Clear Sky Science · it
Transistor sinaptici ispirati al cervello per apprendimento per rinforzo spike-in-situ con traccia di eleggibilità
Macchine più intelligenti ispirate al cervello
Le macchine intelligenti di oggi possono battere gli esseri umani nei giochi e aiutare a guidare le auto, ma l’hardware che esegue questi algoritmi è ancora molto distante da come il cervello apprende. Questo articolo presenta un nuovo tipo di minuscolo dispositivo elettronico che replica diversi trucchi chiave usati dalle vere sinapsi del cervello per apprendere da ricompense e errori. Integrando questi transistor simili a sinapsi in una rete semplice, i ricercatori dimostrano che una piccola automobilita robotica può imparare a mantenersi nella propria corsia in modo efficiente senza fare affidamento su computer ingombranti e energivori.
Perché l’apprendimento basato sulla ricompensa è importante
Gran parte dell’intelligenza artificiale moderna aggiusta le connessioni in una rete basandosi solo su dati di input e output. Invece, gli animali imparano non solo dai modelli, ma anche dal successo e dal fallimento segnalati da ricompense come il cibo o il piacere. I neuroscienziati modellano questo con l’“apprendimento per rinforzo”, dove sostanze chimiche speciali nel cervello, come la dopamina, dicono alle sinapsi se un’azione recente è stata buona o cattiva. Un’idea correlata, chiamata traccia di eleggibilità, permette a una sinapsi di “ricordare” temporaneamente l’attività recente in modo che una ricompensa successiva possa comunque rafforzare o indebolire quella connessione in modo appropriato. Riprodurre tutte queste caratteristiche direttamente nell’hardware potrebbe rendere le macchine apprendenti più veloci e molto più efficienti dal punto di vista energetico.
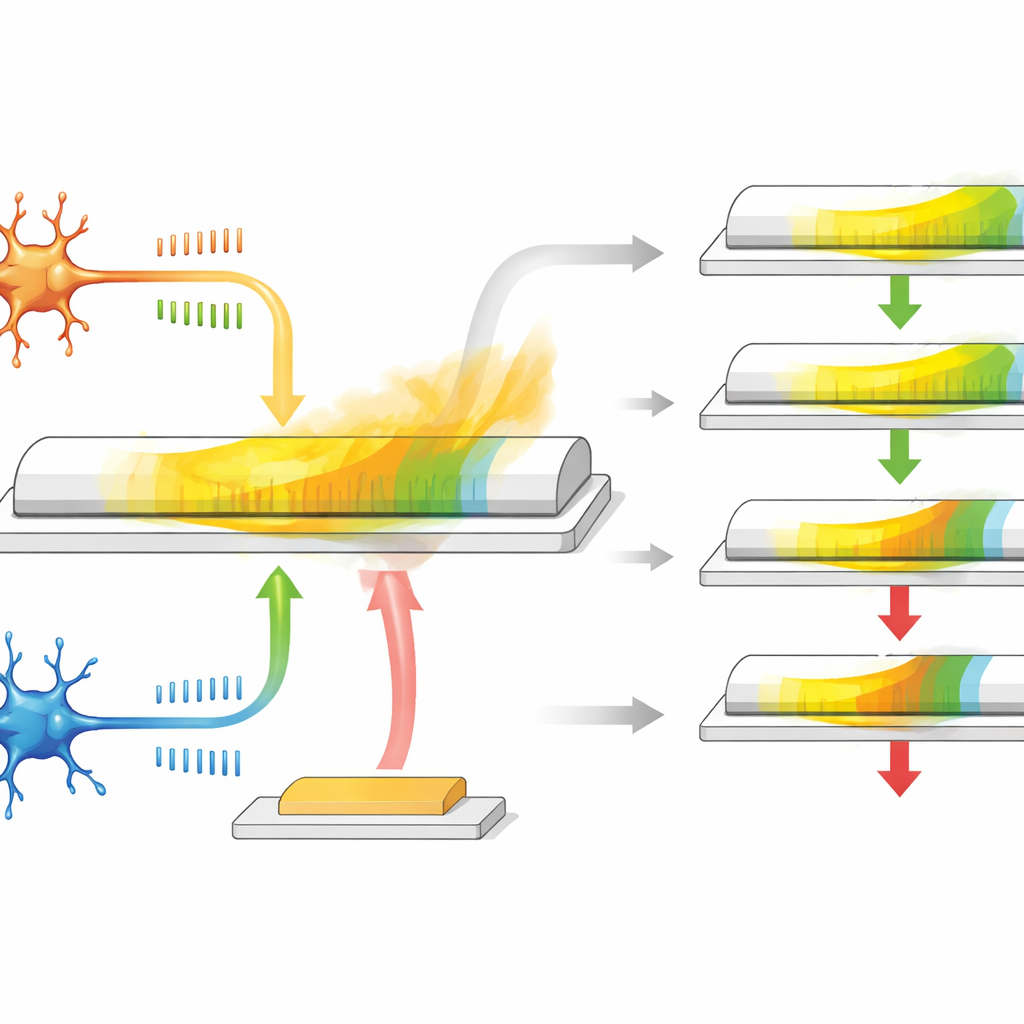
Un singolo transistor che si comporta come una sinapsi
