Clear Sky Science · ja
量子モデルと古典モデルが対立する時:最小ノルム最小二乗を超えた学習
なぜ将来の計算機にとって重要か
量子コンピュータへの多くの期待は、従来の機械では到達できない方法でデータから学習できるという考えに基づいている。しかし古典アルゴリズムが賢くなるにつれ、提案されたいくつかの量子優位性は消え失せる。この記事は核心的な問いを投げかける:量子学習モデルとそれに最適な古典的コピーが食い違うとき、その不一致は真の利得を示すのか、それとも幻にすぎないのか?
同じパターンを追う二種類の学習者
著者らは変分量子回路から構成される人気のある量子機械学習モデルの一群を研究する。これらの回路はデータを取り込み、量子状態へエンコードし、予測に相当する出力を測定する。数学的には、量子モデルも適切に選ばれた古典モデルも、同じ特徴群に作用する単純な線形式として見ることができる。その共有された構造ゆえに、量子モデルの挙動を真似ようとする「代理」の古典モデルで置き換えることが魅力的に思え、量子ハードウェアが本当に必要かどうかに疑問を投げかける。
古典的近道が通用しなくなる点 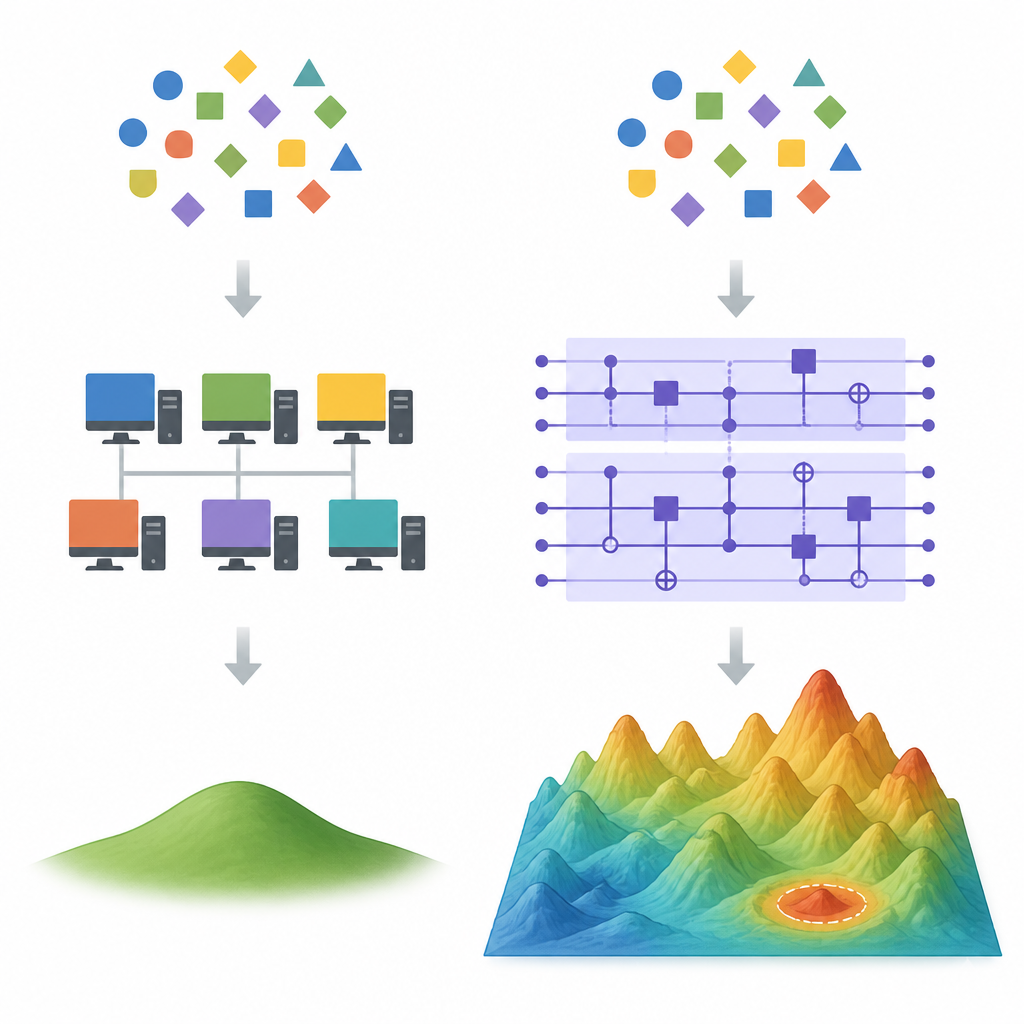
Figure 1. 同じデータに対して多くの異なるフィットが可能な場合に、量子と古典の学習モデルがどのように分岐するか
高次元の設定では、同じ訓練データに完全に適合する多くの異なる式が存在する。勾配降下法のような古典的学習法はしばしば一つの特別な解を好む:全体の重みが最小の解、すなわち最小ノルム最小二乗解である。ランダムフィーチャー法と呼ばれる強力な古典手法は、この好まれる解を完全モデルよりずっと少ない特徴で近似でき、しばしば量子装置が持つかもしれない速度や精度の優位性を消してしまう。著者らは、量子モデルが実質的に同じ小さな重みの解に落ち着くなら、そのような脱量子化手法がうまく機能する可能性が高いことを示す。
真の量子差分のためのレシピ
