Clear Sky Science · ru
Синаптические транзисторы, вдохновлённые мозгом, для встроенного спайкингового обучения с подкреплением и следом допустимости
Более умные машины, вдохновлённые мозгом
Современные умные машины могут обыгрывать людей в играх и помогать водить автомобили, но аппаратное обеспечение, на котором работают эти алгоритмы, всё ещё сильно отличается от того, как учится мозг. В этой статье представлен новый тип миниатюрного электронного устройства, которое копирует несколько ключевых приёмов реальных синапсов мозга для обучения на основе вознаграждений и ошибок. Встроив такие синапсоподобные транзисторы в простую сеть, исследователи показали, что небольшой робот‑автомобиль может эффективно научиться держаться в полосе, не полагаясь на громоздкие и энергозатратные компьютеры.
Почему обучение на основе вознаграждений важно
Большая часть современной искусственной интеллекта меняет связи в сети, опираясь только на входные и выходные данные. В отличие от этого, животные учатся не только по паттернам, но и по успехам и неудачам, сигнализируемым вознаграждениями — например едой или приятными ощущениями. Нейробиологи моделируют это с помощью «обучения с подкреплением», где специальные химические вещества в мозге, такие как дофамин, сообщают синапсам, было ли недавнее действие полезным или вредным. Родственная идея — след допустимости (eligibility trace) — позволяет синапсу временно «запомнить» недавнюю активность, чтобы более позднее вознаграждение всё ещё могло усилить или ослабить это соединение соответствующим образом. Репликация всех этих свойств непосредственно в аппаратуре может сделать обучающиеся машины быстрее и значительно экономичнее по энергопотреблению.
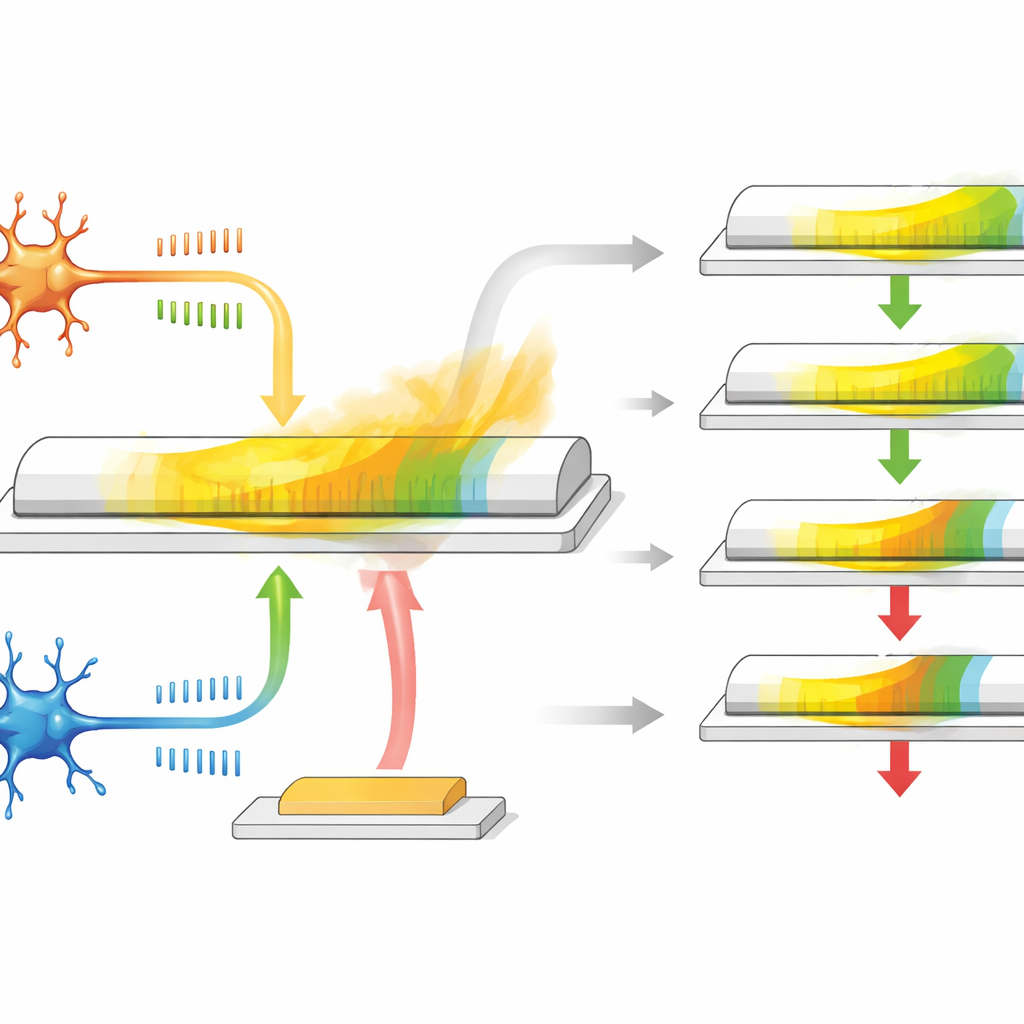
Один транзистор, действующий как синапс
