Clear Sky Science · ja
適合性トレースを伴うインシチュ・スパイキング強化学習のための脳に着想を得たシナプス型トランジスタ
脳に倣ったより賢い機械
今日のスマートマシンはゲームで人間を打ち負かし、自動運転を支援することができますが、これらのアルゴリズムを動かすハードウェアは脳が学習する仕組みからはまだ大きく隔たっています。本論文は、報酬と失敗から学ぶ際に実際のシナプスが使ういくつかの重要なトリックを模した新しい小型電子デバイスを提示します。これらのシナプスに似たトランジスタを単純なネットワークに組み込むことで、研究者らは大きく消費電力のかかるコンピュータに頼らず小型のロボット車が効率的に車線維持を学べることを示しています。
報酬に基づく学習が重要な理由
現代の人工知能の多くは入力と出力のデータに基づいてネットワークの結合を調整します。それに対して動物は、単なるパターンだけでなく、食物や快感のような報酬によって示される成功や失敗から学びます。神経科学ではこれを「強化学習」とモデル化しており、ドーパミンなどの特別な化学物質が、最近の行動が良かったか悪かったかをシナプスに伝えます。関連する概念である適合性トレースは、後から来る報酬が依然としてその結合を適切に強化または弱化できるように、シナプスが最近の活動を一時的に「記憶」しておく仕組みです。これらすべての機能をハードウェアで直接再現できれば、学習する機械はより高速で大幅にエネルギー効率が向上する可能性があります。
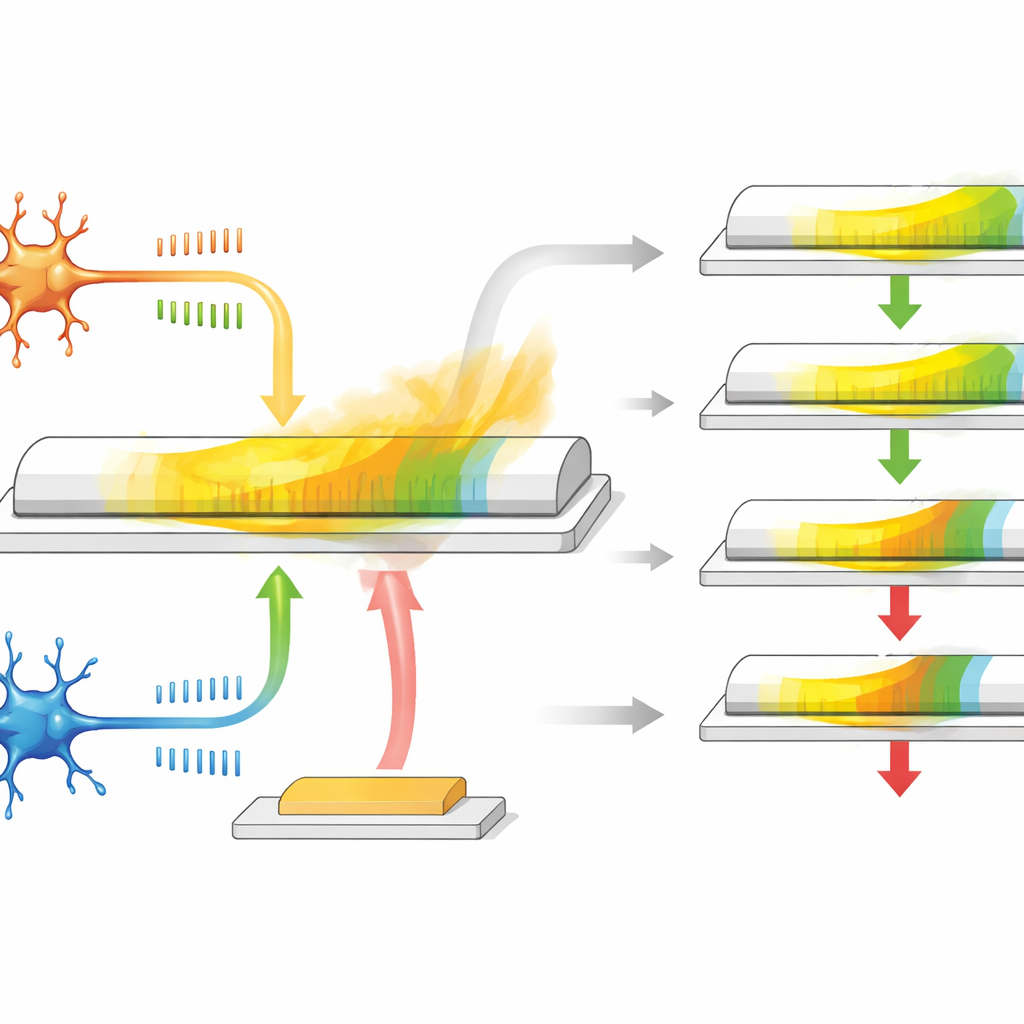
シナプスとして振る舞う単一トランジスタ
