Por qué esto importa para los ordenadores del futuro
Muchas expectativas sobre los ordenadores cuánticos se basan en la idea de que aprenderán de los datos de formas que las máquinas convencionales no pueden reproducir. Pero a medida que los algoritmos clásicos mejoran, algunas ventajas propuestas para lo cuántico desaparecen. Este artículo plantea una pregunta directa: cuando un modelo de aprendizaje cuántico y su mejor réplica clásica difieren, ¿puede esa discrepancia señalar una ganancia real o es solo una ilusión?
Dos tipos de aprendices persiguiendo el mismo patrón
Los autores estudian una familia popular de modelos de aprendizaje cuántico construidos a partir de circuitos cuánticos variacionales. Estos circuitos toman datos, los codifican en estados cuánticos y luego miden una salida que funciona como predicción. Matemáticamente, tanto el modelo cuántico como un modelo clásico elegido adecuadamente pueden verse como fórmulas lineales simples que actúan sobre el mismo conjunto de características. Esa estructura compartida hace tentador reemplazar el modelo cuántico por uno clásico “sustituto” que intenta imitar su comportamiento, lo que suscita dudas sobre si realmente se necesita hardware cuántico.
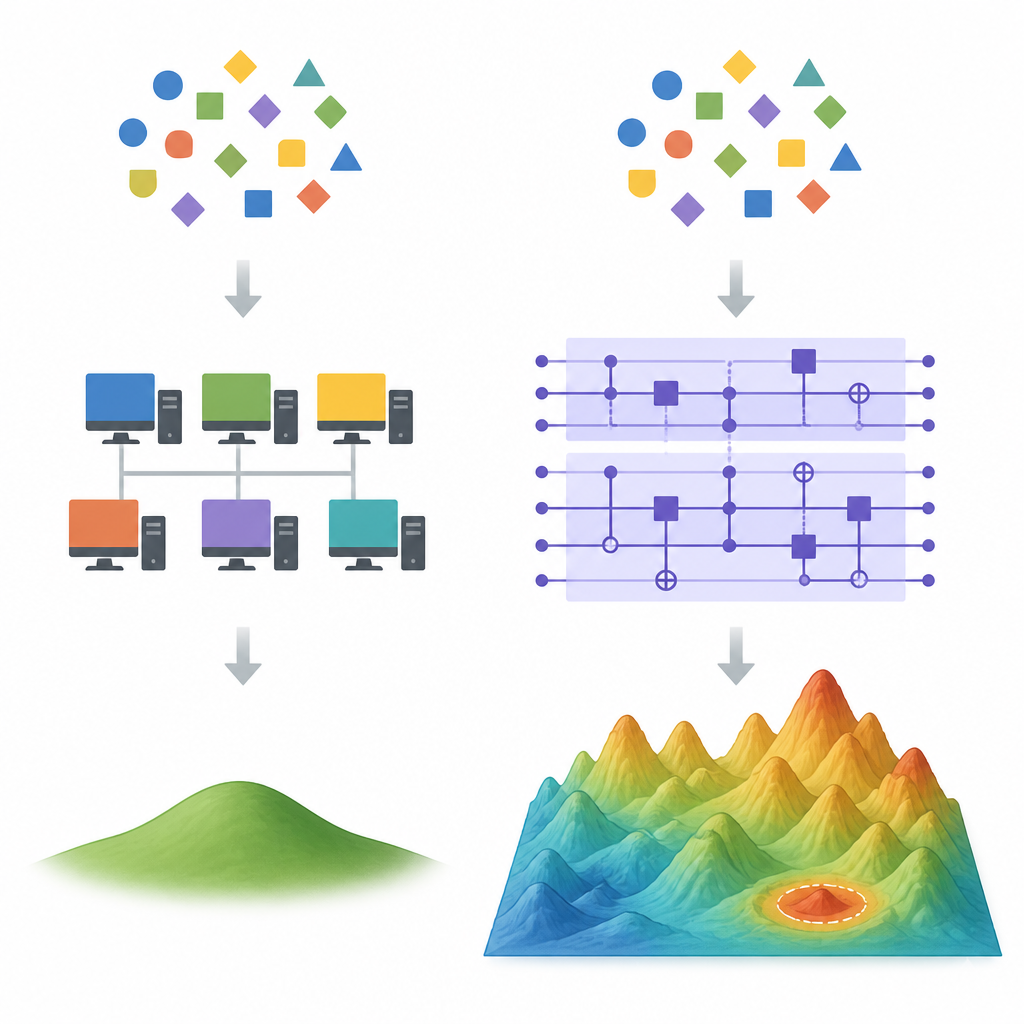
Donde los atajos clásicos empiezan a fracasar Figure 1. Cómo divergen los modelos de aprendizaje cuánticos y clásicos cuando son posibles muchas soluciones que ajustan los mismos datos
En entornos de alta dimensión hay muchas fórmulas diferentes que ajustan perfectamente los mismos datos de entrenamiento. Métodos de aprendizaje clásicos como el descenso por gradiente tienden a favorecer una solución especial: la de menor norma de los pesos, conocida como la elección de mínimos cuadrados con norma mínima. Trucos clásicos potentes, llamados métodos de características aleatorias, pueden aproximar esta solución favorecida usando muchas menos características que el modelo completo, lo que a menudo elimina cualquier ventaja en velocidad o precisión que podría tener un dispositivo cuántico. Los autores muestran que si un modelo cuántico converge efectivamente a la misma solución de pequeña norma, entonces tales métodos de descuantización probablemente funcionarán bien.