Gli autori sviluppano un transistor sinaptico basato su un materiale speciale chiamato α-In2Se3, che è allo stesso tempo un semiconduttore e ferroelettrico, il che significa che la sua polarizzazione elettrica interna può essere invertita e rimane stabile. Il dispositivo ha tre terminali: due fungono da estremità pre- e post-neuronali di una sinapsi, mentre il terzo si comporta come un ingresso per la ricompensa. Quando tra i primi due terminali vengono applicate delle tensioni a impulsi simili a spike, la conduttanza del canale cambia, imitand o come una sinapsi si rafforza o si indebolisce a seconda della sincronizzazione degli spike. Poiché la polarizzazione del materiale si rilassa lentamente nel tempo, la conduttanza tende naturalmente a ritornare, fornendo una memoria intrinseca e gradualmente decadente che rappresenta la traccia di eleggibilità.
Integrare ricompensa e memoria nella fisica del dispositivo
Questo transistor fa più che memorizzare un valore. La sua polarizzazione in piano risponde principalmente ai segnali che rappresentano il consueto apprendimento basato sul timing tra due neuroni, mentre la polarizzazione fuori piano risponde più fortemente agli impulsi applicati sul terzo terminale, che funge da segnale di ricompensa. Durante il periodo di rilassamento dopo l’attività a spike, un impulso di ricompensa ritardato arriva al gate e aumenta o riduce la variazione di conduttanza residua. Se la ricompensa arriva rapidamente, la traccia di eleggibilità non si è molto deteriorata, quindi l’aggiornamento del peso è grande; se la ricompensa è tardiva, l’effetto è minore. Modulando ampiezza e forma degli impulsi elettrici, i ricercatori possono regolare la durata della traccia di eleggibilità, coprendo un intervallo simile a quello dei sistemi biologici, tutto senza circuiti o elementi di memoria aggiuntivi.
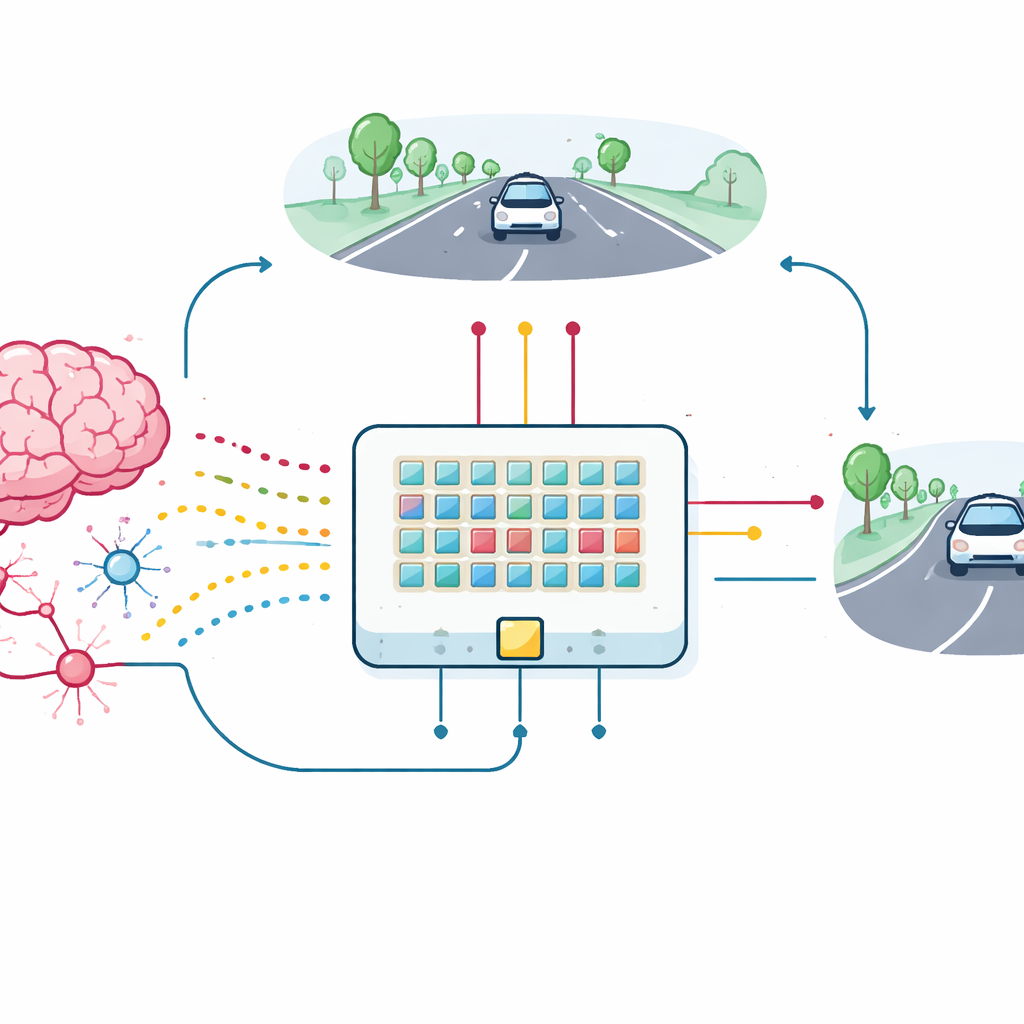
Dal singolo dispositivo all’auto che impara
