Pourquoi cela importe pour les ordinateurs de demain
Beaucoup d’espoirs placés dans les ordinateurs quantiques reposent sur l’idée qu’ils apprendront à partir des données d’une manière que les machines ordinaires ne peuvent pas reproduire. Mais à mesure que les algorithmes classiques s’améliorent, certains des avantages proposés pour le quantique s’évanouissent. Cet article pose une question cruciale : lorsqu’un modèle d’apprentissage quantique et sa meilleure copie classique divergent, cette divergence signale-t-elle un gain réel ou n’est-ce qu’un mirage ?
Deux types d’apprenants poursuivant le même motif
Les auteurs étudient une famille populaire de modèles d’apprentissage quantique construits à partir de circuits quantiques variationnels. Ces circuits prennent des données, les encodent dans des états quantiques, puis mesurent une sortie qui sert de prédiction. Mathématiquement, le modèle quantique et un modèle classique convenablement choisi peuvent être vus comme des formules linéaires simples agissant sur le même ensemble de caractéristiques. Cette structure partagée incite à remplacer le modèle quantique par un « substitut » classique qui cherche à imiter son comportement, ce qui remet en question la nécessité réelle du matériel quantique.
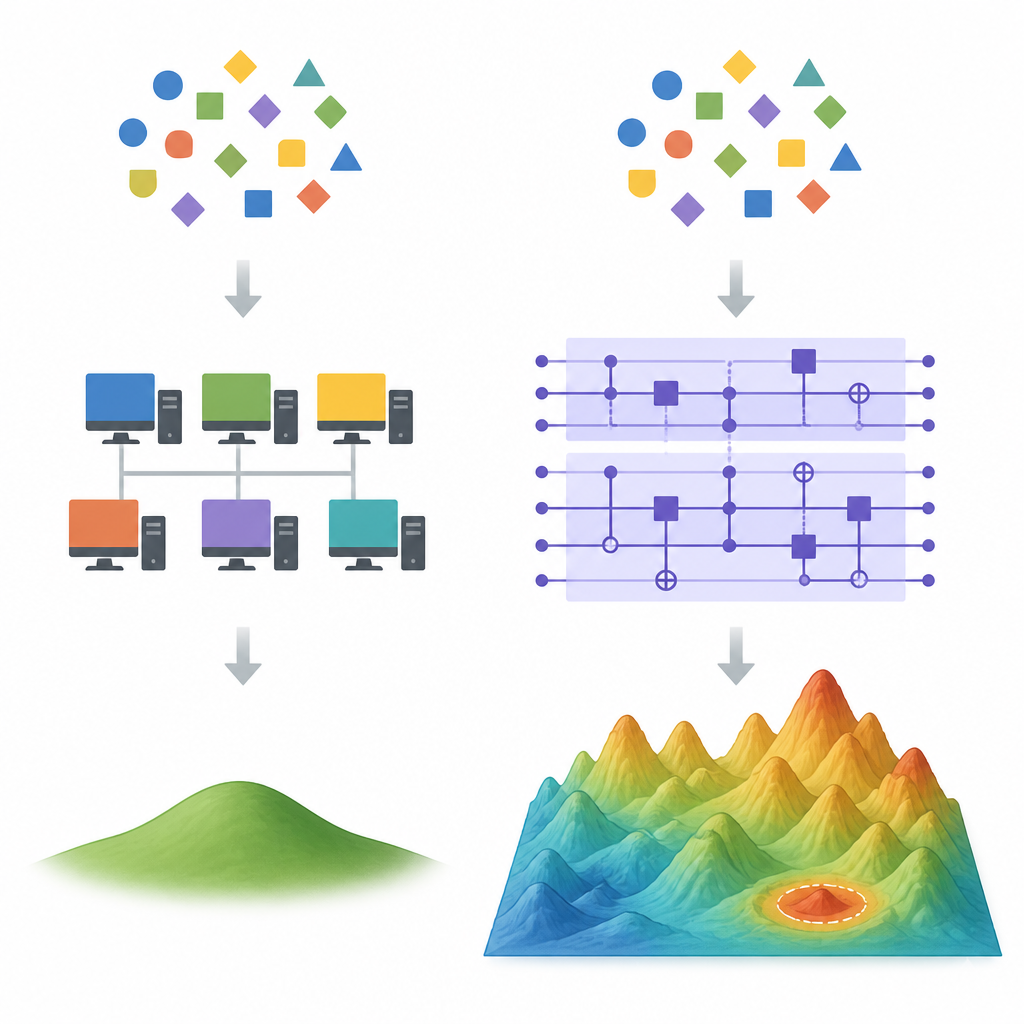
Où les raccourcis classiques commencent à échouer Figure 1. Comment les modèles d’apprentissage quantiques et classiques divergent lorsque plusieurs ajustements différents des mêmes données sont possibles