著者らはα-In2Se3と呼ばれる特別な材料に基づくシナプス型トランジスタを開発しました。この材料は半導体であると同時に強誘電性を持ち、その内部の電気分極を反転させるとその状態が維持されます。デバイスは三つの端子を持ち、二つはシナプスの事前・事後ニューロン端に相当し、三つ目は報酬入力の役割を果たします。最初の二つの端子間にスパイクのような電圧パルスを印加すると、チャネルのコンダクタンスが変化し、スパイクのタイミングに応じてシナプスが強くなったり弱くなったりする様子を模倣します。材料の分極が時間とともにゆっくり緩和するため、コンダクタンスは自然に戻り、適合性トレースの代わりとなる内在的で徐々に消える記憶を提供します。
物理に組み込まれた報酬と記憶
このトランジスタは単に値を保存するだけではありません。面内分極は主に二つのニューロン間の通常のタイミングベース学習を表す信号に応答し、面外分極は三つ目の端子に印加されるパルス、すなわち報酬信号に対してより強く応答します。スパイク活動後の緩和期間中に遅れて到着する報酬パルスがゲートに到達すると、残っているコンダクタンス変化を増強または減衰させます。報酬が早く来れば適合性トレースはあまり減衰しておらず、重みの更新は大きくなります;報酬が遅ければ効果は小さくなります。電気パルスの大きさや形状を調整することで、研究者らは適合性トレースの持続時間を生物学的システムに近い範囲で調整でき、追加の回路やメモリ素子を必要としません。
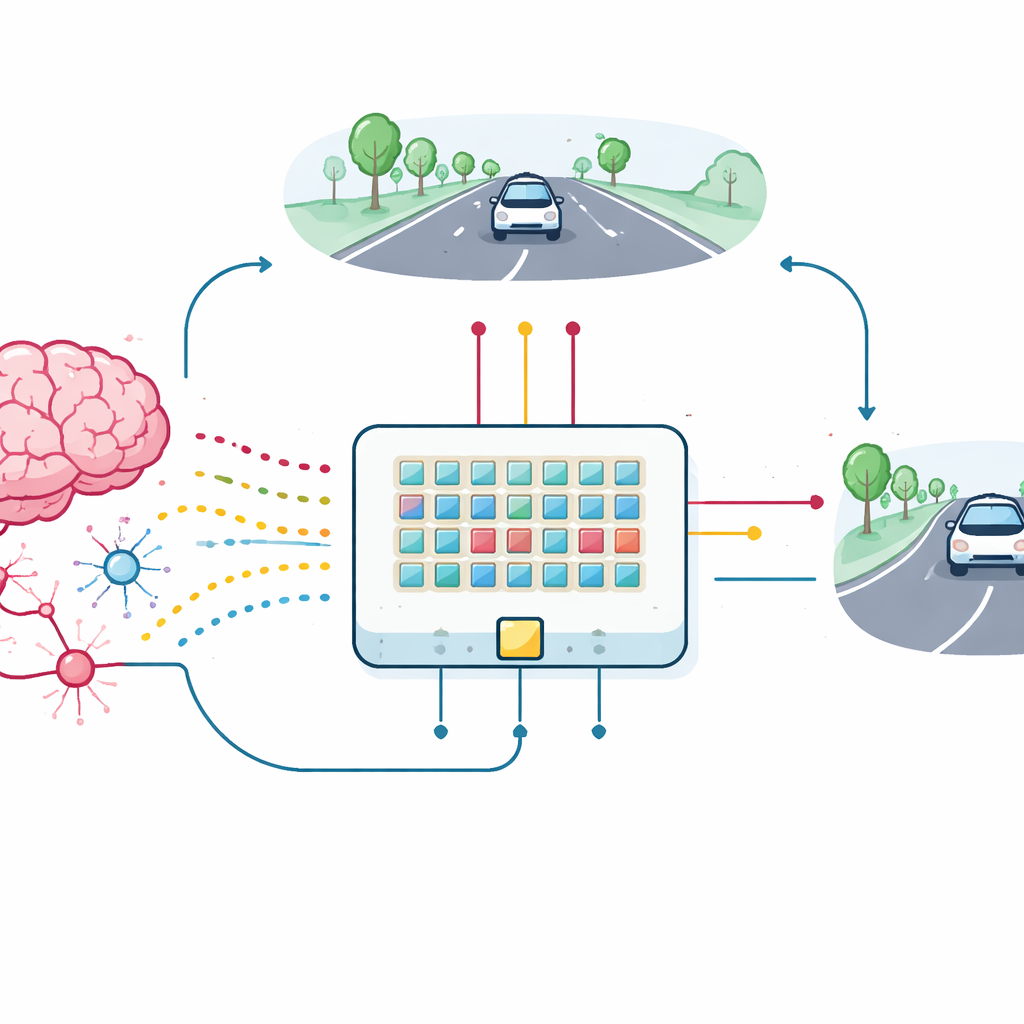
単一デバイスから学習する車へ
これらのシナプストランジスタの実用性を試すため、チームは小さなデバイスアレイを作り、車線維持タスクのためのスパイキングニューラルネットワークに接続しました。道路前方の単純で低解像度な視覚が18個の入力ニューロンへ入るスパイクバーストに変換され、それらは新しいシナプスを通じて左右の操舵を制御する二つの出力ニューロンに接続されます。