Clear Sky Science · nl
Door de hersenen geïnspireerde synaptische transistors voor in-situ spiking reinforcement learning met eligibility trace
Slimmere machines geïnspireerd op de hersenen
De slimme machines van vandaag kunnen mensen verslaan in spelletjes en helpen bij het besturen van auto’s, maar de hardware waarop deze algoritmen draaien verschilt nog sterk van hoe de hersenen leren. Dit artikel presenteert een nieuw soort klein elektronisch apparaat dat meerdere belangrijke trucjes van echte synapsen nabootst om te leren van beloningen en fouten. Door deze synaps-achtige transistors in een eenvoudig netwerk te verwerken, laten de onderzoekers zien dat een kleine robotauto efficiënt kan leren in zijn rijstrook te blijven zonder afhankelijke te zijn van omvangrijke, energieverslindende computers.
Waarom beloningsgestuurd leren ertoe doet
Veel hedendaagse kunstmatige intelligentie past verbindingen in een netwerk alleen aan op basis van invoer- en uitvoergegevens. Dieren daarentegen leren niet alleen van patronen, maar ook van succes en falen die worden aangegeven door beloningen zoals voedsel of plezier. Neurowetenschappers modelleren dit met “reinforcement learning”, waarbij speciale chemicaliën in de hersenen, zoals dopamine, synapsen signaleren of een recente actie goed of slecht was. Een verwant idee, de zogenaamde eligibility trace, laat een synaps tijdelijk recente activiteit ‘onthouden’ zodat een latere beloning die verbinding nog steeds op de juiste manier kan versterken of verzwakken. Al deze eigenschappen rechtstreeks in hardware reproduceren kan leermachines veel sneller en veel energiezuiniger maken.
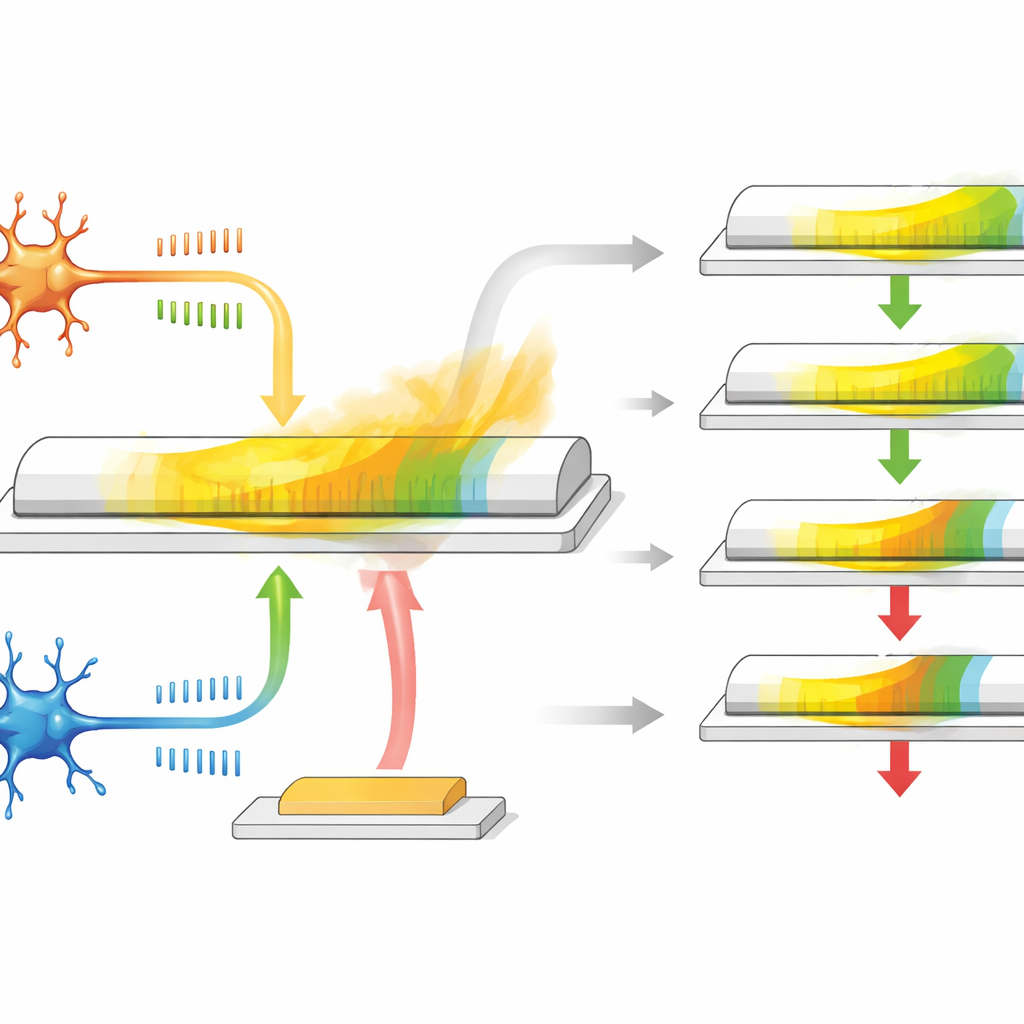
Een enkele transistor die zich gedraagt als een synaps
