Clear Sky Science · fr
Transistors synaptiques inspirés du cerveau pour un apprentissage par renforcement à impulsions in situ avec trace d’éligibilité
Des machines plus intelligentes inspirées du cerveau
Les machines intelligentes d’aujourd’hui peuvent battre l’humain aux jeux et aider à la conduite, mais le matériel qui exécute ces algorithmes reste très différent de la manière dont le cerveau apprend. Cet article présente un nouveau type de petit dispositif électronique qui reproduit plusieurs astuces clés utilisées par de vraies synapses pour apprendre à partir de récompenses et d’erreurs. En intégrant ces transistors synaptiques dans un réseau simple, les chercheurs montrent qu’une petite voiture-robot peut apprendre à rester dans sa voie de manière efficace sans dépendre d’ordinateurs volumineux et énergivores.
Pourquoi l’apprentissage basé sur la récompense est important
Une grande partie de l’intelligence artificielle moderne ajuste les connexions d’un réseau uniquement en fonction des données d’entrée et de sortie. En revanche, les animaux apprennent non seulement à partir de motifs, mais aussi à partir du succès et de l’échec signalés par des récompenses comme la nourriture ou le plaisir. Les neuroscientifiques modélisent cela par « l’apprentissage par renforcement », où des substances chimiques spéciales dans le cerveau, comme la dopamine, indiquent aux synapses si une action récente était bonne ou mauvaise. Une idée connexe, appelée trace d’éligibilité, permet à une synapse de « se souvenir » temporairement d’une activité récente afin qu’une récompense ultérieure puisse encore renforcer ou affaiblir la connexion de façon appropriée. Reproduire toutes ces fonctionnalités directement dans le matériel pourrait rendre les machines apprenantes plus rapides et bien plus économes en énergie.
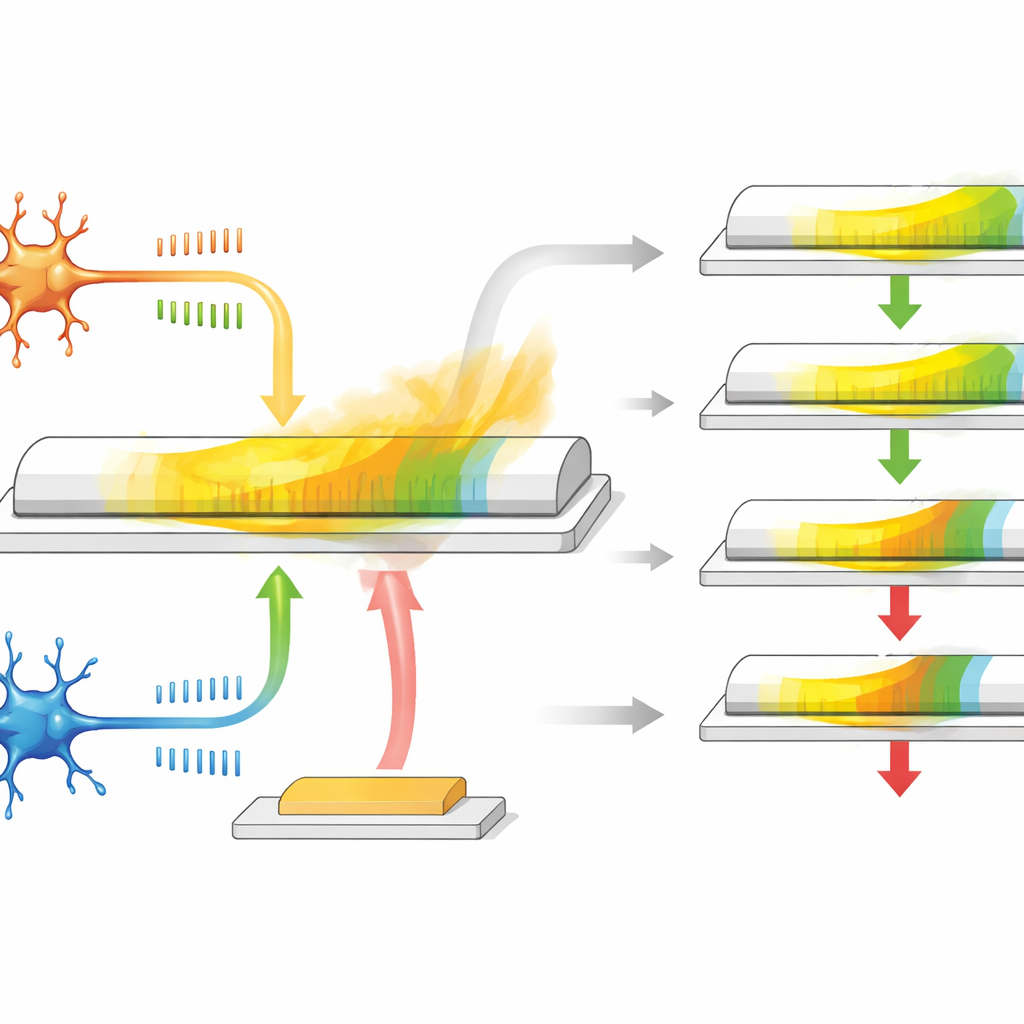
Un seul transistor qui agit comme une synapse
