Clear Sky Science · pl
Synaptyczne tranzystory inspirowane mózgiem do w-sytuacyjnego wzmacniania uczenia z sygnałem eligibility
Inteligentniejsze maszyny inspirowane mózgiem
Dzisiejsze inteligentne maszyny potrafią pokonać ludzi w grach i wspierać prowadzenie samochodów, ale sprzęt uruchamiający te algorytmy wciąż znacznie różni się od tego, jak uczy się mózg. W artykule przedstawiono nowy typ niewielkiego urządzenia elektronicznego, które naśladuje kilka kluczowych mechanizmów wykorzystywanych przez prawdziwe synapsy do uczenia się na podstawie nagród i błędów. Wbudowując takie synapso-podobne tranzystory w prostą sieć, badacze pokazują, że mały robotyczny samochód może efektywnie nauczyć się utrzymywać pas ruchu bez polegania na dużych, energochłonnych komputerach.
Dlaczego uczenie oparte na nagrodach ma znaczenie
Większość współczesnej sztucznej inteligencji dostosowuje połączenia w sieci głównie na podstawie danych wejściowych i wyjściowych. Dla kontrastu, zwierzęta uczą się nie tylko na podstawie wzorców, lecz także przez sukcesy i porażki sygnalizowane nagrodami, takimi jak pokarm czy przyjemność. Neuronauka modeluje to za pomocą „uczenia przez wzmacnianie”, gdzie specjalne substancje w mózgu, np. dopamina, informują synapsy, czy niedawne działanie było korzystne. Powiązana koncepcja, zwana śladem kwalifikowalności (eligibility trace), pozwala synapsie tymczasowo „zapamiętać” niedawną aktywność, tak aby późniejsza nagroda mogła wciąż odpowiednio wzmocnić lub osłabić to połączenie. Odwzorowanie wszystkich tych funkcji bezpośrednio w sprzęcie mogłoby uczynić maszyny uczące się szybszymi i znacznie bardziej energooszczędnymi.
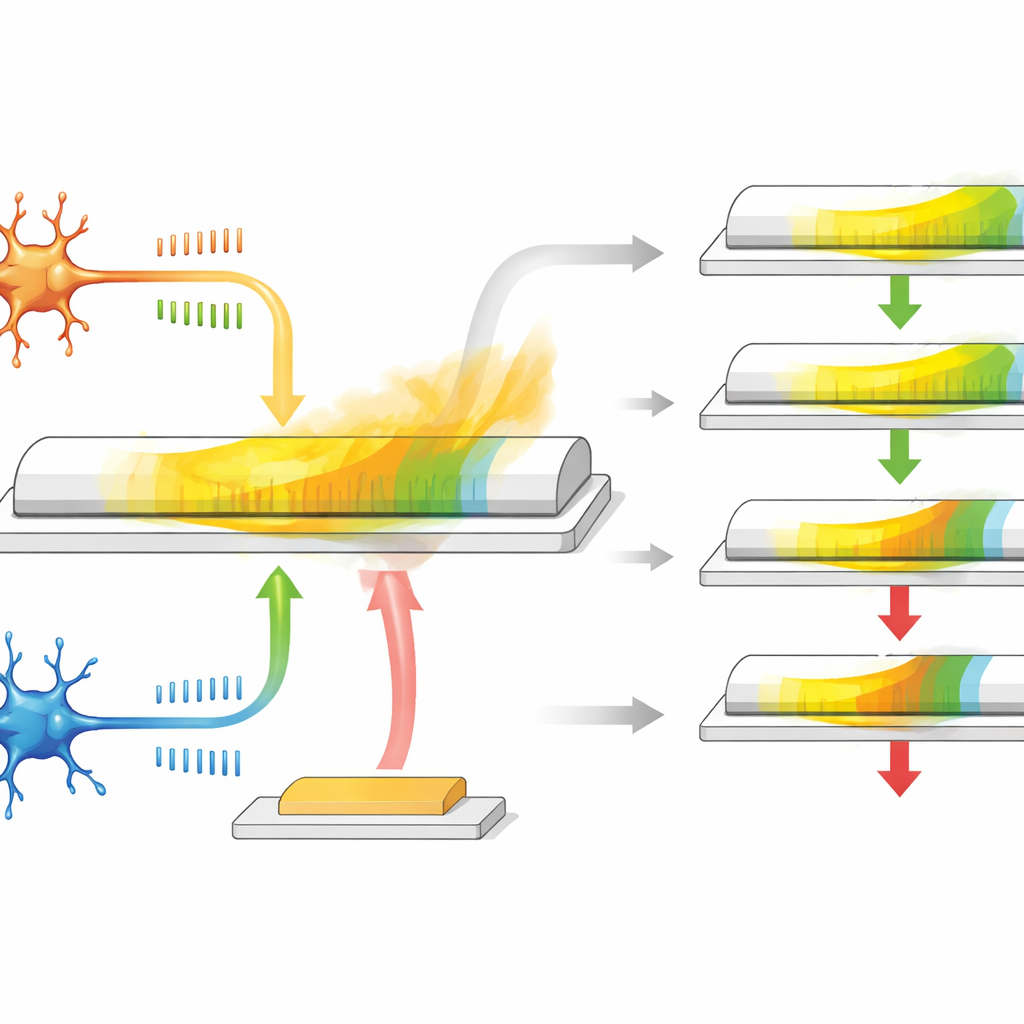
Pojedynczy tranzystor działający jak synapsa