De auteurs ontwikkelen een synaptische transistor op basis van een speciaal materiaal genaamd α-In2Se3, dat zowel halfgeleidend als ferro-elektrisch is; de interne elektrische polarisatie kan worden omgekeerd en blijft dan bestaan. Het apparaat heeft drie aansluitingen: twee werken als de pre- en post-neuron uiteinden van een synaps, terwijl de derde fungeert als beloningsinvoer. Wanneer spike-achtige spanningspulsen tussen de eerste twee aansluitingen worden toegepast, verandert de geleiding van het kanaal, waarmee wordt nagebootst hoe een synaps sterker of zwakker wordt afhankelijk van het timen van spikes. Omdat de polarisatie van het materiaal langzaam versoepelt in de tijd, keert de geleiding op natuurlijke wijze terug, wat een ingebouwd, geleidelijk vervagend geheugen oplevert dat dienstdoet als de eligibility trace.
Beloning en geheugen ingebouwd in de fysica
Deze transistor doet meer dan alleen een waarde opslaan. De in-vlak polarisatie reageert hoofdzakelijk op signalen die de gebruikelijke timing-gebaseerde leermechanismen tussen twee neuronen vertegenwoordigen, terwijl de uit-van-vlak polarisatie sterker reageert op pulsen die op de derde aansluiting worden toegepast, die als beloningssignaal dient. Tijdens de relaxatieperiode na spike-activiteit arriveert een vertraagde beloningspuls bij de poort en vergroot of verkleint de resterende verandering in geleiding. Als de beloning snel komt, is de eligibility trace nog niet veel vervallen, dus is de gewichtsupdate groot; als de beloning laat komt, is het effect kleiner. Door de grootte en vorm van de elektrische pulsen te tunen, kunnen de onderzoekers aanpassen hoe lang de eligibility trace aanhoudt, over een bereik vergelijkbaar met biologische systemen, en dat alles zonder extra schakelingen of geheugenelementen.
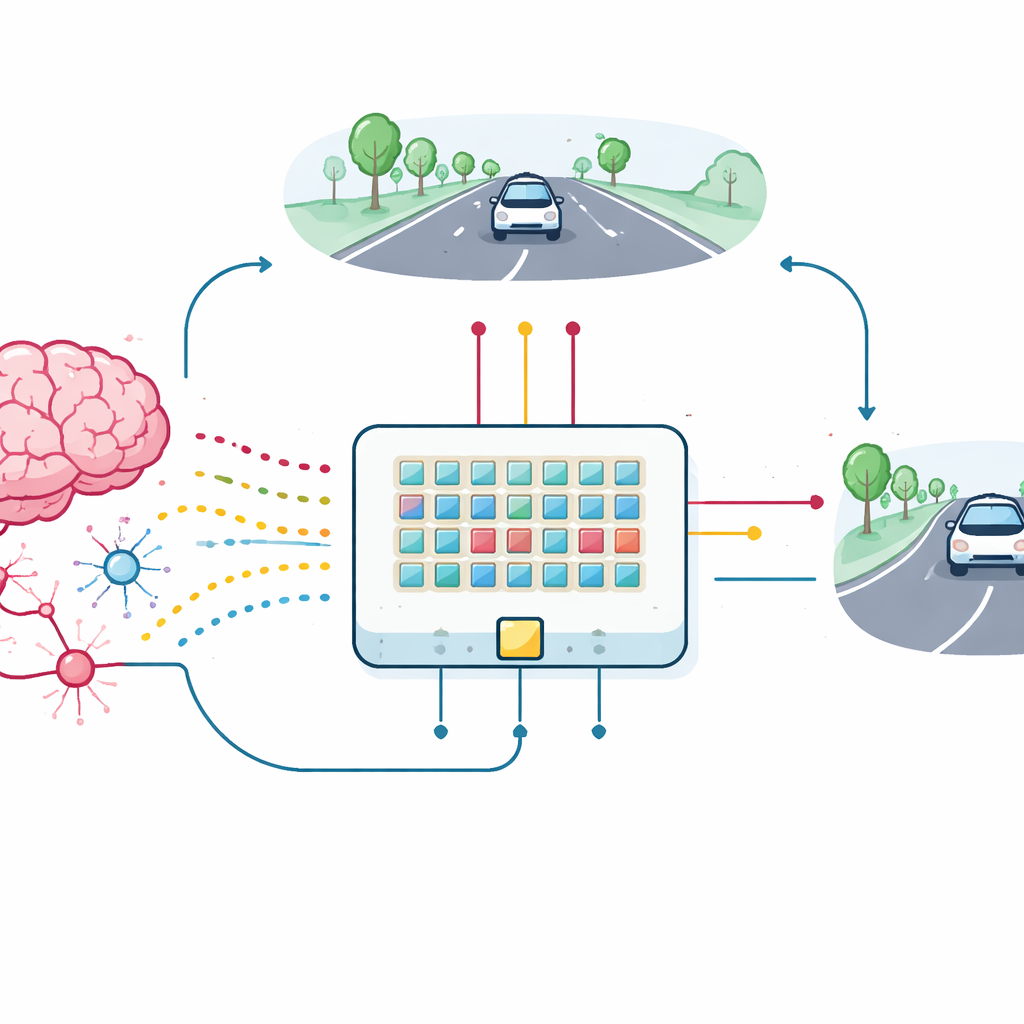
Van enkel apparaat naar lerende auto
