Clear Sky Science · sv
Lättviktsmodell LMW-YOLO för detektering av små objekt i fjärranalysbilder
Att se de små sakerna från rymden
Från stadstrafik till fartyg i en hamn framträder mycket av det som är viktigt på jorden som små prickar i flyg- och satellitbilder. Att lära datorer att pålitligt upptäcka dessa små objekt är dock oväntat svårt, särskilt på lättviktiga enheter som drönare eller små satelliter. Denna artikel presenterar LMW-YOLO, ett kompakt men kraftfullt visionsystem särskilt utformat för att hitta mycket små objekt i stora, röriga fjärranalysbilder utan att kräva tung beräkningskraft.
Varför små mål är svåra att hitta
Fjärranalysbilder tas högt ovanifrån, så bilar, båtar och människor syns ofta bara som några få pixlar breda. Standarddetektorer, såsom den populära YOLO-familjen, förminskar bilder lager för lager för att snabba upp bearbetningen och fånga högre abstraktioner. Men för objekt som bara är 5–10 pixlar över kan denna nedsampling sudda ut dem innan nätverket ens "ser" dem. Tidigare försök att lösa problemet har vanligtvis förlitat sig på djupare nätverk, uppmärksamhetsmekanismer eller Transformer-liknande modeller. Dessa metoder kan förbättra noggrannheten, men de tenderar att bli för tunga för drönare, satelliter eller kantenheter med begränsat minne och energi. Det finns en spänning mellan att hålla modeller små och samtidigt bevara tillräckligt med detalj för att känna igen mycket små mål i komplexa bakgrunder av byggnader, träd och vatten.
Att skräddarsy nätverket efter varje nivå
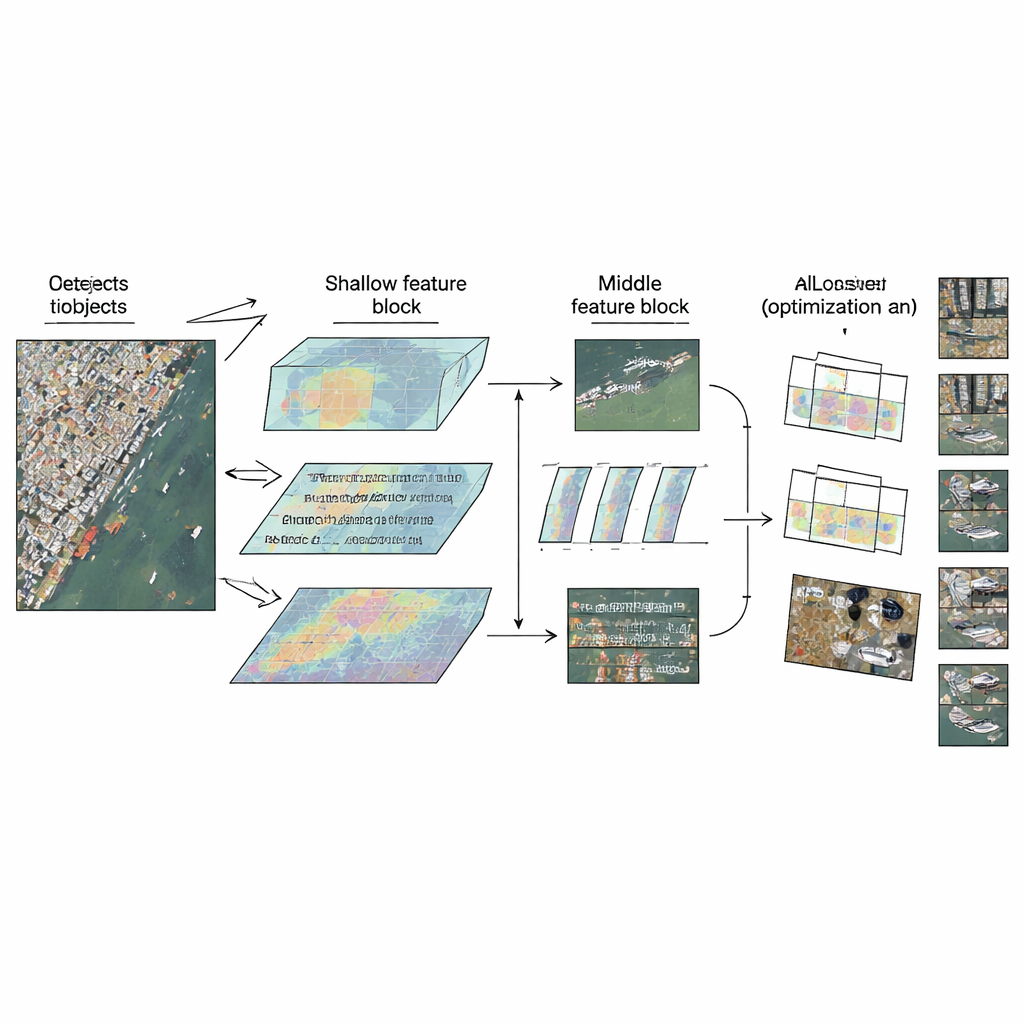
LMW-YOLO utgår från en modern lättvikts-YOLO-backbone och bryter sedan med en vanlig designvana: att behandla alla lager likadant. Istället för att använda en enhetlig byggsten överallt föreslår författarna en "Context-Scale Decoupled"-strategi som ger varje del av nätverket en specialiserad roll. I det grunda stadiet, där bilder fortfarande är relativt stora, har modellen svårt att se tillräckligt långt för att tolka små objekt i sitt sammanhang. Här lägger författarna till en Large-Kernel Context Aggregation (LKCA)-modul som efterliknar stora filterfönster genom att kombinera flera mindre, effektiva konvolutioner. Detta låter nätverket betrakta ett större område samtidigt som fina detaljer som är viktiga för små bilar eller fartyg bevaras. I mellanstadiet skiftar utmaningen: modellen måste hantera objekt i mycket olika storlekar utan att förlora rumslig skärpa.
