Clear Sky Science · pt
Transistores sinápticos inspirados no cérebro para aprendizado por reforço com spikes in situ e traço de elegibilidade
Máquinas mais inteligentes inspiradas no cérebro
As máquinas inteligentes atuais podem vencer humanos em jogos e ajudar a dirigir carros, mas o hardware que executa esses algoritmos ainda está longe de como o cérebro aprende. Este artigo apresenta um novo tipo de dispositivo eletrônico minúsculo que reproduz vários truques-chave usados por sinapses reais no cérebro para aprender com recompensas e erros. Ao integrar esses transistores semelhantes a sinapses em uma rede simples, os pesquisadores mostram que um pequeno carro robô pode aprender a manter-se na pista de forma eficiente sem depender de computadores volumosos e com alto consumo de energia.
Por que o aprendizado baseado em recompensas importa
Muita da inteligência artificial moderna ajusta conexões em uma rede apenas com base em dados de entrada e saída. Em contraste, os animais aprendem não apenas a partir de padrões, mas também a partir do sucesso e fracasso sinalizados por recompensas, como comida ou prazer. Neurocientistas modelam isso com “aprendizado por reforço”, onde substâncias especiais no cérebro, como a dopamina, indicam às sinapses se uma ação recente foi boa ou ruim. Uma ideia relacionada, chamada traço de elegibilidade, permite que uma sinapse “lembre-se” temporariamente de atividade recente para que uma recompensa posterior ainda possa fortalecer ou enfraquecer essa conexão de maneira apropriada. Reproduzir todas essas características diretamente no hardware pode tornar as máquinas de aprendizado mais rápidas e muito mais eficientes em termos de energia.
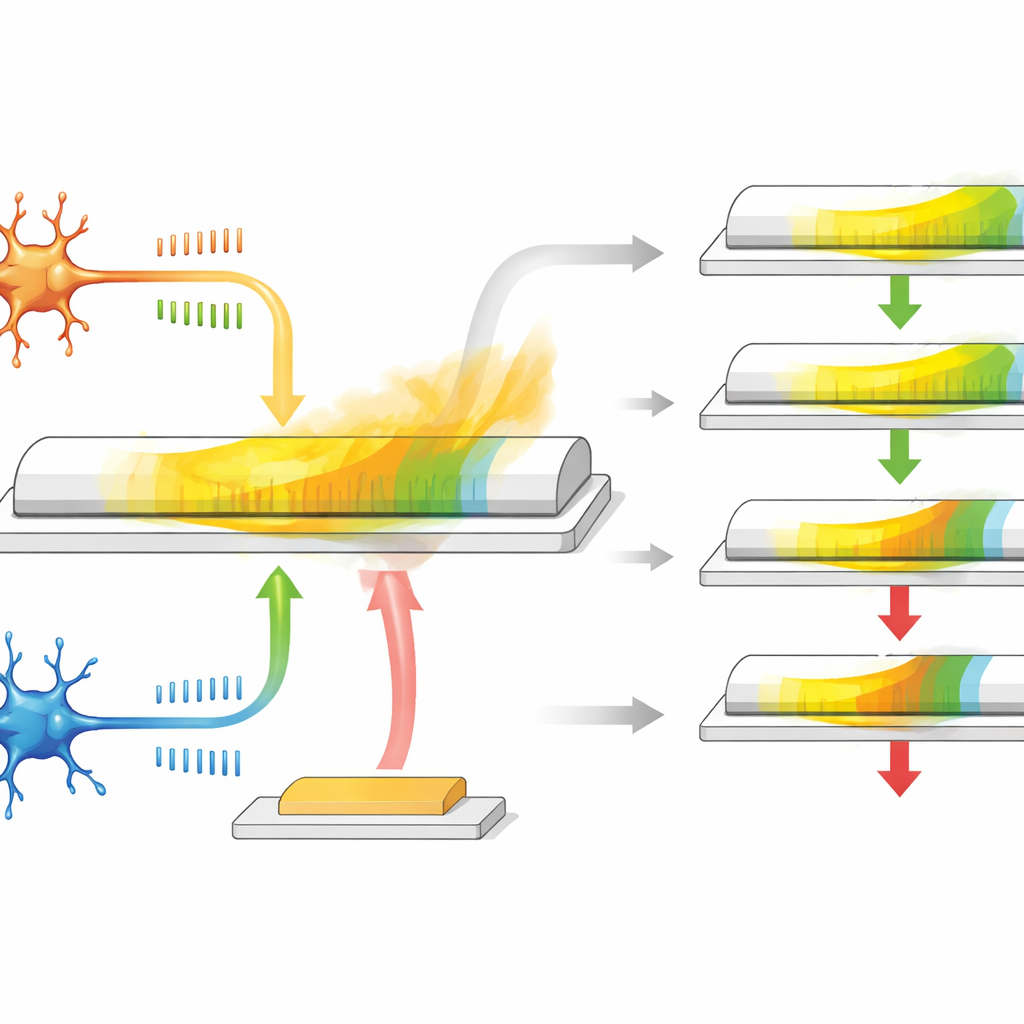
Um único transistor que age como uma sinapse