Авторы разработали синаптический транзистор на основе специального материала α-In2Se3, который одновременно является полупроводником и ферроэлектриком: его внутренняя электрическая поляризация может переключаться и сохраняться. У устройства три вывода: два ведут себя как прек- и пост‑нейронные концы синапса, а третий функционирует как вход вознаграждения. Когда между первыми двумя выводами подаются импульсы напряжения, похожие на спайки, проводимость канала меняется, имитируя усиление или ослабление синапса в зависимости от временных соотношений спайков. Поскольку поляризация материала медленно релаксирует со временем, проводимость естественным образом возвращается, обеспечивая встроенную, постепенно затухающую память, которая заменяет след допустимости.
Встраивание вознаграждения и памяти в физику
Этот транзистор делает больше, чем просто хранит значение. Его внутренняя (в‑плоскости) поляризация в основном реагирует на сигналы, представляющие привычное временное обучение между двумя нейронами, тогда как вне‑плоскостная поляризация сильнее реагирует на импульсы, подаваемые на третий вывод, который служит сигналом вознаграждения. В период релаксации после спайковой активности запаздывающий импульс вознаграждения поступает на затвор и либо усиливает, либо ослабляет оставшееся изменение проводимости. Если вознаграждение приходит быстро, след допустимости ещё мало ослаблен, поэтому обновление веса велико; если вознаграждение позднее, эффект меньше. Меняя величину и форму электрических импульсов, исследователи могут настраивать продолжительность следа допустимости, охватывая диапазон, похожий на биологический, и всё это без дополнительных схем или элементов памяти.
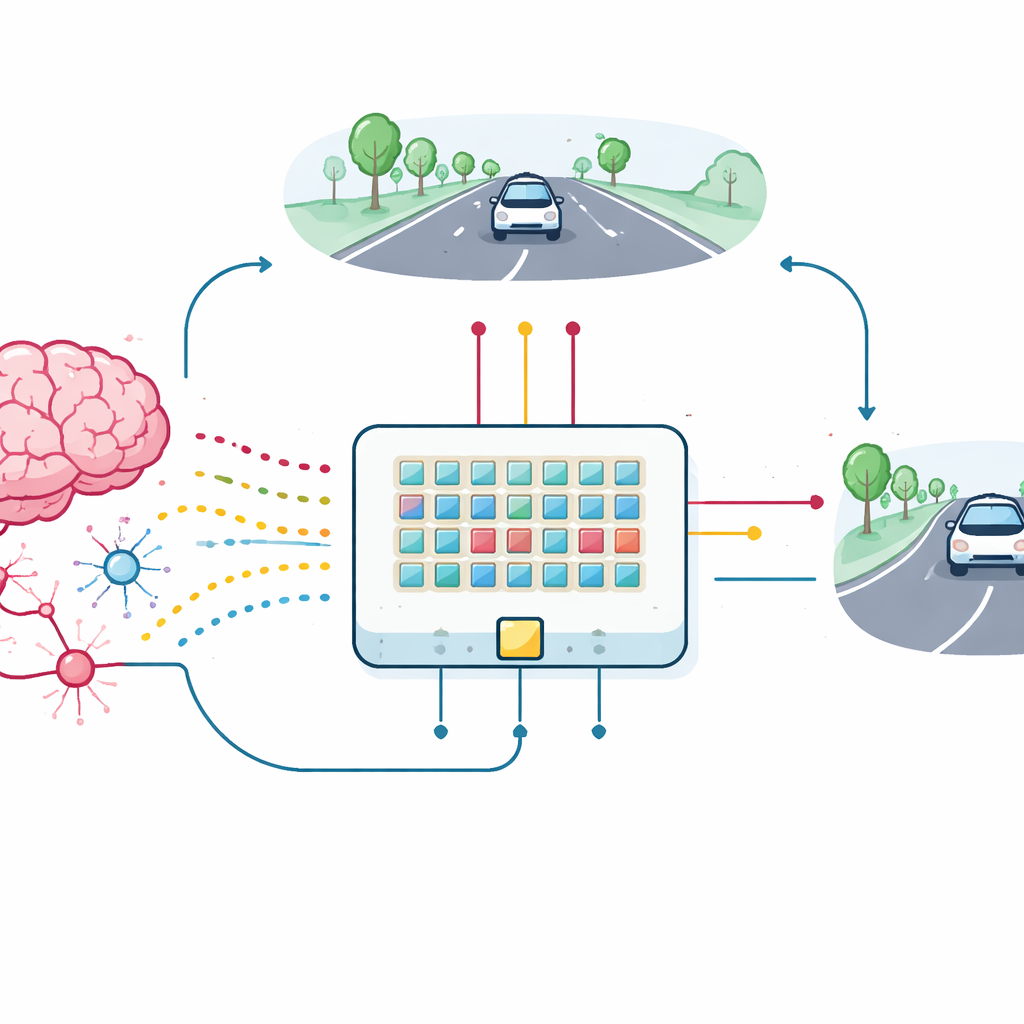
От одного устройства к обучающемуся автомобилю
