Clear Sky Science · tr
Beyin esinli sinaptik transistörler ile uygunluk izi kullanarak yerinde zıplamalı pekiştirmeli öğrenme
Beyinden İlham Alan Daha Akıllı Makinalar
Bugünün akıllı makineleri oyunlarda insanları yenebiliyor ve araç kullanmaya yardımcı olabiliyor, ancak bu algoritmaları çalıştıran donanım hâlâ beynin öğrenme biçiminden uzak. Bu makale, ödüller ve hatalardan öğrenmek için gerçek sinapsların kullandığı birkaç temel hileyi taklit eden yeni bir tür küçük elektronik aygıt sunuyor. Bu sinaps benzeri transistörleri basit bir ağa yerleştirerek, araştırmacılar küçük bir robot arabanın hacimli, çok güç tüketen bilgisayarlara ihtiyaç duymadan şeridinde etkin biçimde kalmayı öğrenebileceğini gösteriyor.
Ödüle Dayalı Öğrenmenin Önemi
Modern yapay zekânın çoğu, bir ağdaki bağlantıları yalnızca giriş ve çıkış verilerine dayanarak ayarlar. Oysa hayvanlar sadece örneklerden değil, aynı zamanda yiyecek veya haz gibi ödüllerle işaretlenen başarı ve başarısızlıklardan da öğrenir. Sinirbilimciler bunu “pekiştirmeli öğrenme” ile modelleyerek, dopamin gibi beyin içi özel kimyasalların sinapslara yakın zamanda yapılan bir eylemin iyi mi kötü mü olduğunu bildirdiğini öne sürer. Uygunluk izi (eligibility trace) olarak adlandırılan ilgili bir fikir, bir sinapsın yakın zamandaki etkinliği geçici olarak “hatırlamasına” izin vererek daha sonra gelen bir ödülün hâlâ o bağlantıyı uygun şekilde güçlendirmesini veya zayıflatmasını sağlar. Bu özelliklerin tümünü doğrudan donanımda yeniden üretmek, öğrenen makineleri daha hızlı ve çok daha enerjiverimli hale getirebilir.
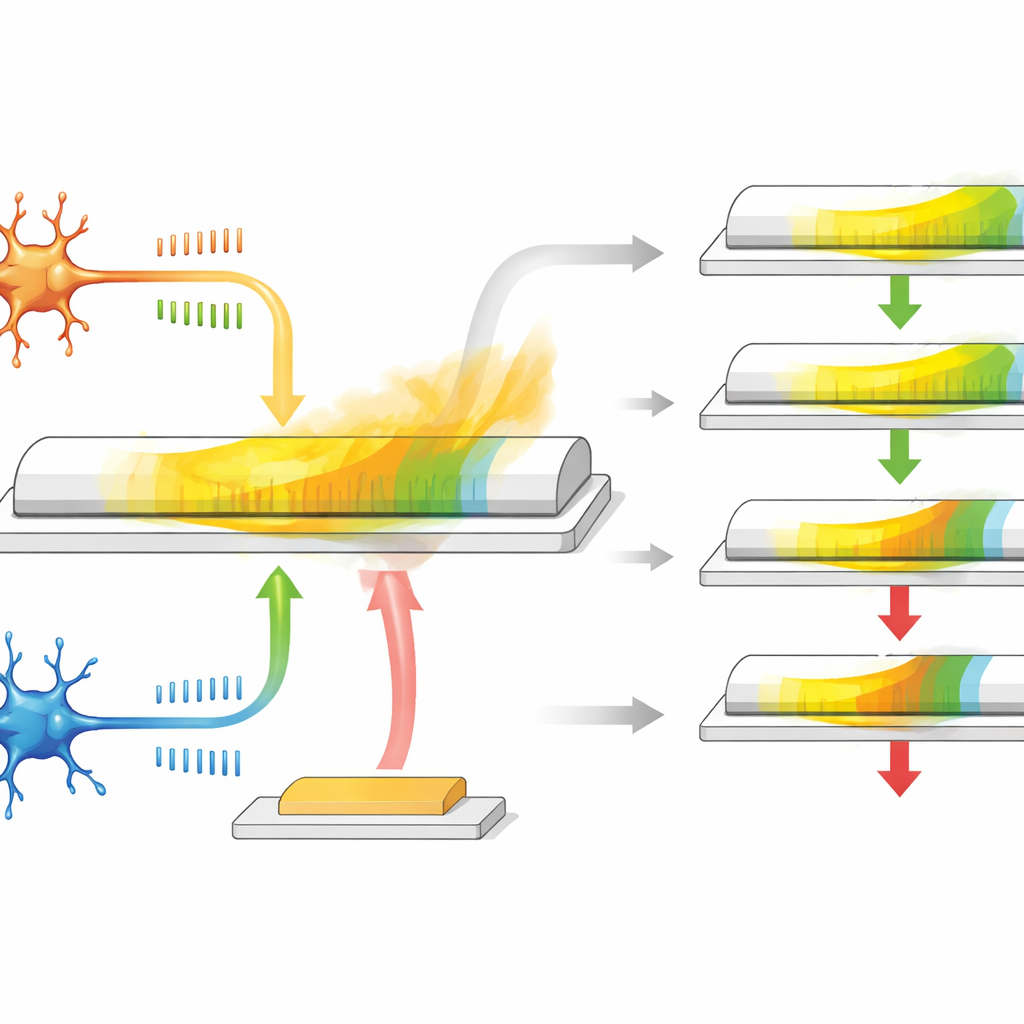
Sinaps Gibi Davranan Tek Bir Transistör