Om de praktische waarde van deze synaptische transistors te testen bouwde het team een kleine array van apparaten en verbond deze tot een spiking neurale netwerk voor een lane-keeping taak. Een eenvoudige, laagresolutie weergave van de weg voor zich wordt omgezet in pulsen die binnenkomen in 18 inputneuronen, die op hun beurt via de nieuwe synapsen verbinden met twee outputneuronen die links- en rechtssturing aansturen. Terwijl de gesimuleerde auto rijdt, ontvangt hij feedback op basis van hoe goed hij gecentreerd blijft in de rijstrook. Deze feedback wordt omgezet in beloningspulsen die naar de derde aansluitingen van de synaptische transistors reizen en hun geleiding direct op de chip bijwerken. De array leert, zelfs met variaties tussen apparaten en ruis, de auto in de rijstrook te houden en komt daarbij dicht in de buurt van de prestatie van een ideaal softwaremodel.
Wat dit betekent voor toekomstige apparaten
Het werk toont aan dat een enkele, compacte transistor van nature drie essentiële functies voor hersenachtig reinforcement learning kan vervullen: timing-gebaseerde aanpassing van synaptische sterkte, tijdelijke opslag van recente activiteit als een eligibility trace, en beloningsgestuurde versterking of onderdrukking van die trace. Omdat dit alles in de materiaalfysica van het apparaat zelf gebeurt, belooft de resulterende hardware aanzienlijke besparingen in oppervlakte en energie in vergelijking met conventionele schakelingen die hetzelfde gedrag in software simuleren. Dergelijke synaptische transistors zouden de basis kunnen vormen van toekomstige edge-apparaten — zoals kleine robots, sensoren of wearables — die in realtime leren van interactie met hun omgeving terwijl ze zeer weinig energie verbruiken.
Bronvermelding: Wang, Y., Xiong, W., Yan, J. et al. Brain-inspired synaptic transistors for in-situ spiking reinforcement learning with eligibility trace. Nat Commun 17, 3001 (2026). https://doi.org/10.1038/s41467-026-69898-9
Trefwoorden: neuromorfe hardware, reinforcement learning, spiking neurale netwerken, ferro-elektrische transistors, autonoom rijden