Les auteurs développent un transistor synaptique basé sur un matériau spécial appelé α-In2Se3, à la fois semi-conducteur et ferroélectrique, ce qui signifie que sa polarisation électrique interne peut être inversée et reste stable. Le dispositif possède trois bornes : deux jouent le rôle des extrémités pré- et post-neuronales d’une synapse, tandis que la troisième se comporte comme une entrée de récompense. Lorsque des impulsions de tension de type spike sont appliquées entre les deux premières bornes, la conductance du canal change, imitant la manière dont une synapse se renforce ou s’affaiblit selon le timing des impulsions. Comme la polarisation du matériau se relâche lentement dans le temps, la conductance revient naturellement vers sa valeur initiale, fournissant une mémoire intégrée et décroissante qui fait office de trace d’éligibilité.
Intégrer récompense et mémoire dans la physique
Ce transistor fait plus que stocker une valeur. Sa polarisation dans le plan répond principalement aux signaux représentant l’apprentissage temporel habituel entre deux neurones, tandis que la polarisation hors du plan répond plus fortement aux impulsions appliquées sur la troisième borne, qui sert de signal de récompense. Pendant la période de relaxation après l’activité en impulsions, une impulsion de récompense retardée arrive sur la grille et augmente ou réduit la variation de conductance restante. Si la récompense arrive rapidement, la trace d’éligibilité n’a pas beaucoup décroché, donc la mise à jour du poids est importante ; si la récompense est tardive, l’effet est plus faible. En ajustant la taille et la forme des impulsions électriques, les chercheurs peuvent modifier la durée de la trace d’éligibilité, couvrant une plage comparable aux systèmes biologiques, le tout sans circuits ou éléments de mémoire supplémentaires.
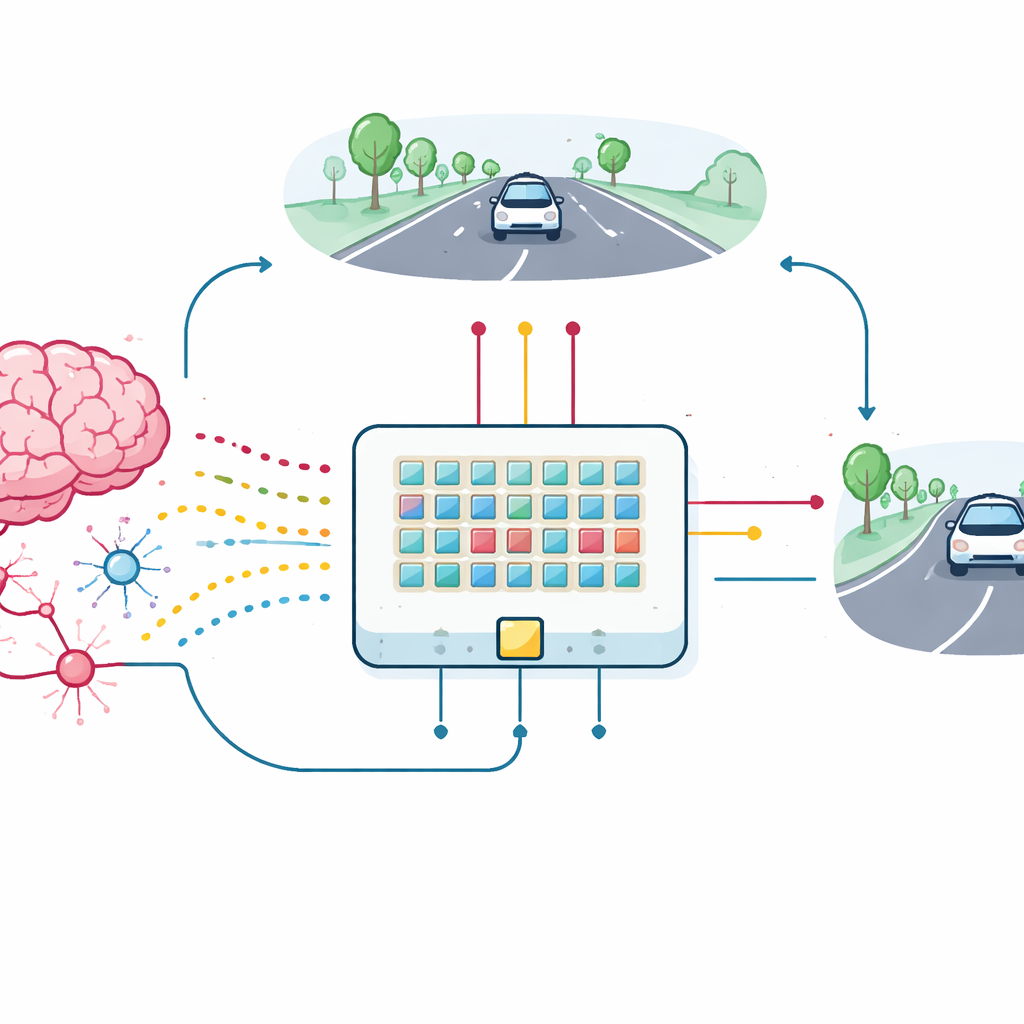
Du dispositif unique à la voiture apprenante