Att se på många skalor samtidigt
För att hantera denna variation introducerar författarna en Multi-Scale Dilated Perception (MSDP)-modul i de djupare feature-kartorna. Denna modul delar informationen i två vägar. Den ena vägen passerar oförändrad och bevarar skarpa positionsdetaljer. Den andra passerar genom en uppsättning parallella konvolutionsgrenar som var och en "ser" på olika räckvidder, från mycket lokalt till bredare regioner, tack vare dilaterade filter med olika mellanrum. Genom att slå samman dessa strömmar får nätverket en rik multi-skala vy: det kan skilja mellan tätt packade små fordon, större fartyg och utsträckta strukturer som broar, samtidigt som kostnaden i parametrar och beräkningar hålls extremt låg. Tillsammans låter LKCA och MSDP nätverket uppmärksamma både lokala detaljer och bredare kontext i de lager där vardera är viktigast.
Smartare lärande från ofullständig data
Även med bättre features är träning på verkliga flygbilder knepig. Fjärranalysdataset innehåller ofta brusiga etiketter, delvis dolda objekt eller udda former som förvirrar konventionella träningsförluster. Många YOLO-liknande modeller använder fasta regler som behandlar alla träningsexempel lika, vilket kan låta några dåliga exempel generera missvisande uppdateringar och sakta ned eller destabilisera inlärningen. LMW-YOLO ersätter detta med ett system kallat Wise-IoU v3, som justerar hur starkt varje exempel påverkar träningen baserat på hur väl det för närvarande passar. Exempel som redan är mycket bra eller uppenbart dåliga nedviktas, medan de "svåra men användbara" fallen framhävs. Denna dynamiska fokusering hjälper modellen att konvergera snabbare och förbättrar hur precist den ritar rutor kring små, trånga objekt.
Bevisa att det fungerar i verkligheten
Teamet testar LMW-YOLO på tre krävande benchmarkar: ett högupplöst satellitdataset (NWPU VHR-10), en specialiserad samling av extremt små mål (RS-STOD) och ett stort drönarbildsset med kraftig trängsel och ocklusion (VisDrone2019). Över alla tre presterar den nya modellen bättre än en rad nyare detektorer, inklusive flera större och mer komplexa system, samtidigt som den använder endast cirka 2,6 miljoner parametrar och måttliga beräkningar. Den körs också i realtid eller nära realtid på vanliga CPU:er, vilket tyder på att den är praktisk att distribuera på drönare och små plattformar, inte bara i kraftfulla datacenter.
Vad detta betyder framöver
För läsaren är huvudbudskapet att vi inte längre behöver göra ett så skarpt val mellan noggrannhet och effektivitet när det gäller att upptäcka små objekt uppifrån. Genom att noggrant skräddarsy hur olika lager i ett nätverk hanterar detalj och kontext, och genom att träna det med en förlustfunktion som lär sig att bortse från missvisande exempel, levererar LMW-YOLO skarpare, mer pålitliga detektioner samtidigt som modellen hålls tillräckligt liten för verkliga flyg- och satellitenheter. Detta gör den till en lovande byggsten för tillämpningar som spänner från trafikövervakning och hamnsäkerhet till katastrofinsatser och miljöövervakning, där varje litet objekt i en massiv bild kan bära viktig information.
Citering: Qiu, Y., Lin, Z. Lightweight model LMW-YOLO for small object detection in remote sensing images. Sci Rep 16, 11644 (2026). https://doi.org/10.1038/s41598-026-45055-6
Nyckelord: fjärranalys, detektion av små objekt, lättviktsdjupinlärning, flygbilder, YOLO-arkitektur