Os autores desenvolvem um transistor sináptico baseado em um material especial chamado α-In2Se3, que é ao mesmo tempo semicondutor e ferroelétrico, ou seja, sua polarização elétrica interna pode ser invertida e permanece nessa configuração. O dispositivo tem três terminais: dois atuam como as extremidades pré- e pós-neurais de uma sinapse, enquanto o terceiro se comporta como uma entrada de recompensa. Quando pulsos de tensão em forma de spike são aplicados entre os primeiros dois terminais, a condutância do canal muda, imitando como uma sinapse se fortalece ou enfraquece dependendo do timing dos spikes. Como a polarização do material relaxa lentamente ao longo do tempo, a condutância retorna naturalmente, proporcionando uma memória incorporada que decai gradualmente e que representa o traço de elegibilidade.
Incorporando recompensa e memória na física
Esse transistor faz mais do que simplesmente armazenar um valor. Sua polarização no plano responde principalmente a sinais que representam o aprendizado baseado em temporização entre dois neurônios, enquanto a polarização fora do plano responde de forma mais forte a pulsos aplicados no terceiro terminal, que serve como o sinal de recompensa. Durante o período de relaxamento após a atividade em spikes, um pulso de recompensa retardado chega ao gate e ou aumenta ou reduz a mudança de condutância remanescente. Se a recompensa chegar rapidamente, o traço de elegibilidade não terá decaído muito, então a atualização do peso é grande; se a recompensa for tardia, o efeito será menor. Ajustando o tamanho e a forma dos pulsos elétricos, os pesquisadores podem controlar por quanto tempo o traço de elegibilidade dura, cobrindo uma faixa semelhante à dos sistemas biológicos, tudo sem circuitos ou elementos de memória adicionais.
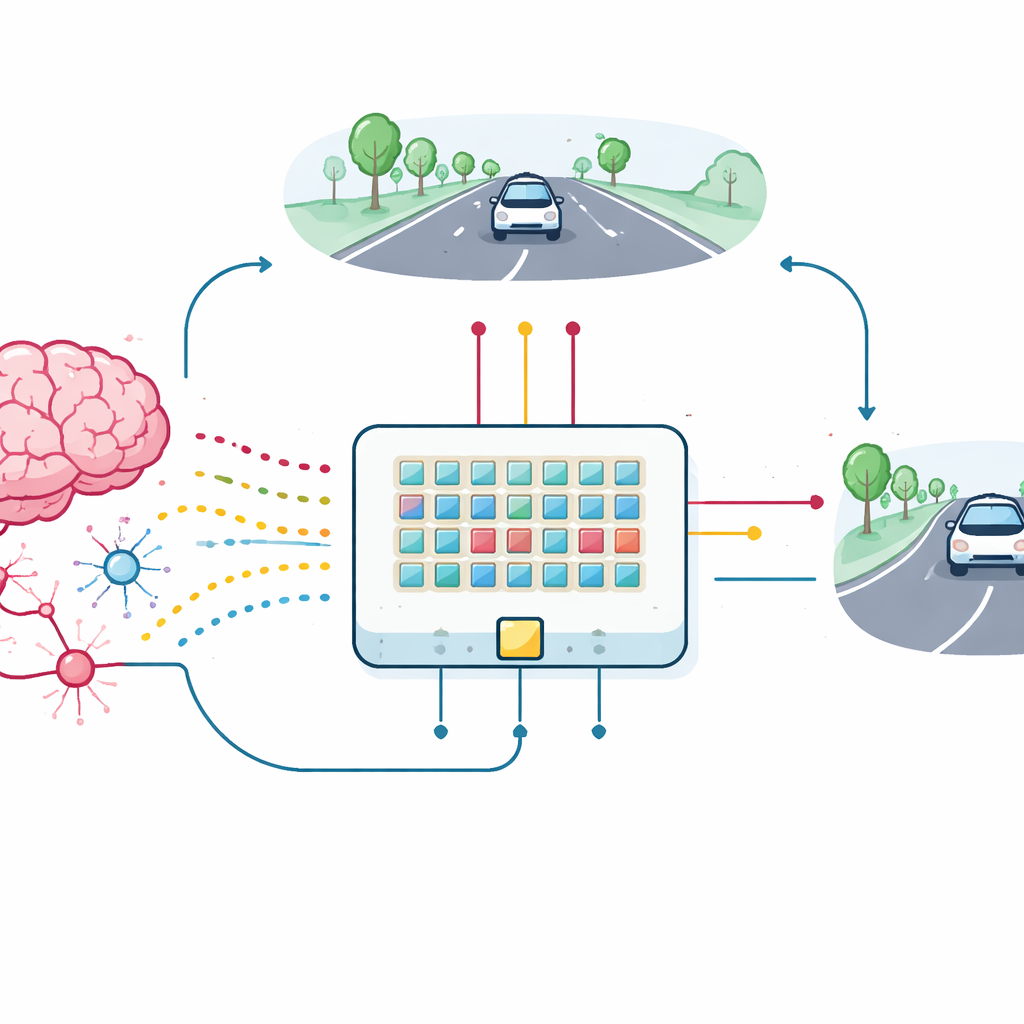
Do dispositivo único ao carro que aprende