Una receta para una separación cuántica genuina
La propuesta central es fijarse en el tamaño del vector de pesos del modelo cuántico. Si, tras un entrenamiento exitoso, los pesos cuánticos son mucho mayores que los de la solución clásica de norma mínima, los dos modelos deben estar muy separados en el espacio de predictores posibles. En ese caso, un sustituto clásico basado en características aleatorias no puede seguir fácilmente al modelo cuántico manteniendo además una buena capacidad de generalización. El artículo desarrolla esta idea para mapas de características cuánticas comunes construidos a partir de componentes tipo Fourier y de los llamados circuitos de re‑carga, y la conecta con ejemplos existentes de criptografía en los que los aprendices cuánticos ya superan a los clásicos.
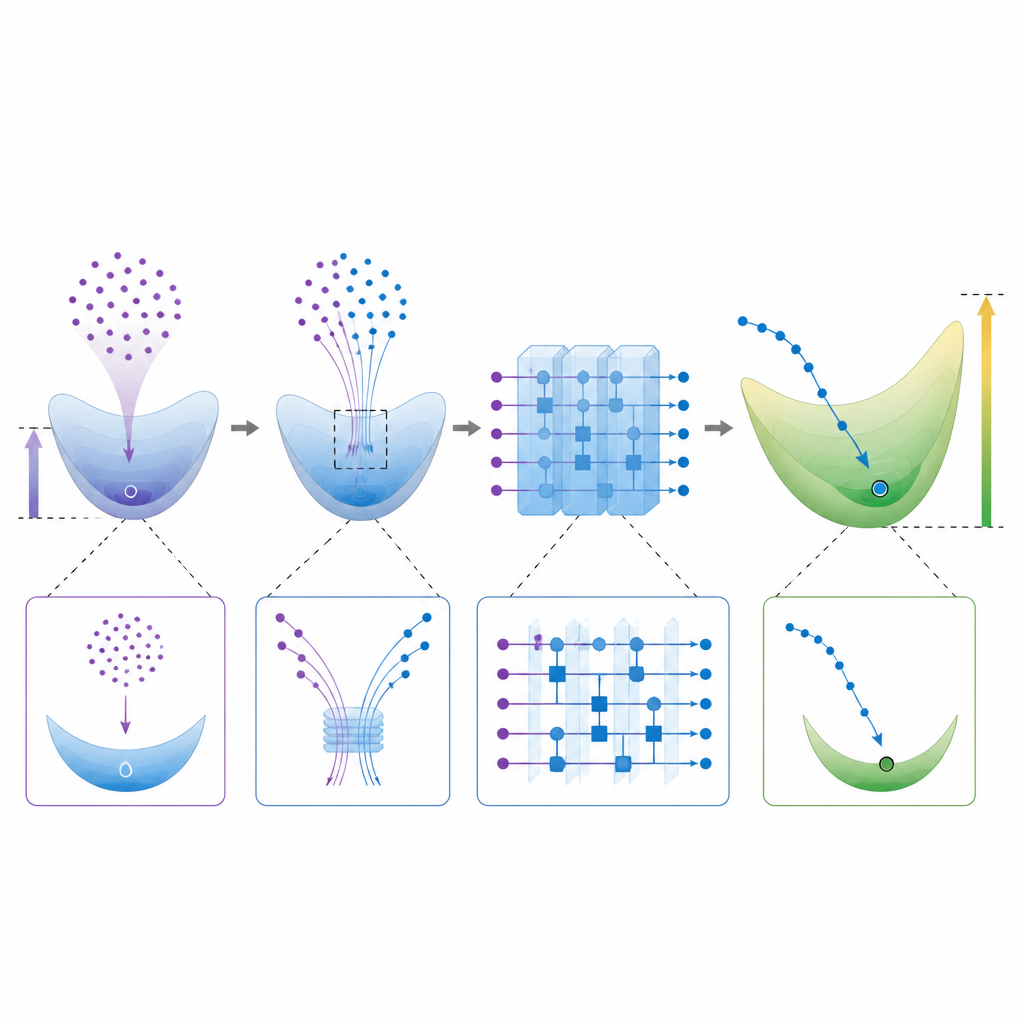
Equilibrar poder expresivo y entrenabilidad práctica Figure 2. Vista paso a paso de un circuito cuántico que encuentra una solución de alta dimensión distinta a la de un aprendiz clásico
Impulsar los modelos cuánticos hacia vectores de peso grandes tiene una contra: los circuitos aleatorios de alta expresividad suelen sufrir “concentración”, donde las salidas y las señales de entrenamiento se vuelven casi uniformes, haciendo que el aprendizaje sea imprácticamente lento. Los autores analizan esta tensión y construyen familias de funciones matemáticas que están tanto lejos de la solución clásica de norma mínima como lo suficientemente variables para ser útiles. También proporcionan una forma práctica de estimar el tamaño del vector de pesos cuántico directamente a partir de evaluaciones del circuito, dando a los experimentalistas una herramienta para comprobar si un circuito entrenado probablemente podrá evadir la imitación clásica.
Qué significa esto para la ventaja cuántica
El trabajo no afirma que los modelos cuánticos superen automáticamente a los clásicos. En su lugar, ofrece condiciones claras que muestran cuándo un modelo de aprendizaje cuántico no puede ser reemplazado de forma barata por una aproximación clásica usando las mismas características. Al relacionar la ventaja potencial con la distancia de la solución cuántica respecto a la elección clásica de norma mínima, y al destacar el papel del tamaño del espacio de características y de los efectos de concentración, el artículo bosqueja una hoja de ruta para diseñar futuros circuitos cuánticos que no solo sean distintos de los modelos clásicos, sino potencialmente más útiles.
Cita: Thabet, S., Monbroussou, L., Mamon, E.Z. et al. When quantum and classical models disagree: learning beyond minimum norm least square.
npj Quantum Inf12, 81 (2026). https://doi.org/10.1038/s41534-026-01217-y