Clear Sky Science · sv
Hjärninspirerade synaptiska transistorer för in-situ spikande förstärkningsinlärning med eligibility-trace
Smartare maskiner inspirerade av hjärnan
Dagens smarta maskiner kan besegra människor i spel och hjälpa till att köra bilar, men hårdvaran som kör dessa algoritmer skiljer sig fortfarande mycket från hur hjärnan lär sig. Denna artikel presenterar en ny typ av liten elektronisk enhet som efterliknar flera viktiga trick som riktiga synapser i hjärnan använder för att lära från belöningar och misstag. Genom att bygga dessa synapsliknande transistorer i ett enkelt nätverk visar forskarna att en liten robotbil kan lära sig att hålla sig i sin fil effektivt utan att förlita sig på klumpiga, energikrävande datorer.
Varför belöningsbaserad inlärning är viktig
Mycket av modern artificiell intelligens justerar kopplingar i ett nätverk enbart baserat på in- och utdata. Djur lär sig däremot inte bara från mönster, utan också från framgång och misslyckande som signaleras av belöningar som mat eller välbehag. Neuroforskare modellerar detta med ”förstärkningsinlärning”, där speciella kemikalier i hjärnan, som dopamin, talar om för synapser om en nyligen utförd handling var bra eller dålig. En närliggande idé, kallad en eligibility-trace, låter en synaps temporärt ”komma ihåg” nyligen aktivitet så att en senare belöning fortfarande kan stärka eller försvaga den förbindelsen på ett lämpligt sätt. Att reproducera alla dessa funktioner direkt i hårdvara kan göra lärande maskiner både snabbare och mycket mer energieffektiva.
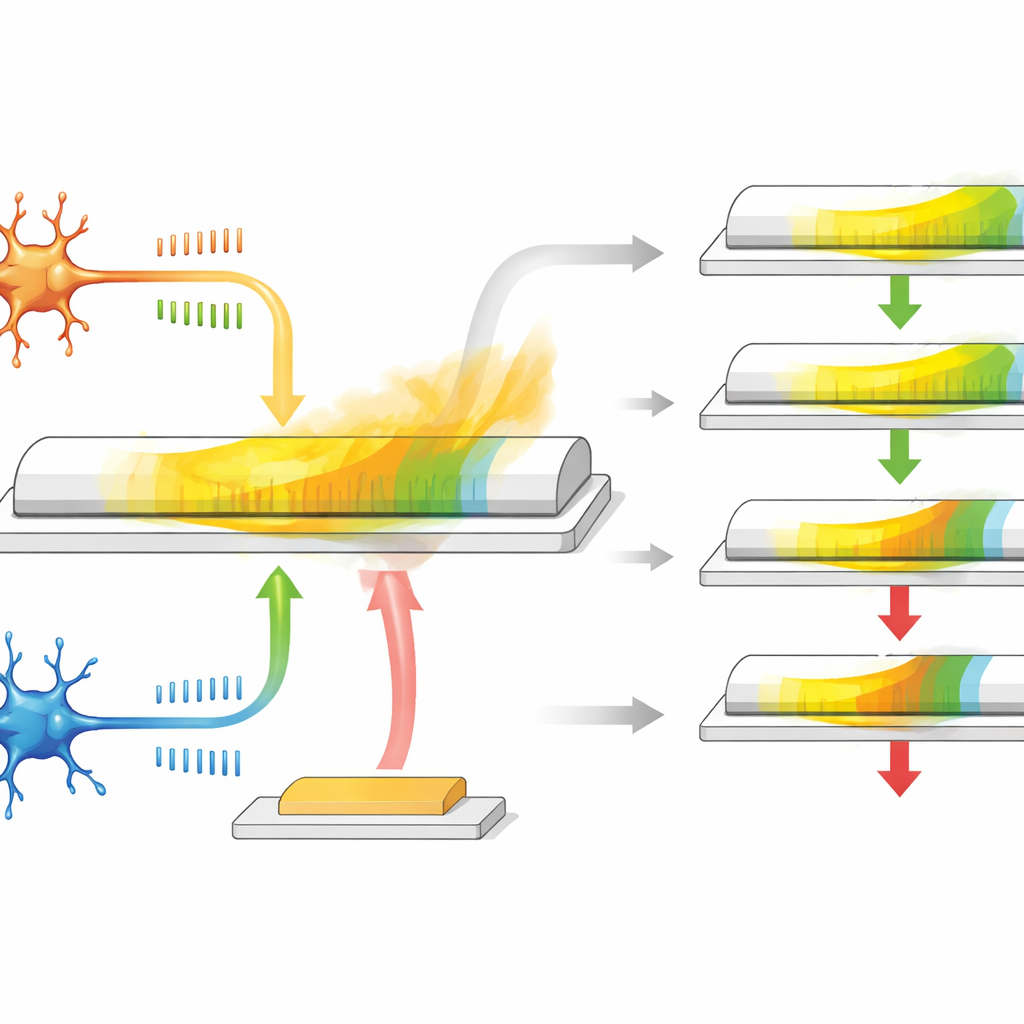
En enda transistor som fungerar som en synaps