Para testar o valor prático desses transistores sinápticos, a equipe construiu um pequeno arranjo de dispositivos e os conectou em uma rede neural com spikes para uma tarefa de manutenção de faixa. Uma visão simples e de baixa resolução da estrada à frente é convertida em rajadas de spikes que entram em 18 neurônios de entrada, os quais, por sua vez, se conectam através das novas sinapses a dois neurônios de saída que controlam a direção para a esquerda e para a direita. À medida que o carro simulado se desloca, ele recebe feedback baseado em quão bem permanece centralizado na faixa. Esse feedback é transformado em pulsos de recompensa que viajam aos terceiros terminais dos transistores sinápticos, atualizando sua condutância diretamente no chip. O arranjo, mesmo com variações nos dispositivos e ruído, aprende a manter o carro na pista, aproximando-se fortemente do desempenho de um modelo ideal em software.
O que isso significa para dispositivos futuros
O trabalho demonstra que um único transistor compacto pode executar nativamente três funções essenciais para aprendizado por reforço inspirado no cérebro: ajuste de força sináptica baseado em temporização, armazenamento temporário da atividade recente como traço de elegibilidade e reforço ou supressão desse traço guiado por recompensas. Como tudo isso ocorre na própria física do material do dispositivo, o hardware resultante promete grandes economias de área e energia em comparação com circuitos convencionais que simulam o mesmo comportamento em software. Esses transistores sinápticos podem formar a base de futuros dispositivos de borda — como pequenos robôs, sensores ou wearables — que aprendem pela interação com o ambiente em tempo real consumindo pouquíssima energia.
Citação: Wang, Y., Xiong, W., Yan, J. et al. Brain-inspired synaptic transistors for in-situ spiking reinforcement learning with eligibility trace. Nat Commun 17, 3001 (2026). https://doi.org/10.1038/s41467-026-69898-9
Palavras-chave: hardware neuromórfico, aprendizado por reforço, redes neurais com spikes, transistores ferroelétricos, direção autônoma