Clear Sky Science · en
Brain-inspired synaptic transistors for in-situ spiking reinforcement learning with eligibility trace
Smarter Machines Inspired by the Brain
Today’s smart machines can beat humans at games and help drive cars, but the hardware running these algorithms is still far from how the brain learns. This paper presents a new kind of tiny electronic device that copies several key tricks used by real synapses in the brain to learn from rewards and mistakes. By building these synapse-like transistors into a simple network, the researchers show that a small robot car can learn to stay in its lane efficiently without relying on bulky, power-hungry computers.
Why Reward-Based Learning Matters
Much of modern artificial intelligence adjusts connections in a network based only on input and output data. In contrast, animals learn not just from patterns, but also from success and failure signaled by rewards such as food or pleasure. Neuroscientists model this with “reinforcement learning,” where special chemicals in the brain, like dopamine, tell synapses whether a recent action was good or bad. A related idea, called an eligibility trace, lets a synapse temporarily “remember” recent activity so that a later reward can still strengthen or weaken that connection appropriately. Reproducing all of these features directly in hardware could make learning machines faster and far more energy-efficient.
A Single Transistor that Acts Like a Synapse
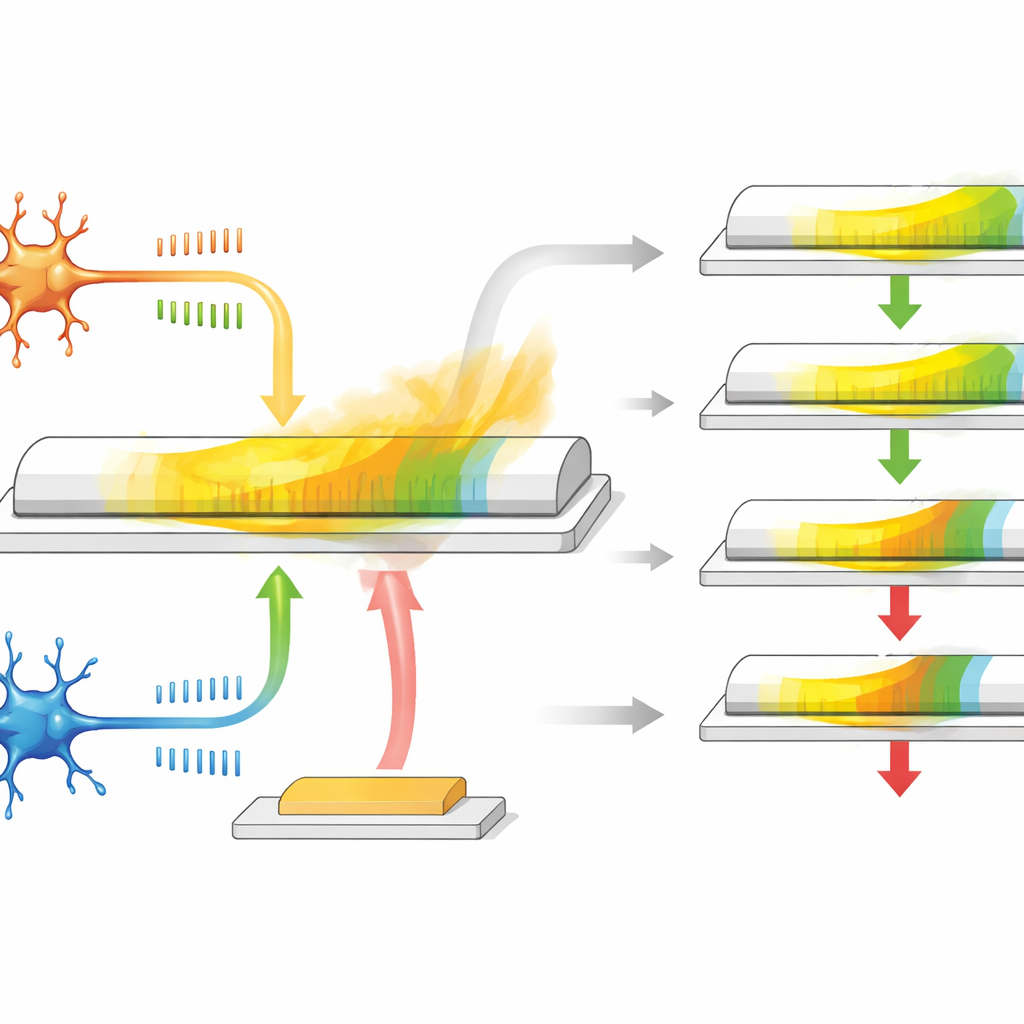
The authors develop a synaptic transistor based on a special material called α-In2Se3, which is both a semiconductor and ferroelectric, meaning its internal electric polarization can be flipped and will stay that way. The device has three terminals: two act like the pre- and post-neuron ends of a synapse, while the third behaves like a reward input. When spike-like voltage pulses are applied between the first two terminals, the conductance of the channel changes, mimicking how a synapse becomes stronger or weaker depending on spike timing. Because the material’s polarization slowly relaxes over time, the conductance naturally drifts back, providing a built-in, gradually fading memory that stands in for the eligibility trace.