Författarna utvecklar en synaptisk transistor baserad på ett särskilt material kallat α-In2Se3, som både är en halvledare och ferroelectric — det vill säga dess interna elektriska polarisation kan vändas och förblir så. Enheten har tre terminaler: två fungerar som pre- och post-neuronändar i en synaps, medan den tredje beter sig som en belöningsingång. När spikliknande voltpulser appliceras mellan de två första terminalerna ändras kanalens ledningsförmåga och efterliknar hur en synaps blir starkare eller svagare beroende på spiktiming. Eftersom materialets polarisation långsamt relaxerar över tid, återgår ledningsförmågan naturligt, vilket ger ett inbyggt, gradvis försvinnande minne som står för eligibility-tracen.
Inbyggd belöning och minne i fysiken
Denna transistor gör mer än att bara lagra ett värde. Dess inplanpolarisering reagerar främst på signaler som representerar den vanliga tidsbaserade inlärningen mellan två neuroner, medan polariseringen utanför planet reagerar starkare på pulser applicerade på den tredje terminalen, som fungerar som belöningssignalen. Under relaxationsperioden efter spikaktivitet anländer en fördröjd belöningspuls till grindspänningen och antingen förstärker eller minskar den kvarvarande ledningsändringen. Om belöningen kommer snabbt har eligibility-tracen inte hunnit avklinga mycket, så viktuppdateringen är stor; om belöningen kommer sent är effekten mindre. Genom att justera storleken och formen på de elektriska pulserna kan forskarna anpassa hur länge eligibility-tracen varar och täcka ett intervall liknande biologiska system, allt utan extra kretsar eller minneskomponenter.
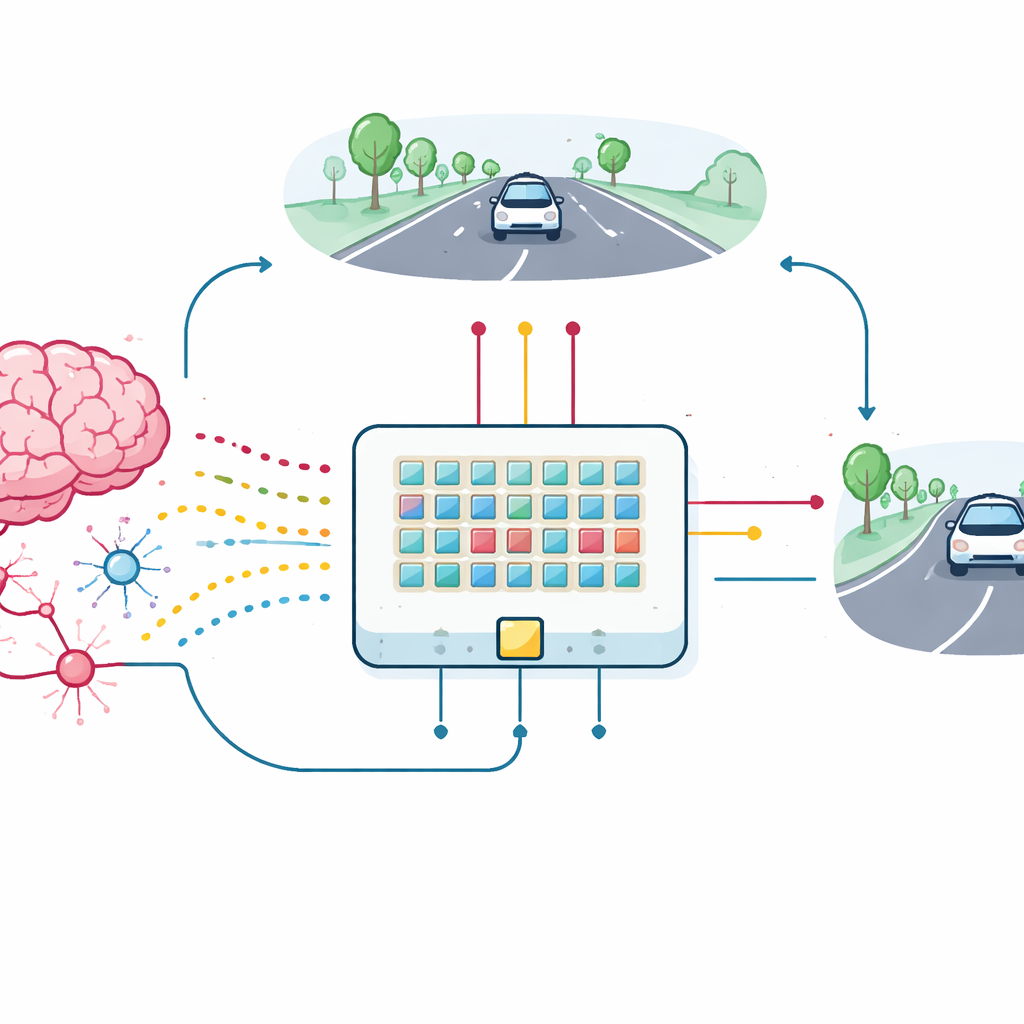
Från enstaka enhet till lärande bil