Autorzy opracowali synaptyczny tranzystor oparty na specjalnym materiale α-In2Se3, który jest jednocześnie półprzewodnikiem i ferroelektrykiem, co oznacza, że jego wewnętrzna polaryzacja elektryczna może zostać przełączona i pozostaje w tej konfiguracji. Urządzenie ma trzy elektrody: dwie pełnią rolę odpowiedników końców pre- i post-neuronu synapsy, podczas gdy trzecia zachowuje się jak wejście nagrody. Gdy między pierwszymi dwiema elektrodami przykładane są impulsowe napięcia przypominające wyładowania (spiki), przewodność kanału zmienia się, naśladując, jak synapsa ulega wzmocnieniu lub osłabieniu w zależności od timingów impulsów. Ponieważ polaryzacja materiału stopniowo relaksuje się z czasem, przewodność naturalnie wraca, zapewniając wbudowaną, stopniowo zanikającą pamięć pełniącą rolę śladu kwalifikowalności.
Wbudowanie nagrody i pamięci w fizykę urządzenia
Ten tranzystor robi więcej niż przechowuje wartość. Jego polaryzacja w płaszczyźnie reaguje głównie na sygnały reprezentujące typowe uczenie zależne od czasu między dwoma neuronami, podczas gdy polaryzacja prostopadła reaguje silniej na impulsy przyłożone do trzeciej elektrody, która służy jako sygnał nagrody. W okresie relaksacji po aktywności spike'ów dociera opóźniony impuls nagrody do bramki i albo wzmacnia, albo zmniejsza pozostałą zmianę przewodności. Jeśli nagroda nadejdzie szybko, ślad kwalifikowalności nie zdążył się mocno zmniejszyć, więc aktualizacja wagi jest duża; jeśli nagroda jest późna, efekt jest słabszy. Poprzez dostrojenie rozmiaru i kształtu impulsów elektrycznych badacze mogą regulować, jak długo trwa ślad kwalifikowalności, obejmując zakresy podobne do systemów biologicznych — wszystko to bez dodatkowych układów czy elementów pamięci.
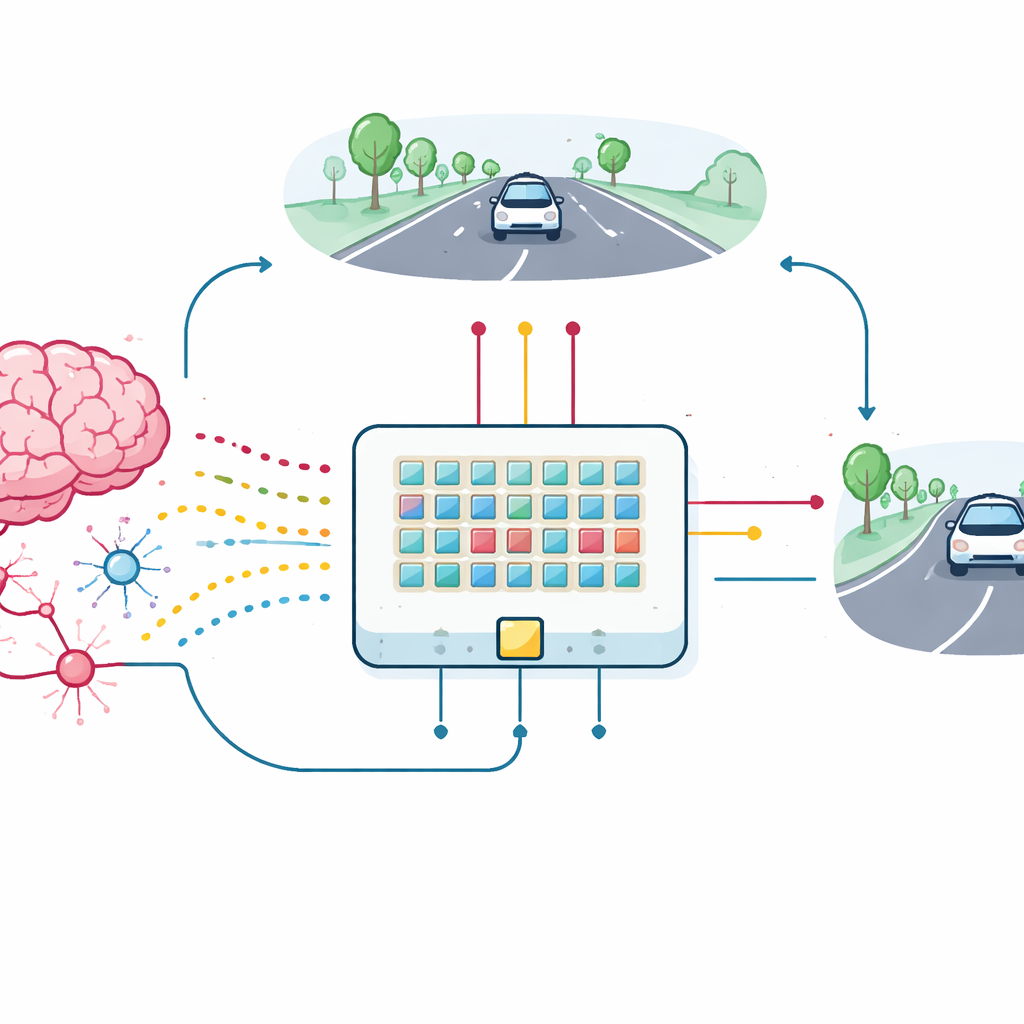
Od pojedynczego urządzenia do uczącego się samochodu
