Clear Sky Science · es
Transistores sinápticos inspirados en el cerebro para aprendizaje por refuerzo con picos in situ y rastro de elegibilidad
Máquinas más inteligentes inspiradas en el cerebro
Las máquinas inteligentes actuales pueden superar a los humanos en juegos y ayudar a conducir coches, pero el hardware que ejecuta estos algoritmos todavía está lejos de cómo aprende el cerebro. Este artículo presenta un nuevo tipo de dispositivo electrónico diminuto que copia varias técnicas clave usadas por las sinapsis reales para aprender a partir de recompensas y errores. Al integrar estos transistores sinápticos en una red simple, los investigadores demuestran que un pequeño coche robot puede aprender a mantenerse en su carril de forma eficiente sin depender de ordenadores voluminosos y consumidores de energía.
Por qué importa el aprendizaje basado en recompensas
Gran parte de la inteligencia artificial moderna ajusta las conexiones en una red basándose únicamente en los datos de entrada y salida. En cambio, los animales aprenden no solo a partir de patrones, sino también por el éxito y el fracaso señalados por recompensas como la comida o el placer. Los neurocientíficos modelan esto con el “aprendizaje por refuerzo”, donde sustancias especiales en el cerebro, como la dopamina, indican a las sinapsis si una acción reciente fue buena o mala. Una idea relacionada, llamada rastro de elegibilidad, permite que una sinapsis «recuerde» temporalmente la actividad reciente para que una recompensa posterior aún pueda fortalecer o debilitar esa conexión de forma apropiada. Reproducir todas estas características directamente en hardware podría hacer que las máquinas que aprenden sean más rápidas y mucho más eficientes energéticamente.
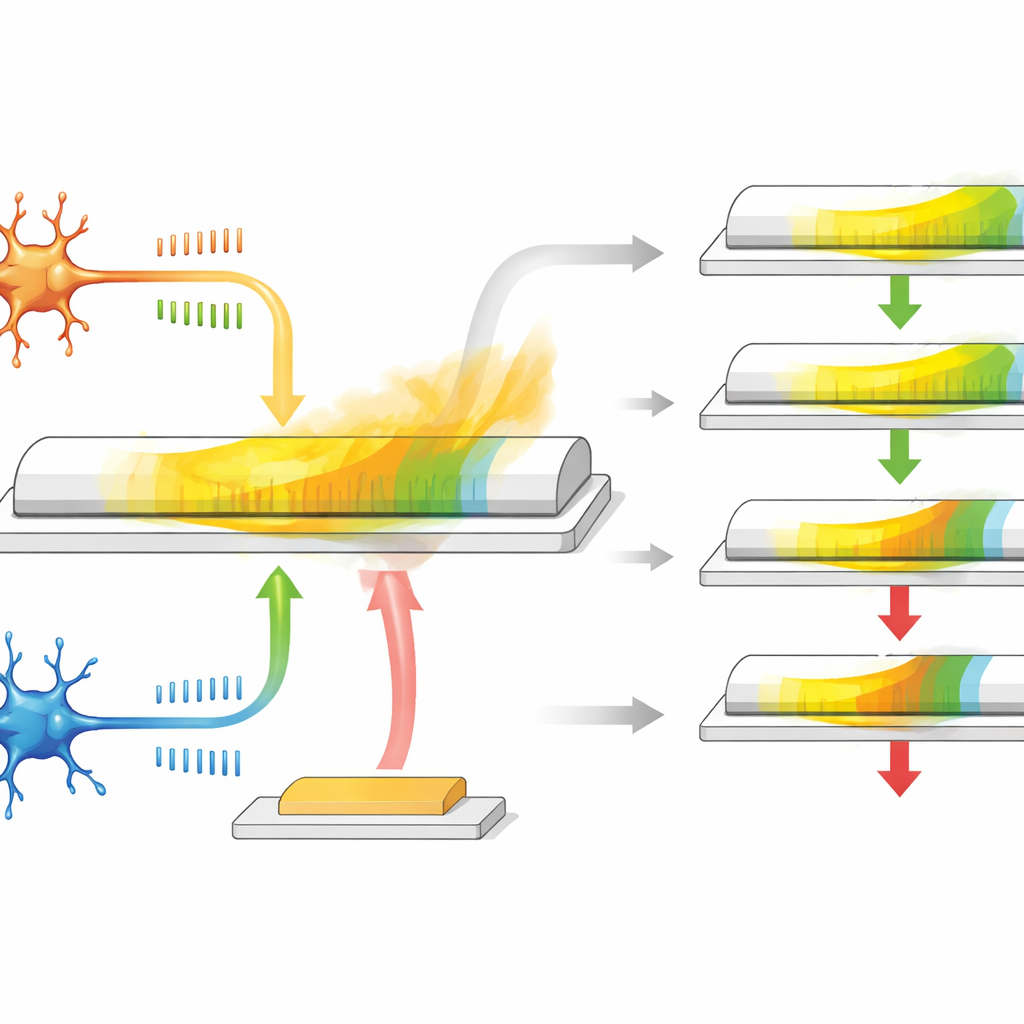
Un solo transistor que actúa como una sinapsis