Чтобы проверить практическую ценность этих синаптических транзисторов, команда собрала небольшой массив устройств и подключила их в спайкинговую нейронную сеть для задачи удержания в полосе. Простое, низкографическое представление дороги впереди преобразуется в всплески спайков, поступающие в 18 входных нейронов, которые через новые синапсы соединяются с двумя выходными нейронами, управляющими поворотом влево и вправо. По мере того как смоделированный автомобиль отклоняется, он получает обратную связь на основе того, насколько хорошо держится в центре полосы. Эта обратная связь преобразуется в импульсы‑вознаграждения, которые идут к третьим выводам синаптических транзисторов, обновляя их проводимость прямо на кристалле. Массив, даже с вариациями устройств и шумом, учится удерживать автомобиль в полосе, демонстрируя производительность, близкую к идеальной программной модели.
Что это значит для будущих устройств
Работа показывает, что один компактный транзистор может нативно выполнять три ключевые функции для мозго‑подобного обучения с подкреплением: временную регулировку синаптической прочности, временное хранение недавней активности в виде следа допустимости и усиление или подавление этого следа под действием вознаграждения. Поскольку всё это происходит внутри собственной физики материала устройства, получаемое железо обещает значительную экономию площади и энергии по сравнению с традиционными схемами, моделирующими то же поведение в программном обеспечении. Такие синаптические транзисторы могут стать основой будущих периферийных устройств — мелких роботов, датчиков или носимых гаджетов — которые учатся во взаимодействии с окружением в реальном времени, потребляя очень мало энергии.
Цитирование: Wang, Y., Xiong, W., Yan, J. et al. Brain-inspired synaptic transistors for in-situ spiking reinforcement learning with eligibility trace. Nat Commun 17, 3001 (2026). https://doi.org/10.1038/s41467-026-69898-9
Ключевые слова: нейроморфное железо, обучение с подкреплением, спайкинговые нейронные сети, ферроэлектрические транзисторы, автономное вождение