Clear Sky Science · fr
Modèle léger LMW-YOLO pour la détection de petits objets dans les images de télédétection
Voir les petites choses depuis l'espace
Des embouteillages urbains aux navires dans un port, une grande partie de ce qui compte sur Terre apparaît comme de minuscules points dans les photos aériennes et satellitaires. Pourtant, apprendre aux ordinateurs à repérer de manière fiable ces petits objets est étonnamment difficile, surtout sur des appareils légers comme les drones ou les petits satellites. Cet article présente LMW-YOLO, un système de vision compact mais performant conçu spécifiquement pour trouver des objets très petits dans de larges images de télédétection encombrées, sans nécessiter une forte puissance de calcul.
Pourquoi les cibles minuscules sont difficiles à détecter
Les images de télédétection sont prises de très haut, si bien que les voitures, bateaux et personnes n’apparaissent souvent qu’avec quelques pixels de large. Les détecteurs d’objets standards, tels que la populaire famille YOLO, réduisent les images couche par couche pour accélérer le traitement et capturer des motifs de haut niveau. Mais pour des objets de seulement 5 à 10 pixels de diamètre, cet échantillonnage peut les effacer avant même que le réseau ne « les voie ». Les tentatives antérieures pour résoudre ce problème ont généralement reposé sur des réseaux plus profonds, des mécanismes d’attention ou des modèles de type Transformer. Ces approches peuvent améliorer la précision, mais elles sont souvent trop lourdes pour les drones, les satellites ou les appareils en périphérie disposant de mémoire et d’alimentation limitées. Il existe une tension entre garder les modèles légers et conserver suffisamment de détail pour reconnaître des cibles minuscules dans des arrière-plans complexes de bâtiments, d’arbres et d’eau.
Adapter le réseau à chaque niveau
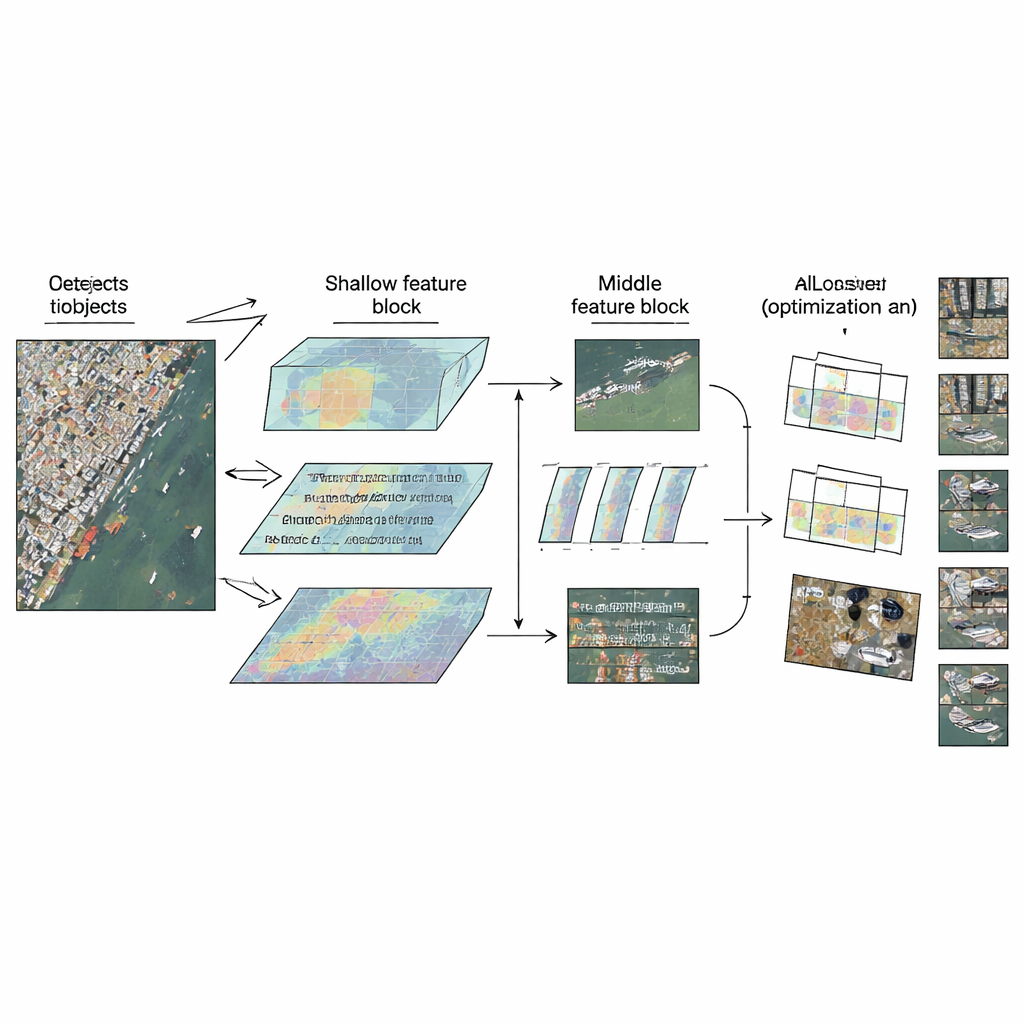
LMW-YOLO part d’une architecture YOLO légère moderne puis rompt avec une habitude de conception courante : traiter toutes les couches de la même manière. Plutôt que d’utiliser un même bloc partout, les auteurs proposent une stratégie « Context-Scale Decoupled » qui confère à chaque partie du réseau un rôle spécialisé. Au stade peu profond, où les images sont