模擬車がふらつくにつれて、車線の中心にどれだけ留まっているかに基づくフィードバックを受けます。このフィードバックはシナプストランジスタの三つ目の端子に届く報酬パルスに変換され、チップ上で直接コンダクタンスを更新します。デバイスのばらつきやノイズがあっても、アレイは車を車線内に保つことを学習し、理想的なソフトウェアモデルの性能に近い結果を示しました。
将来のデバイスに示す意味
この研究は、単一の小型トランジスタが脳に似た強化学習のための三つの本質的機能を本来的に担えることを示しています:タイミングに基づくシナプス強度の調整、適合性トレースとしての最近の活動の一時保存、そしてそのトレースに対する報酬による強化または抑制。このすべてがデバイス自身の材料物理の内部で行われるため、同じ挙動をソフトウェアで模擬する従来の回路と比べて面積とエネルギーの大幅な節約が期待できます。このようなシナプストランジスタは、環境との相互作用からリアルタイムで学習しつつ非常に少ない電力で動作する小型ロボット、センサー、ウェアラブルなどの将来のエッジデバイスの基盤を形成し得ます。
引用: Wang, Y., Xiong, W., Yan, J. et al. Brain-inspired synaptic transistors for in-situ spiking reinforcement learning with eligibility trace. Nat Commun 17, 3001 (2026). https://doi.org/10.1038/s41467-026-69898-9
キーワード: ニューロモルフィックハードウェア, 強化学習, スパイキングニューラルネットワーク, 強誘電性トランジスタ, 自動運転