För att testa det praktiska värdet av dessa synaptiska transistorer byggde teamet en liten matris med enheter och kopplade dem till ett spikande neuralt nätverk för en filhållningsuppgift. En enkel, lågupplöst vy av vägen framför omvandlas till sprängar av spikar som går in i 18 ingångsneuroner, vilka i sin tur kopplas genom de nya synapserna till två utgångsneuroner som styr vänster- respektive högersväng. När den simulerade bilen svänger får den återkoppling baserat på hur väl den håller sig centrerad i filen. Denna återkoppling omvandlas till belöningspulser som skickas till de tredje terminalerna på de synaptiska transistorerna och uppdaterar deras ledningsförmåga direkt på kretsen. Matrisen lär sig, trots variationer och brus i enheterna, att hålla bilen i filen och når prestanda som ligger nära ett idealiskt mjukvarumodell.
Vad detta betyder för framtida enheter
Arbetet visar att en enda, kompakt transistor ursprungligen kan utföra tre väsentliga funktioner för hjärnlik förstärkningsinlärning: tidsbaserad justering av synaptisk styrka, tillfällig lagring av senaste aktivitet som en eligibility-trace, och belöningsdriven förstärkning eller undertryckning av den trace:en. Eftersom allt detta sker inom enhetens egna materialfysik lovar den resulterande hårdvaran stora besparingar i area och energi jämfört med konventionella kretsar som simulerar samma beteende i mjukvara. Sådana synaptiska transistorer skulle kunna bilda grund för framtida edge-enheter — som små robotar, sensorer eller bärbara enheter — som lär sig genom interaktion med omgivningen i realtid samtidigt som de förbrukar mycket lite effekt.
Citering: Wang, Y., Xiong, W., Yan, J. et al. Brain-inspired synaptic transistors for in-situ spiking reinforcement learning with eligibility trace. Nat Commun 17, 3001 (2026). https://doi.org/10.1038/s41467-026-69898-9
Nyckelord: neuromorf hårdvara, förstärkningsinlärning, spikande neurala nätverk, ferroelectric transistorer, autonom körning