Los autores desarrollan un transistor sináptico basado en un material especial llamado α-In2Se3, que es a la vez semiconductor y ferroeléctrico, lo que significa que su polarización eléctrica interna puede invertirse y permanecer así. El dispositivo tiene tres terminales: dos actúan como los extremos pre- y postsinápticos de una sinapsis, mientras que el tercero se comporta como una entrada de recompensa. Cuando se aplican pulsos de tensión tipo pico entre los dos primeros terminales, la conductancia del canal cambia, imitando cómo una sinapsis se fortalece o debilita según el tiempo entre picos. Debido a que la polarización del material se relaja lentamente con el tiempo, la conductancia vuelve a su valor anterior de forma natural, proporcionando una memoria integrada y de desvanecimiento gradual que representa al rastro de elegibilidad.
Integrar recompensa y memoria en la física del dispositivo
Este transistor hace más que simplemente almacenar un valor. Su polarización en el plano responde principalmente a señales que representan el aprendizaje basado en el tiempo entre dos neuronas, mientras que la polarización fuera del plano responde con más fuerza a pulsos aplicados en el tercer terminal, que actúa como señal de recompensa. Durante el periodo de relajación tras la actividad en picos, un pulso de recompensa retardado llega a la puerta y aumenta o reduce el cambio de conductancia restante. Si la recompensa llega pronto, el rastro de elegibilidad no se ha degradado mucho, por lo que la actualización del peso es grande; si la recompensa llega tarde, el efecto es menor. Ajustando el tamaño y la forma de los pulsos eléctricos, los investigadores pueden regular cuánto dura el rastro de elegibilidad, abarcando un rango similar al de los sistemas biológicos, todo ello sin circuitos ni elementos de memoria adicionales.
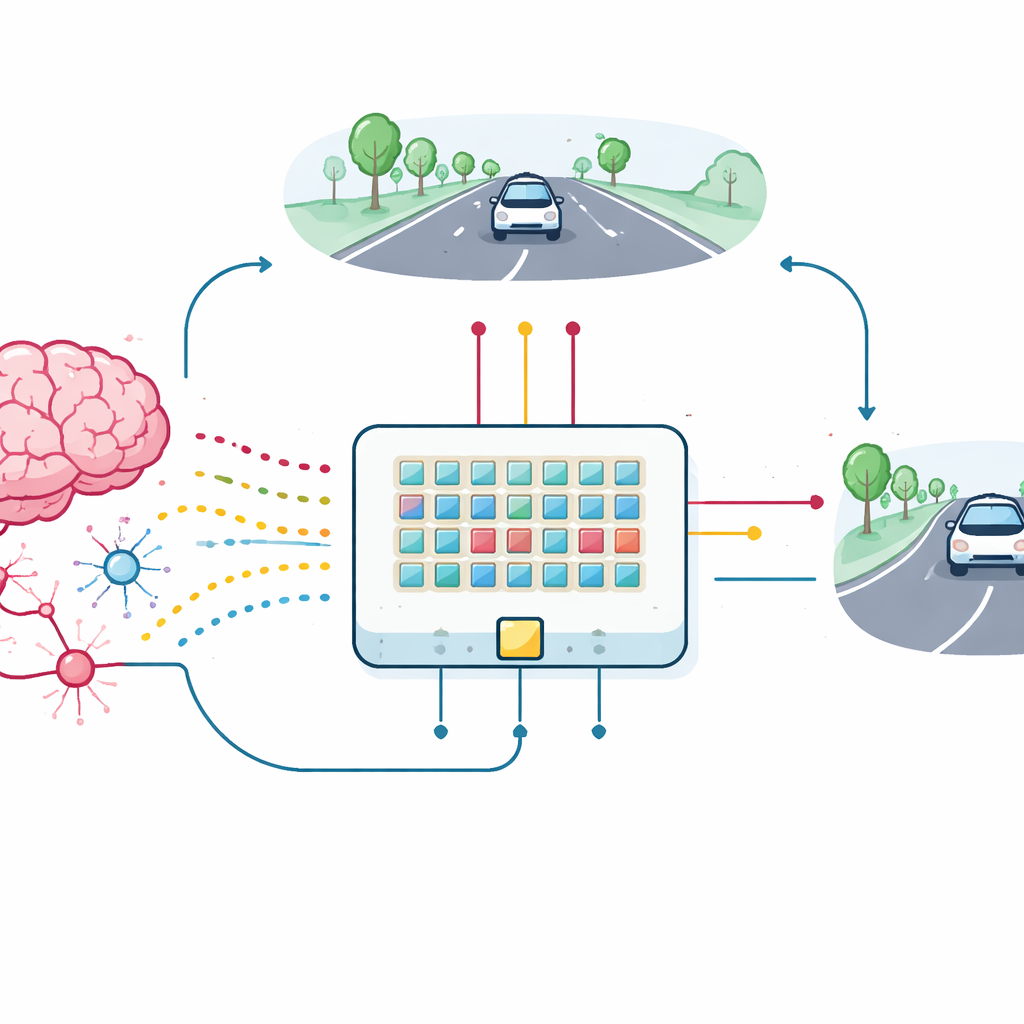
Del dispositivo individual al coche que aprende