Aby przetestować praktyczną wartość tych synaptycznych tranzystorów, zespół zbudował małą matrycę urządzeń i połączył je w spikingową sieć neuronową do zadania utrzymywania pasa. Prosty, niskorozdzielczy obraz drogi z przodu jest przekształcany w serie spike'ów trafiających do 18 neuronów wejściowych, które następnie łączą się przez nowe synapsy z dwoma neuronami wyjściowymi sterującymi skrętem w lewo i prawo. Gdy symulowany samochód zbacza, otrzymuje informację zwrotną ocenianą według tego, jak dobrze utrzymuje się na środku pasa. Ta informacja jest przekształcana w impulsy nagrody, które docierają do trzecich elektrod synaptycznych tranzystorów, bezpośrednio aktualizując ich przewodność na chipie. Matryca, nawet z wahaniami parametrów urządzeń i szumem, uczy się utrzymywać samochód na pasie, osiągając wyniki zbliżone do idealnego modelu programowego.
Co to oznacza dla przyszłych urządzeń
Praca pokazuje, że pojedynczy, kompaktowy tranzystor może natywnie realizować trzy istotne funkcje dla mózgo-podobnego uczenia przez wzmacnianie: dostosowywanie siły synaptycznej zależne od czasu, tymczasowe przechowywanie niedawnej aktywności jako ślad kwalifikowalności oraz wzmacnianie bądź tłumienie tego śladu sterowane nagrodą. Ponieważ wszystko to zachodzi w fizyce samego materiału urządzenia, wynikowy sprzęt obiecuje znaczące oszczędności miejsca i energii w porównaniu z konwencjonalnymi układami symulującymi takie zachowanie w oprogramowaniu. Takie synaptyczne tranzystory mogłyby stanowić podstawę przyszłych urządzeń brzegowych — jak małe roboty, czujniki czy wearables — które uczą się w czasie rzeczywistym poprzez interakcję ze środowiskiem, zużywając przy tym bardzo mało energii.
Cytowanie: Wang, Y., Xiong, W., Yan, J. et al. Brain-inspired synaptic transistors for in-situ spiking reinforcement learning with eligibility trace. Nat Commun 17, 3001 (2026). https://doi.org/10.1038/s41467-026-69898-9
Słowa kluczowe: sprzęt neuromorficzny, uczenie przez wzmacnianie, spikingowe sieci neuronowe, tranzystory ferroelektryczne, samochód autonomiczny