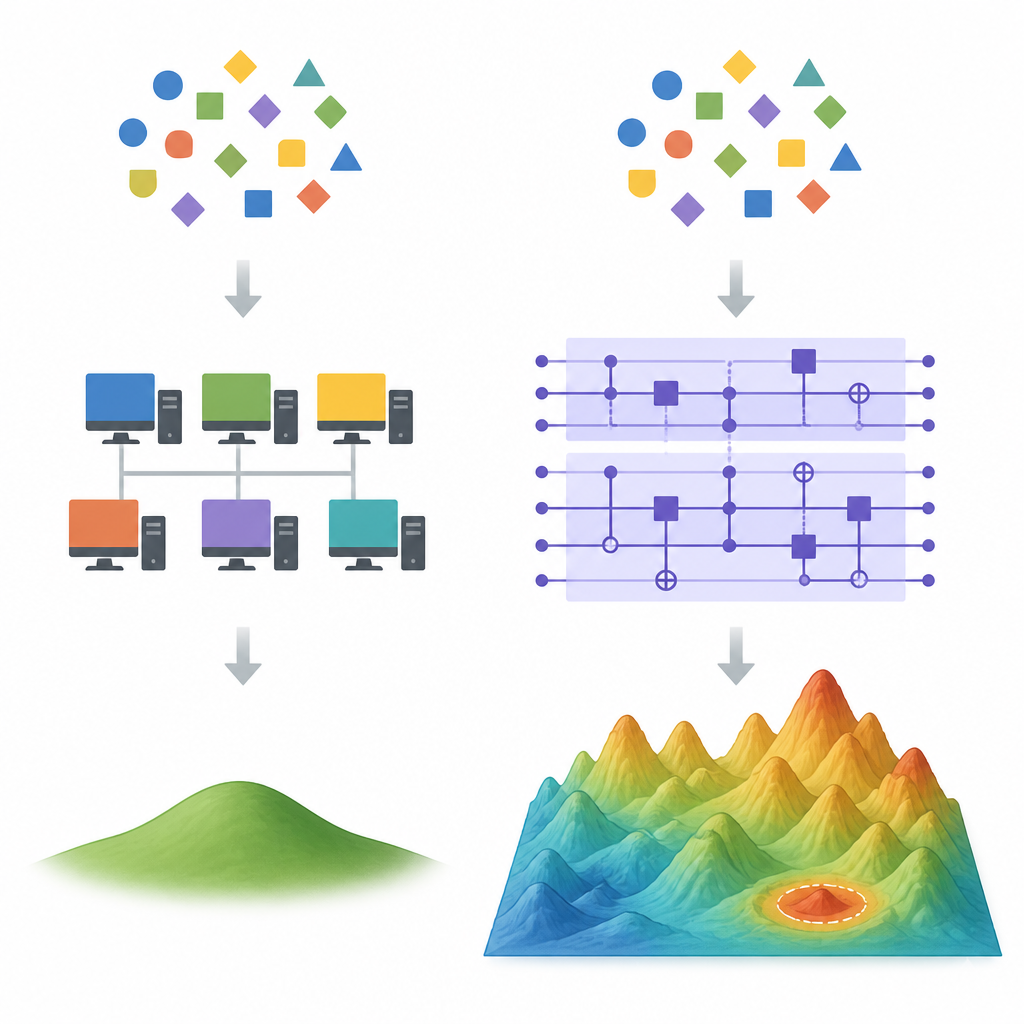
Waar klassieke snelkoppelingen beginnen te falen Figure 1. Hoe kwantum- en klassieke leermodellen uiteenlopen wanneer veel verschillende fits voor dezelfde data mogelijk zijn
In hoog-dimensionale situaties bestaan er veel verschillende formules die dezelfde trainingsdata perfect passen. Klassieke leermethoden zoals gradient descent geven de voorkeur aan één speciale oplossing: degene met de kleinste totale gewichtsnorm, bekend als de minimumnorm least squares-oplossing. Krachtige klassieke trucs, zogeheten random feature-methoden, kunnen deze bevoordeelde oplossing benaderen met veel minder features dan het volledige model, wat vaak elk snelheids- of nauwkeurigheidsvoordeel van een kwantumapparaat wegneemt. De auteurs laten zien dat wanneer een kwantummodel effectief op dezelfde kleine-gewichtsoplossing uitkomt, zulke dekwantisatiemethoden waarschijnlijk goed zullen werken.
Een recept voor echte kwantumscheiding
De kernvoorstel is om te kijken naar de grootte van de gewichtsvector van het kwantummodel. Als, na succesvol trainen, de kwantumgewichten veel groter zijn dan die van de klassieke minimumnormoplossing, moeten de twee modellen ver van elkaar zitten in de ruimte van mogelijke voorspellers. In dat geval kan een klassiek surrogaat gebaseerd op random features het kwantummodel niet gemakkelijk volgen zonder slecht te generaliseren. Het artikel werkt dit idee uit voor veelvoorkomende kwantumfeaturemaps opgebouwd uit Fourier-achtige componenten en uit zogenoemde re-uploading-circuits, en verbindt het met bestaande voorbeelden uit de cryptografie waarin kwantumleerlingen klassieke exemplaren al overtreffen.
Balanceren van expressieve kracht en praktische trainbaarheid Figure 2. Stapsgewijze weergave van een kwantumcircuit dat een andere hoog-dimensionale oplossing vindt dan een klassieke leerling
Het duwen van kwantummodellen naar grote gewichtsvectoren kent een keerzijde. Zeer expressieve random circuits lijden vaak aan “concentratie”, waarbij outputs en trainingssignalen bijna vlak worden, wat leren onpraktisch traag maakt. De auteurs analyseren deze spanning en construeren families van wiskundige functies die zowel ver van de klassieke minimumnormoplossing liggen als genoeg variatie behouden om nuttig te zijn. Ze bieden ook een praktische manier om de grootte van de kwantumgewichtsvector rechtstreeks uit circuit-evaluaties te schatten, waarmee experimentatoren kunnen controleren of een getraind circuit waarschijnlijk klassieke imitatie weet te ontwijken.
Wat dit betekent voor het kwantumvoordeel
Het werk beweert niet dat kwantummodellen automatisch beter presteren dan klassieke. In plaats daarvan biedt het heldere voorwaarden die aangeven wanneer een kwantumleermodel niet goedkoop kan worden vervangen door een klassieke benadering met dezelfde features. Door potentiële voordelen te koppelen aan hoe ver de kwantumoplossing verwijderd is van de klassieke minimumnormkeuze, en door de rol van de grootte van de featurespace en concentratie-effecten te benadrukken, schetst het artikel een routekaart voor het ontwerpen van toekomstige kwantumcircuits die niet alleen anders zijn dan klassieke modellen, maar mogelijk ook nuttiger.
Bronvermelding: Thabet, S., Monbroussou, L., Mamon, E.Z. et al. When quantum and classical models disagree: learning beyond minimum norm least square.
npj Quantum Inf12, 81 (2026). https://doi.org/10.1038/s41534-026-01217-y