Yazarlar, hem yarıiletken hem de ferroelektrik olan ve iç elektrik polarizasyonu ters çevrilebilen ve bu şekilde kalabilen α-In2Se3 adlı özel bir malzemeye dayanan bir sinaptik transistör geliştiriyorlar. Cihaz üç terminale sahip: ikisi bir sinapsın pre- ve post-nöron uçları gibi davranırken üçüncüsü ödül girişi olarak işlev görüyor. İlk iki terminal arasında zıplama benzeri voltaj darbeleri uygulandığında kanalın iletkenliği değişerek bir sinapsın zıplama zamanlamasına bağlı olarak nasıl güçlenip zayıfladığını taklit ediyor. Malzemenin polarizasyonu zamanla yavaşça gevşediği için iletkenlik doğal olarak geri sürükleniyor; bu da uygunluk izi yerine geçen yerleşik, yavaşça solan bir hafıza sağlıyor.
Ödül ve Hafızayı Fiziksel Olarak İnşa Etmek
Bu transistör yalnızca bir değer depolamaktan daha fazlasını yapıyor. Yatay (in-plane) polarizasyon öncelikle iki nöron arasındaki olağan zamanlama tabanlı öğrenmeyi temsil eden sinyallere yanıt verirken, dikey (out-of-plane) polarizasyon üçüncü terminalde uygulanan darbelerde daha güçlü yanıt vererek ödül sinyaline karşılık geliyor. Zıplama etkinliğinin ardından gelen gevşeme döneminde, kapıya ulaşan gecikmeli bir ödül darbesi kalan iletkenlik değişimini ya güçlendiriyor ya da azaltıyor. Ödül hızlı gelirse, uygunluk izi henüz fazla bozulmamış olduğundan ağırlık güncellemesi büyük oluyor; ödül geç gelirse etkinin büyüklüğü azalıyor. Elektrik darbelerinin boyutunu ve şeklini ayarlayarak araştırmacılar uygunluk izinin ne kadar sürdüğünü ayarlayabiliyor; bu süre biyolojik sistemlere benzer bir aralığı kapsıyor ve ek devreler veya hafıza elemanları gerektirmiyor.