Para comprobar el valor práctico de estos transistores sinápticos, el equipo construyó una pequeña matriz de dispositivos y los conectó en una red neuronal de picos para una tarea de mantenimiento de carril. Una vista simple y de baja resolución de la carretera por delante se convierte en ráfagas de picos que entran en 18 neuronas de entrada, las cuales a su vez se conectan a través de las nuevas sinapsis a dos neuronas de salida que controlan la dirección izquierda y derecha. A medida que el coche simulado se desplaza, recibe retroalimentación en función de lo bien que se mantiene centrado en el carril. Esta retroalimentación se convierte en pulsos de recompensa que viajan a los terceros terminales de los transistores sinápticos, actualizando su conductancia directamente en el chip. La matriz, incluso con variaciones en los dispositivos y ruido, aprende a mantener el coche en su carril, igualando de cerca el rendimiento de un modelo de software ideal.
Qué significa esto para futuros dispositivos
El trabajo muestra que un transistor compacto y único puede llevar a cabo de forma nativa tres funciones esenciales para el aprendizaje por refuerzo de tipo cerebral: ajuste del peso sináptico basado en el tiempo, almacenamiento temporal de la actividad reciente como rastro de elegibilidad y refuerzo o supresión de ese rastro guiado por recompensas. Debido a que todo esto ocurre dentro de la propia física del material del dispositivo, el hardware resultante promete importantes ahorros en área y energía en comparación con los circuitos convencionales que simulan el mismo comportamiento en software. Tales transistores sinápticos podrían formar la base de futuros dispositivos perimetrales —como pequeños robots, sensores o wearables— que aprendan de la interacción con su entorno en tiempo real consumiendo muy poca energía.
Cita: Wang, Y., Xiong, W., Yan, J. et al. Brain-inspired synaptic transistors for in-situ spiking reinforcement learning with eligibility trace. Nat Commun 17, 3001 (2026). https://doi.org/10.1038/s41467-026-69898-9
Palabras clave: hardware neuromórfico, aprendizaje por refuerzo, redes neuronales de picos, transistores ferroeléctricos, conducción autónoma