Dans des espaces de grande dimension, il existe de nombreuses formules différentes qui ajustent parfaitement les mêmes données d’entraînement. Les méthodes d’apprentissage classiques comme la descente de gradient ont tendance à favoriser une solution particulière : celle qui a le poids total le plus faible, connue sous le nom de solution des moindres carrés à norme minimale. Des astuces classiques puissantes, appelées méthodes de caractéristiques aléatoires, peuvent approcher cette solution privilégiée en utilisant beaucoup moins de caractéristiques que le modèle complet, ce qui élimine souvent tout avantage de vitesse ou de précision potentiel d’un dispositif quantique. Les auteurs montrent que si un modèle quantique aboutit effectivement à la même solution à faible norme, alors de telles méthodes de déquantalisation sont susceptibles de bien fonctionner.
Une recette pour une séparation quantique réelle
La proposition centrale consiste à examiner la taille du vecteur de poids du modèle quantique. Si, après un entraînement réussi, les poids quantiques sont beaucoup plus grands que ceux de la solution classique à norme minimale, les deux modèles doivent être très éloignés dans l’espace des prédicteurs possibles. Dans ce cas, un substitut classique basé sur des caractéristiques aléatoires ne peut pas facilement suivre le modèle quantique tout en généralisant bien. L’article développe cette idée pour des cartes de caractéristiques quantiques courantes construites à partir de composantes de type Fourier et de circuits dits de ré-encodage, et la relie à des exemples existants issus de la cryptographie où des apprenants quantiques surpassent déjà les classiques.
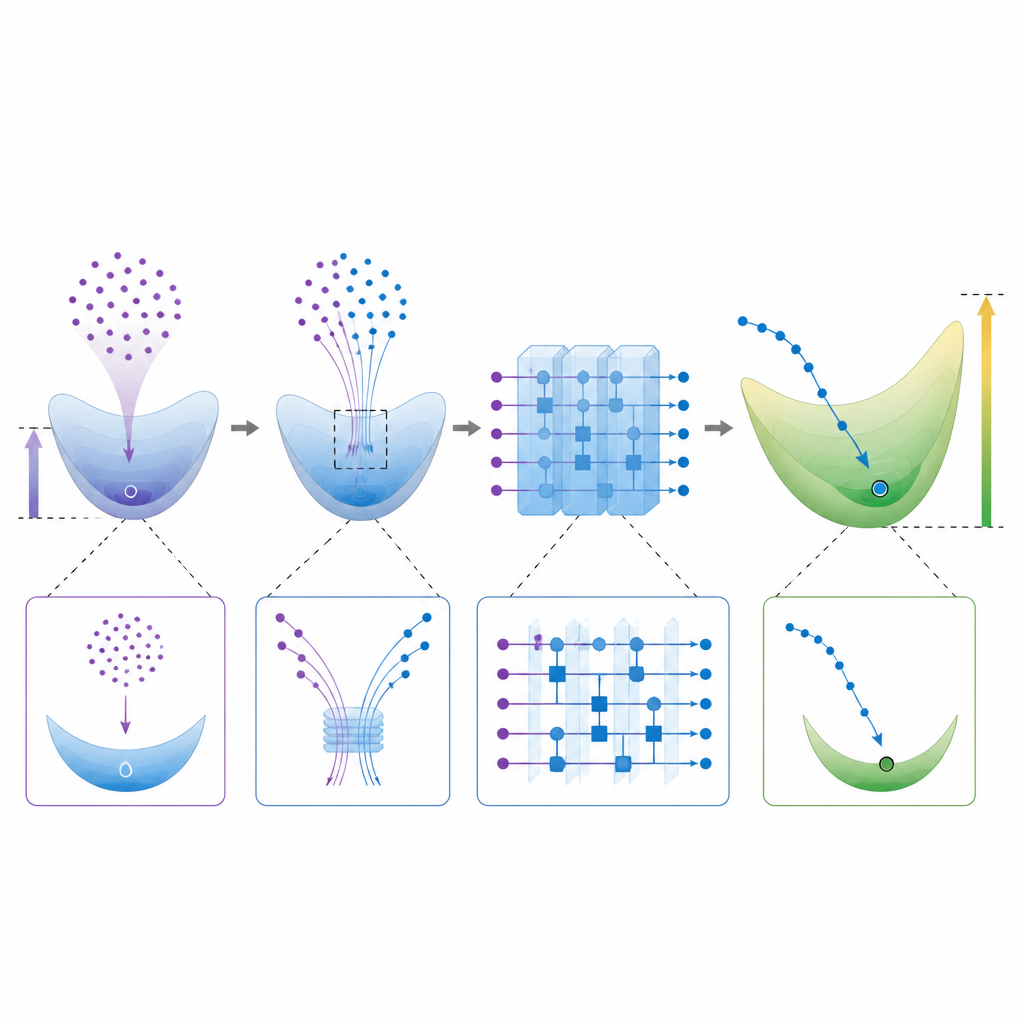
Concilier pouvoir expressif et entraînabilité pratique Figure 2. Vue pas à pas d’un circuit quantique trouvant une solution haute dimensionnelle différente de celle d’un apprenant classique