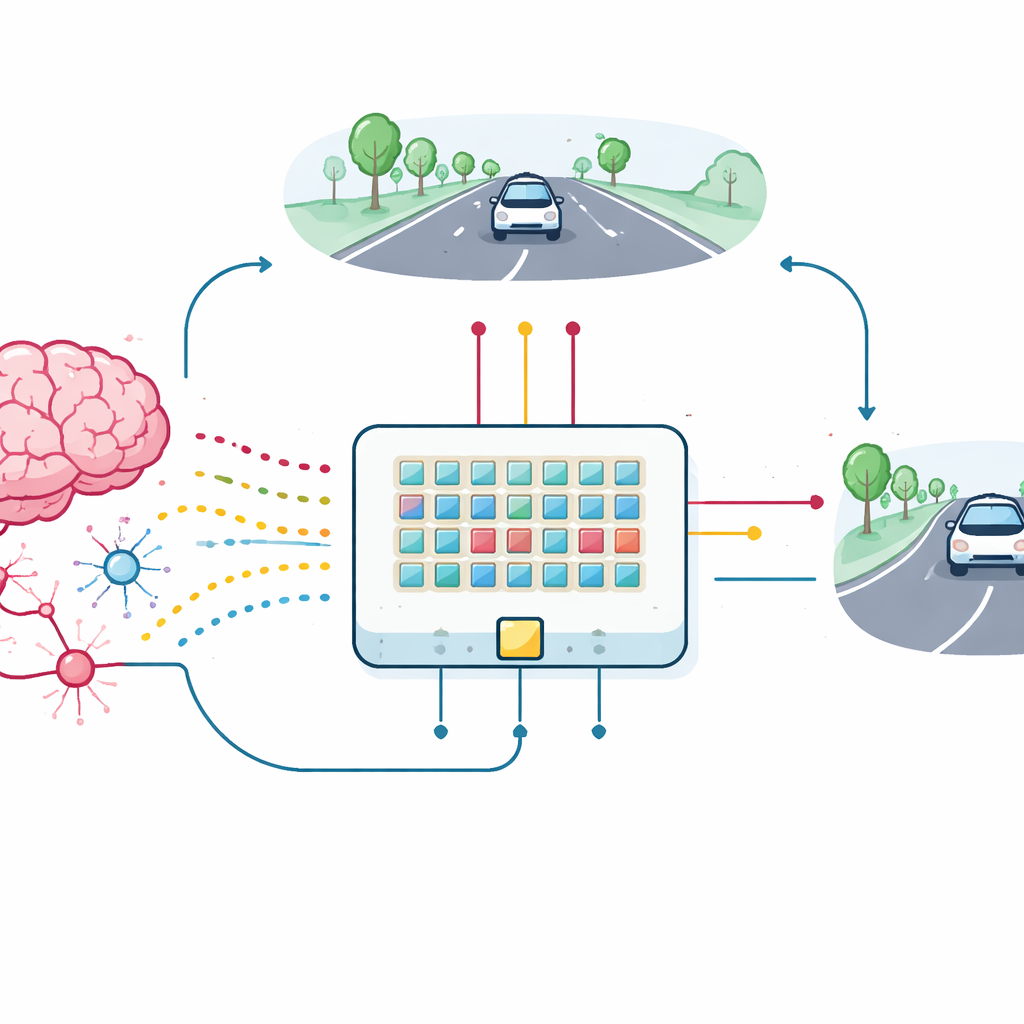
Tek Cihazdan Öğrenen Arabaya
Bu sinaptik transistörlerin pratik değerini test etmek için ekip, bir dizi cihaz inşa ederek bunları şerit tutma görevine yönelik bir zıplamalı sinir ağına bağladı. Yolun basit, düşük çözünürlüklü bir görünümü 18 giriş nöronuna giren zıplama patlamalarına dönüştürülüyor; bunlar yeni sinapslardan geçerek sola ve sağa direksiyon kontrolünü yapan iki çıkış nöronuna bağlıyor. Simüle edilen araba dolaştıkça, şeritte ne kadar ortalanmış kaldığına göre geribildirim alıyor. Bu geribildirim, sinaptik transistörlerin üçüncü terminallerine iletilen ödül darbelerine dönüştürülerek çip üzerinde iletkenliklerini doğrudan güncelliyor. Cihaz varyasyonları ve gürültüye rağmen dizi, yazılımdaki ideal bir modelin performansına yakın şekilde arabayı şeridinde tutmayı öğreniyor.
Gelecek Aygıtlar İçin Anlamı
Çalışma, tek ve kompakt bir transistörün beyin benzeri pekiştirmeli öğrenme için üç temel işlevi doğal olarak gerçekleştirebileceğini gösteriyor: sinaptik gücün zamanlama tabanlı ayarlanması, yakın zamandaki etkinliğin uygunluk izi olarak geçici depolanması ve bu iz üzerinde ödül odaklı güçlendirme ya da bastırma. Tüm bunların cihazın kendi malzeme fiziği içinde gerçekleşmesi sayesinde, ortaya çıkan donanım aynı davranışı yazılımla simüle eden geleneksel devrelere kıyasla alan ve enerji açısından büyük tasarruf vaat ediyor. Bu tür sinaptik transistörler, etkileşim yoluyla gerçek zamanlı öğrenen ve çok düşük güç tüketen küçük robotlar, sensörler veya giyilebilirler gibi geleceğin uç (edge) cihazlarının temelini oluşturabilir.
Atıf: Wang, Y., Xiong, W., Yan, J. et al. Brain-inspired synaptic transistors for in-situ spiking reinforcement learning with eligibility trace. Nat Commun 17, 3001 (2026). https://doi.org/10.1038/s41467-026-69898-9
Anahtar kelimeler: nöromorfik donanım, pekiştirmeli öğrenme, zıplamalı sinir ağları, ferroelektrik transistörler, otonom sürüş