Many hopes for quantum computers rest on the idea that they will learn from data in ways that ordinary machines cannot. But as classical algorithms get smarter, some proposed quantum advantages disappear. This article asks a pointed question: when a quantum learning model and its best classical copy disagree, can that disagreement signal a real gain, or is it just a mirage?
Two kinds of learners chasing the same pattern
The authors study a popular family of quantum machine learning models built from variational quantum circuits. These circuits take data, encode it into quantum states, and then measure an output that acts like a prediction. Mathematically, both the quantum model and a suitably chosen classical model can be viewed as simple linear formulas acting on the same set of features. That shared structure makes it tempting to replace the quantum model by a “surrogate” classical one that tries to mimic its behavior, raising doubts about whether quantum hardware is really needed.
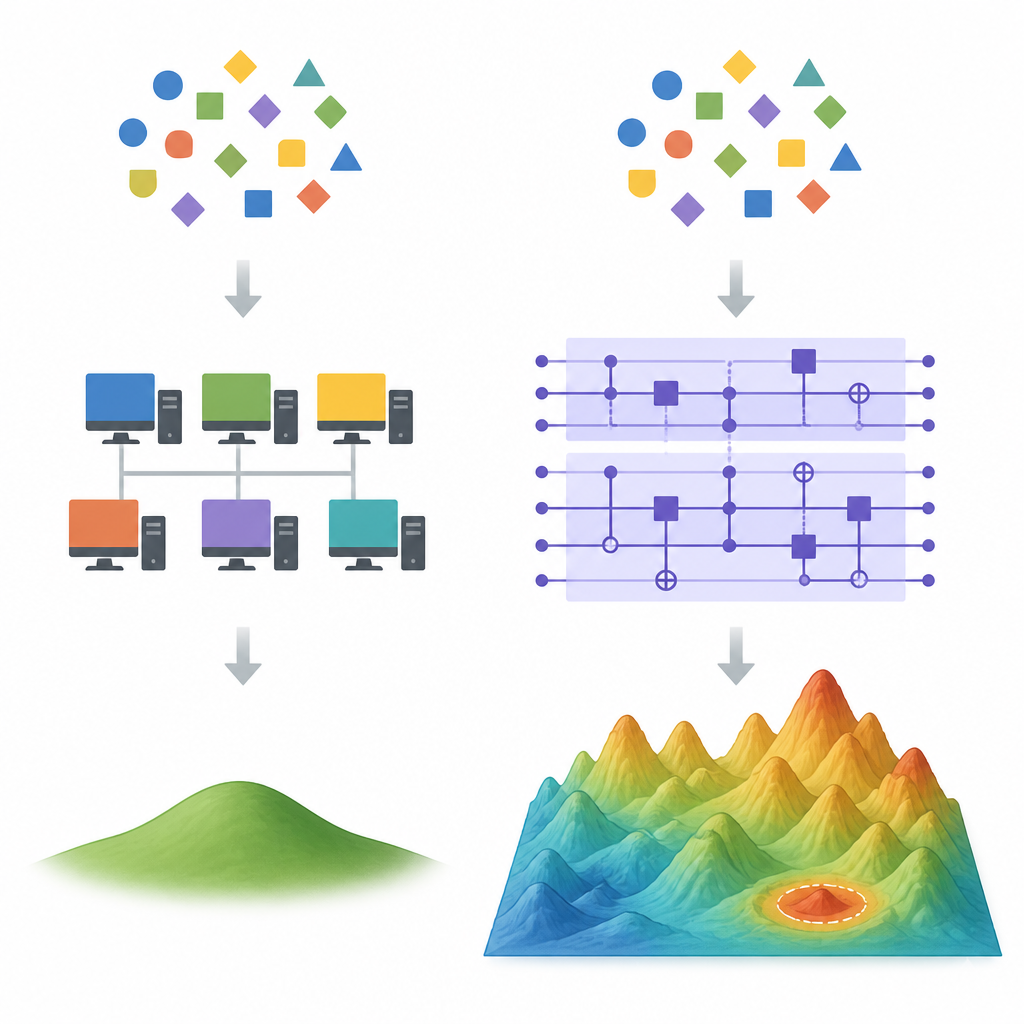
Where classical shortcuts start to fail Figure 1. How quantum and classical learning models diverge when many different fits to the same data are possible
In high dimensional settings, there are many different formulas that fit the same training data perfectly. Classical learning methods such as gradient descent tend to favor one special solution: the one with the smallest overall weight, known as the minimum norm least squares choice. Powerful classical tricks called random feature methods can approximate this favored solution using far fewer features than the full model, which often removes any speed or accuracy edge a quantum device might have. The authors show that if a quantum model effectively lands on the same small weight solution, then such dequantization methods are likely to work well.
A recipe for genuine quantum separation
The core proposal is to look at the size of the quantum model’s weight vector. If, after successful training, the quantum weights are much larger than those of the classical minimum norm solution, the two models must sit far apart in the space of possible predictors. In this case, a classical surrogate based on random features cannot easily track the quantum model while still generalizing well. The paper develops this idea for common quantum feature maps built from Fourier like components and from so called re uploading circuits, and connects it to existing examples from cryptography in which quantum learners already outpace classical ones.
Balancing expressive power and practical trainability Figure 2. Step-by-step view of a quantum circuit finding a different high-dimensional solution than a classical learner
Pushing quantum models toward large weight vectors comes with a catch. Highly expressive random circuits often suffer from “concentration,” where outputs and training signals become nearly flat, making learning impractically slow. The authors analyze this tension and construct families of mathematical functions that are both far from the classical minimum norm solution and still vary enough to be useful. They also provide a practical way to estimate the size of the quantum weight vector directly from circuit evaluations, giving experimentalists a tool to check whether a trained circuit is likely to evade classical imitation.
What this means for the quantum edge
The work does not claim that quantum models automatically outperform classical ones. Instead, it offers clear conditions showing when a quantum learning model cannot be cheaply replaced by a classical approximation using the same features. By tying potential advantage to how far the quantum solution sits from the classical minimum norm choice, and by highlighting the role of feature space size and concentration effects, the paper sketches a roadmap for designing future quantum circuits that are not just different from classical models, but potentially more useful.
Citation: Thabet, S., Monbroussou, L., Mamon, E.Z. et al. When quantum and classical models disagree: learning beyond minimum norm least square.
npj Quantum Inf12, 81 (2026). https://doi.org/10.1038/s41534-026-01217-y