Pousser les modèles quantiques vers des vecteurs de poids de grande taille comporte un revers. Les circuits aléatoires très expressifs souffrent souvent de « concentration », où les sorties et les signaux d’entraînement deviennent presque plats, rendant l’apprentissage pratiquement impossible. Les auteurs analysent cette tension et construisent des familles de fonctions mathématiques à la fois éloignées de la solution classique à norme minimale et suffisamment variables pour être utiles. Ils proposent également une méthode pratique pour estimer la taille du vecteur de poids quantique directement à partir des évaluations de circuit, fournissant aux expérimentateurs un outil pour vérifier si un circuit entraîné est susceptible d’échapper à l’imitation classique.
Ce que cela signifie pour l’avantage quantique
Le travail n’affirme pas que les modèles quantiques surpassent automatiquement les modèles classiques. Il offre plutôt des conditions claires montrant quand un modèle d’apprentissage quantique ne peut pas être aisément remplacé par une approximation classique utilisant les mêmes caractéristiques. En reliant l’avantage potentiel à la distance entre la solution quantique et le choix classique à norme minimale, et en mettant en évidence le rôle de la taille de l’espace de caractéristiques et des effets de concentration, l’article esquisse une feuille de route pour concevoir des circuits quantiques futurs qui ne se contentent pas d’être différents des modèles classiques, mais qui sont potentiellement plus utiles.
Citation: Thabet, S., Monbroussou, L., Mamon, E.Z. et al. When quantum and classical models disagree: learning beyond minimum norm least square.
npj Quantum Inf12, 81 (2026). https://doi.org/10.1038/s41534-026-01217-y