Per testare il valore pratico di questi transistor sinaptici, il team ha costruito un piccolo array di dispositivi e li ha collegati in una rete neurale spike per un compito di mantenimento della corsia. Una vista semplice e a bassa risoluzione della strada davanti viene convertita in raffiche di spike che entrano in 18 neuroni di input, i quali a loro volta si connettono tramite le nuove sinapsi a due neuroni di output che controllano lo sterzo a sinistra e a destra. Man mano che l’auto simulata devia, riceve un feedback basato su quanto rimane centrata nella corsia. Questo feedback viene trasformato in impulsi di ricompensa che viaggiano ai terzi terminali dei transistor sinaptici, aggiornando direttamente la loro conduttanza sul chip. L’array, anche con variazioni dei dispositivi e rumore, impara a mantenere l’auto nella corsia, e si avvicina molto alle prestazioni di un modello software ideale.
Cosa significa per i dispositivi futuri
Il lavoro mostra che un singolo transistor compatto può svolgere nativamente tre funzioni essenziali per l’apprendimento per rinforzo di tipo cerebrale: aggiustamento della forza sinaptica basato sul timing, memorizzazione temporanea dell’attività recente come traccia di eleggibilità e rinforzo o soppressione guidata dalla ricompensa di quella traccia. Poiché tutto ciò avviene nella fisica del materiale del dispositivo, l’hardware risultante promette notevoli risparmi in area ed energia rispetto ai circuiti convenzionali che simulano lo stesso comportamento via software. Tali transistor sinaptici potrebbero costituire la base dei futuri dispositivi edge — come piccoli robot, sensori o indossabili — che apprendono dall’interazione con l’ambiente in tempo reale consumando pochissima energia.
Citazione: Wang, Y., Xiong, W., Yan, J. et al. Brain-inspired synaptic transistors for in-situ spiking reinforcement learning with eligibility trace. Nat Commun 17, 3001 (2026). https://doi.org/10.1038/s41467-026-69898-9
Parole chiave: hardware neuromorfico, apprendimento per rinforzo, reti neurali spike, transistor ferroelettrici, guida autonoma