Många förhoppningar på kvantdatorer bygger på idén att de ska kunna lära av data på sätt som vanliga maskiner inte klarar. Men när klassiska algoritmer blir bättre försvinner vissa föreslagna kvantfördelar. Den här artikeln ställer en skarp fråga: när en kvantlärmodell och dess bästa klassiska motsvarighet inte är överens, är den oenigheten ett tecken på verklig vinning, eller bara en synvilla?
Två typer av inlärare som jagar samma mönster
Författarna studerar en populär familj av kvantmaskininlärningsmodeller uppbyggda av variabla kvantkretsar. Dessa kretsar tar data, kodar in dem i kvanttillstånd och mäter sedan en utsignal som fungerar som en prediktion. Matematisk kan både kvantmodellen och en lämpligt vald klassisk modell ses som enkla linjära kombinationer som verkar på samma uppsättning funktioner. Denna delade struktur gör det lockande att ersätta kvantmodellen med en klassisk ”surrogat” som försöker efterlikna dess beteende, vilket väcker frågor om huruvida kvantmaskinvara verkligen är nödvändig.
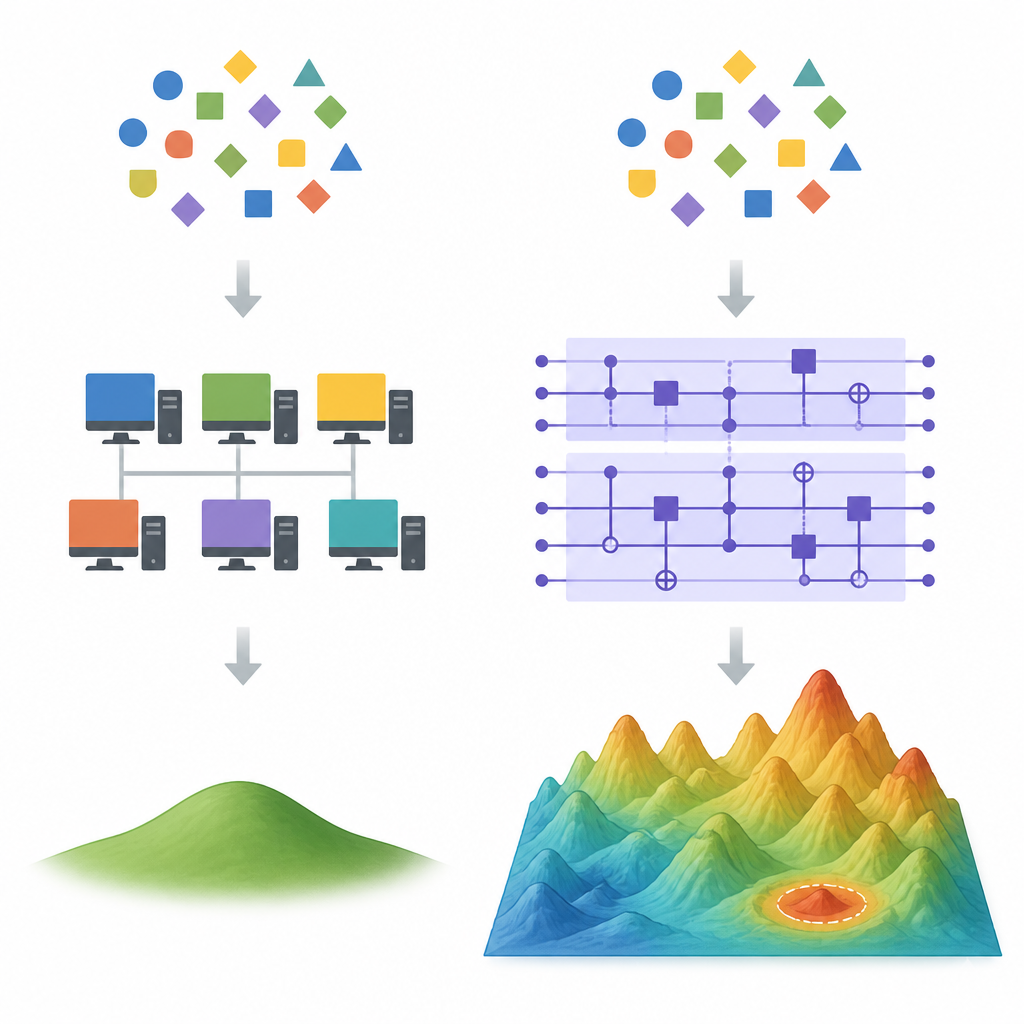
Var klassiska genvägar börjar svika Figure 1. Hur kvant- och klassiska lärandemodeller avviker när många olika anpassningar till samma data är möjliga
I högdimensionella situationer finns det många olika formler som passar samma träningsdata perfekt. Klassiska inlärningsmetoder som gradientnedstigning tenderar att favorisera en speciell lösning: den med minst totalvikt, känd som minsta normens minstakvadratlösning. Kraftfulla klassiska tricks, så kallade random feature-metoder, kan approximera denna favoriserade lösning med betydligt färre funktioner än hela modellen, vilket ofta tar bort både hastighets- och noggrannhetsfördelar som en kvantenhet skulle ha. Författarna visar att om en kvantmodell i praktiken landar på samma småviktslösning, är sådana dekvantiseringsmetoder sannolikt effektiva.