Building Reward and Memory into the Physics
This transistor does more than simply store a value. Its in-plane polarization responds mainly to signals that represent the usual timing-based learning between two neurons, while the out-of-plane polarization responds more strongly to pulses applied on the third terminal, which serves as the reward signal. During the relaxation period after spike activity, a delayed reward pulse arrives at the gate and either boosts or reduces the remaining conductance change. If the reward comes quickly, the eligibility trace has not decayed much, so the weight update is large; if the reward is late, the effect is smaller. By tuning the size and shape of the electrical pulses, the researchers can adjust how long the eligibility trace lasts, covering a range similar to biological systems, all without extra circuits or memory elements.
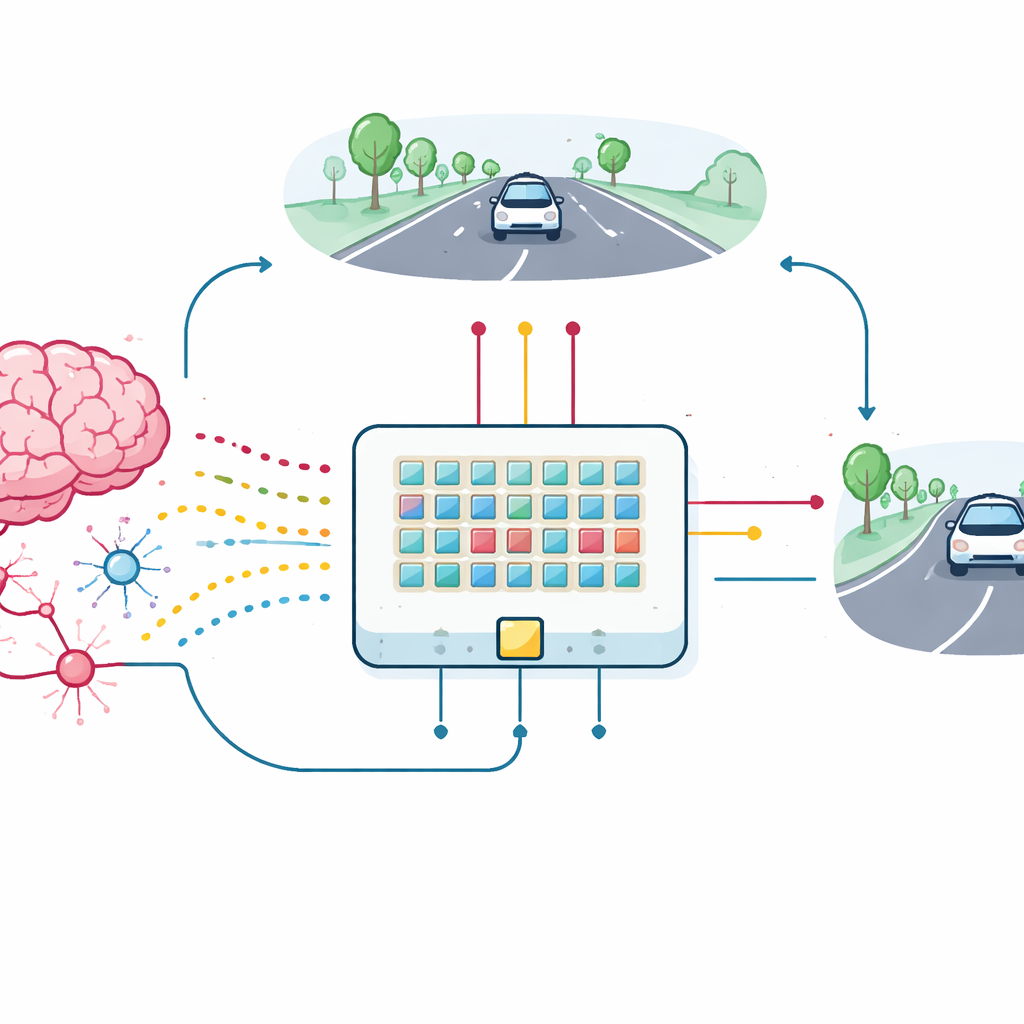
From Single Device to Learning Car
To test the practical value of these synaptic transistors, the team built a small array of devices and connected them into a spiking neural network for a lane-keeping task. A simple, low-resolution view of the road ahead is converted into bursts of spikes entering 18 input neurons, which in turn connect through the new synapses to two output neurons controlling left and right steering. As the simulated car wanders, it receives feedback based on how well it stays centered in the lane. This feedback is turned into reward pulses that travel to the third terminals of the synaptic transistors, updating their conductance directly on the chip. The array, even with device variations and noise, learns to keep the car in its lane, closely matching the performance of an ideal software model.
What This Means for Future Devices
The work shows that a single, compact transistor can natively carry out three essential functions for brain-like reinforcement learning: timing-based adjustment of synaptic strength, temporary storage of recent activity as an eligibility trace, and reward-driven reinforcement or suppression of that trace. Because all of this happens inside the device’s own material physics, the resulting hardware promises major savings in area and energy compared with conventional circuits that simulate the same behavior in software. Such synaptic transistors could form the foundation of future edge devices—like small robots, sensors, or wearables—that learn from interaction with their surroundings in real time while consuming very little power.
Citation: Wang, Y., Xiong, W., Yan, J. et al. Brain-inspired synaptic transistors for in-situ spiking reinforcement learning with eligibility trace. Nat Commun 17, 3001 (2026). https://doi.org/10.1038/s41467-026-69898-9
Keywords: neuromorphic hardware, reinforcement learning, spiking neural networks, ferroelectric transistors, autonomous driving