中心となる提案は、量子モデルの重みベクトルの大きさに注目することだ。訓練が成功した後で、量子の重みが古典の最小ノルム解のそれよりはるかに大きければ、両者は予測器としての空間で大きく離れているはずである。この場合、ランダムフィーチャーに基づく古典的代理は、良く一般化しつつ量子モデルを追跡することが容易ではない。論文はフーリエ様成分から作られる一般的な量子フィーチャーマップや、いわゆる再アップロード回路に対してこの考えを展開し、量子学習者が既に古典を凌駕する暗号学からの既存例とも結びつける。
表現力と実際の学習可能性のバランス 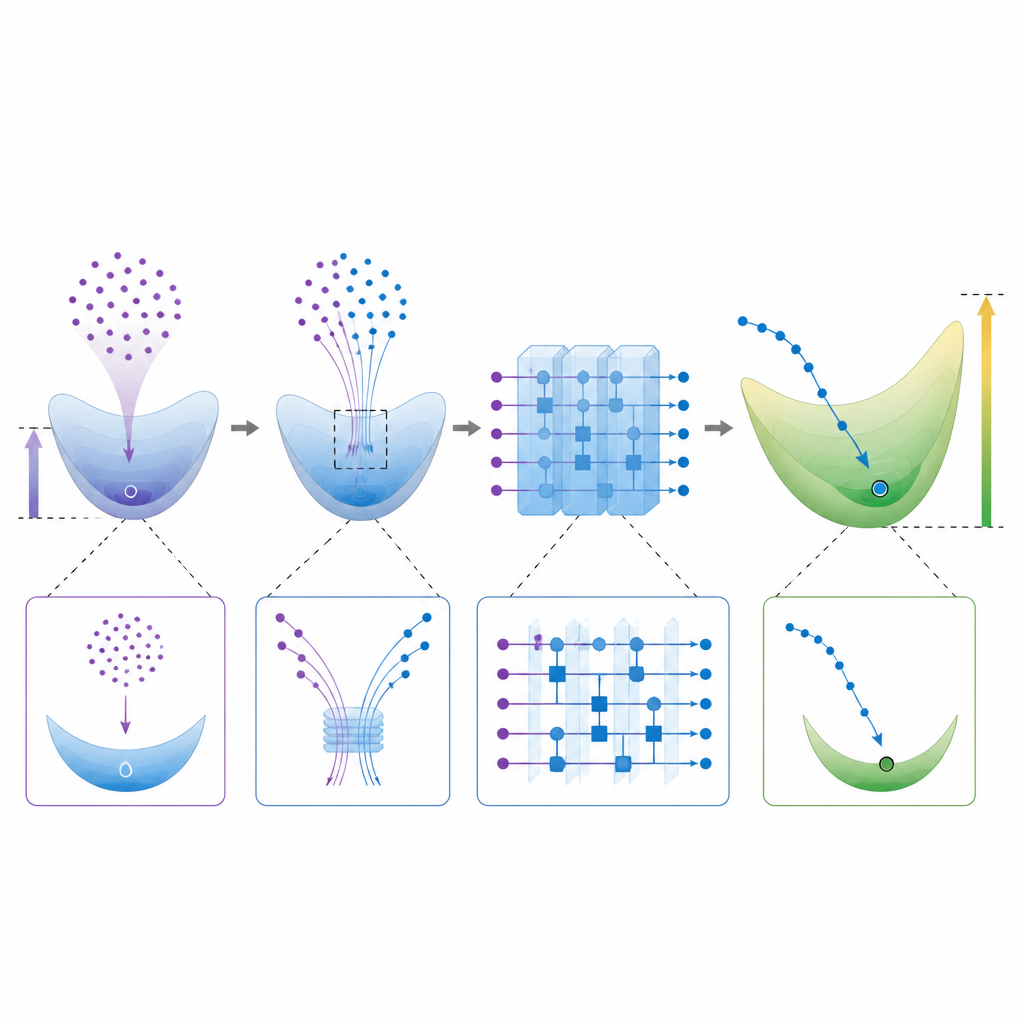
Figure 2. 古典的学習器とは異なる高次元の解を量子回路が見つける過程を段階的に見る
量子モデルを大きな重みベクトルへ押しやるには落とし穴がある。非常に表現力の高いランダム回路はしばしば「収束(concentration)」を起こし、出力や学習信号がほとんど平坦になって学習が実用的に遅くなる。著者らはこの緊張関係を解析し、古典の最小ノルム解から遠く、かつ有用な変動を保つ関数族を構成する。また、回路評価から直接量子重みベクトルの大きさを推定する実用的な方法を示し、実験者が訓練済み回路が古典的模倣を逃れ得るかどうかを確認する手段を提供する。
量子的優位性にとっての意味
本研究は量子モデルが自動的に古典より優れると主張するものではない。むしろ、量子学習モデルが同じ特徴を使った古典的近似で安価に置き換えられない場合の明確な条件を提示する。潜在的な優位性を、量子解が古典の最小ノルム選択からどれだけ離れているかに結びつけ、特徴空間の大きさや収束効果の役割を強調することで、単に古典と異なるだけでなく、将来的により有用となり得る量子回路を設計するためのロードマップを描いている。
引用: Thabet, S., Monbroussou, L., Mamon, E.Z. et al. When quantum and classical models disagree: learning beyond minimum norm least square. npj Quantum Inf 12, 81 (2026). https://doi.org/10.1038/s41534-026-01217-y
キーワード: 量子機械学習, 変分量子回路, ランダムフィーチャー, 古典的代理モデル, 量子優位性