Pour tester la valeur pratique de ces transistors synaptiques, l’équipe a construit un petit réseau de dispositifs et les a connectés en un réseau de neurones à impulsions pour une tâche de maintien de voie. Une vue simple et basse résolution de la route est convertie en rafales d’impulsions entrant dans 18 neurones d’entrée, qui se connectent via les nouvelles synapses à deux neurones de sortie commandant la direction gauche et droite. À mesure que la voiture simulée dérive, elle reçoit un retour basé sur sa capacité à rester centrée dans la voie. Ce retour est transformé en impulsions de récompense qui voyagent vers les troisièmes bornes des transistors synaptiques, mettant à jour leur conductance directement sur la puce. Le réseau, malgré les variations de dispositifs et le bruit, apprend à maintenir la voiture dans sa voie, se rapprochant fortement des performances d’un modèle logiciel idéal.
Ce que cela signifie pour les dispositifs futurs
Ce travail montre qu’un transistor compact unique peut nativement accomplir trois fonctions essentielles pour un apprentissage par renforcement inspiré du cerveau : ajustement temporel de la force synaptique, stockage temporaire de l’activité récente sous forme de trace d’éligibilité, et renforcement ou suppression dirigé par la récompense de cette trace. Parce que tout cela se produit dans la physique même du matériau du dispositif, le matériel obtenu promet d’importantes économies de surface et d’énergie par rapport aux circuits conventionnels qui simulent le même comportement en logiciel. De tels transistors synaptiques pourraient constituer la base d’appareils périphériques futurs — comme de petits robots, capteurs ou objets portables — qui apprennent en temps réel par interaction avec leur environnement tout en consommant très peu d’énergie.
Citation: Wang, Y., Xiong, W., Yan, J. et al. Brain-inspired synaptic transistors for in-situ spiking reinforcement learning with eligibility trace. Nat Commun 17, 3001 (2026). https://doi.org/10.1038/s41467-026-69898-9
Mots-clés: matériel neuromorphique, apprentissage par renforcement, réseaux de neurones à impulsions, transistors ferroélectriques, conduite autonome