En receptbok för verklig kvantseparation
Kärnförslaget är att titta på storleken hos kvantmodellens viktvektor. Om de kvantiska vikterna efter framgångsrik träning är mycket större än de hos den klassiska minsta norm-lösningen måste de två modellerna ligga långt ifrån varandra i rymden av möjliga prediktorer. I så fall kan ett klassiskt surrogat baserat på slumpmässiga funktioner inte lätt följa kvantmodellen samtidigt som det generaliserar väl. Artikeln utvecklar denna idé för vanliga kvantiska funktionskartor byggda av Fourier-liknande komponenter och så kallade re-uploading-kretsar, och knyter an till befintliga exempel från kryptografi där kvantlärande redan överträffar klassiska metoder.
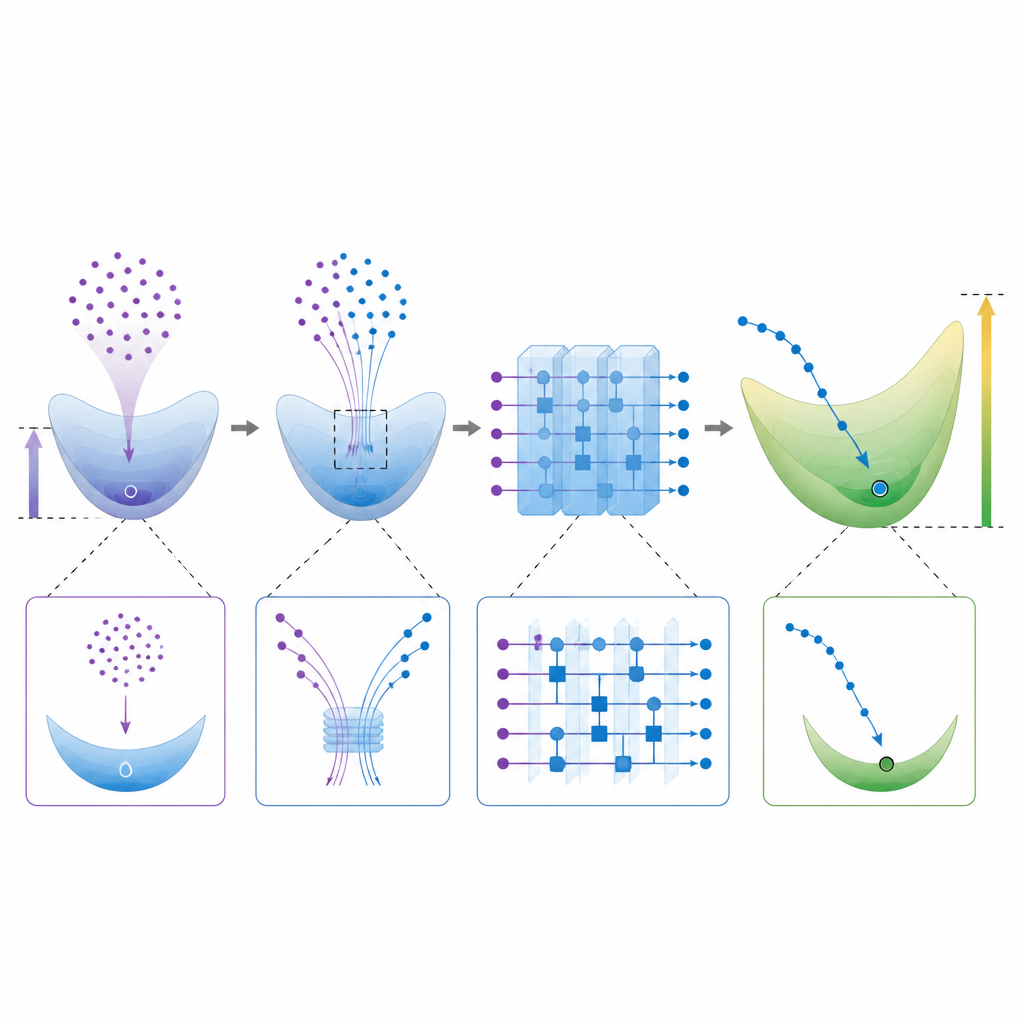
Att balansera uttrycksfull kraft och praktisk tränbarhet Figure 2. Steg-för-steg-beskrivning av hur en kvantkrets hittar en annan högdimensionell lösning än en klassisk inlärningsalgoritm
Att driva kvantmodeller mot stora viktvektorer har en hake. Mycket uttrycksfulla slumpkretsar lider ofta av ”koncentration”, där utsignaler och träningssignaler blir nästan platta, vilket gör inlärningen opraktiskt långsam. Författarna analyserar denna spänning och konstruerar familjer av matematiska funktioner som både ligger långt från den klassiska minsta norm-lösningen och ändå varierar tillräckligt för att vara användbara. De erbjuder också ett praktiskt sätt att uppskatta storleken på den kvantiska viktvektorn direkt från kretsvärderingar, vilket ger experimentutövare ett verktyg för att kontrollera om en tränad krets sannolikt kan undvika klassisk imitation.
Vad detta betyder för kvantfördelen
Arbetet påstår inte att kvantmodeller automatiskt överträffar klassiska. Istället erbjuder det tydliga villkor som visar när en kvantlärmodell inte billigt kan ersättas av en klassisk approximation som använder samma funktioner. Genom att knyta potentiell fördel till hur långt den kvantiska lösningen ligger från den klassiska minsta norm-valet, och genom att lyfta fram rollen för funktionsrymdens storlek och koncentrationseffekter, skissar artikeln en färdplan för att utforma framtida kvantkretsar som inte bara är olika de klassiska modellerna utan potentiellt mer användbara.
Citering: Thabet, S., Monbroussou, L., Mamon, E.Z. et al. When quantum and classical models disagree: learning beyond minimum norm least square.
npj Quantum Inf12, 81 (2026). https://doi.org/10.1038/s41534-026-01217-y