encore relativement grandes, le modèle a du mal à voir suffisamment loin pour interpréter les petits objets dans leur contexte. Là, les auteurs ajoutent un module Large-Kernel Context Aggregation (LKCA) qui imite de très grandes fenêtres de filtrage en combinant plusieurs convolutions plus petites et efficaces. Cela permet au réseau de considérer une zone plus large tout en préservant les détails fins importants pour des petites voitures ou des navires. Au stade intermédiaire, le défi change : le modèle doit gérer des objets de tailles très différentes sans perdre en netteté spatiale.
Regarder plusieurs échelles à la fois
Pour faire face à cette variété, les auteurs introduisent un module Multi-Scale Dilated Perception (MSDP) dans les cartes de caractéristiques plus profondes. Ce module divise l’information en deux voies. Une voie passe sans modification, préservant des détails positionnels nets. L’autre emprunte un jeu de branches de convolution parallèles qui « voient » chacune à des portées différentes, des régions très locales à des zones plus larges, grâce à des dilatations de tailles variées. En recomposant ces flux, le réseau acquiert une vue multi-échelle riche : il peut distinguer des véhicules petits et serrés, des navires plus grands et des structures étendues comme des ponts, tout en maintenant un coût de paramètres et de calcul extrêmement faible. Ensemble, LKCA et MSDP permettent au réseau de prêter attention à la fois aux détails locaux et au contexte plus large dans les couches où chacun est le plus pertinent.
Apprendre plus intelligemment à partir de données imparfaites
Même avec de meilleures caractéristiques, l’entraînement sur des données aériennes réelles reste délicat. Les jeux de données de télédétection contiennent souvent des annotations bruitées, des objets partiellement cachés ou des formes atypiques qui perturbent les fonctions de perte classiques. Beaucoup de modèles de type YOLO utilisent des règles fixes qui traitent tous les exemples d’entraînement de la même manière, ce qui peut permettre à quelques mauvais exemples de générer des mises à jour trompeuses et de ralentir ou déstabiliser l’apprentissage. LMW-YOLO remplace cela par un schéma appelé Wise-IoU v3, qui ajuste l’influence de chaque exemple sur l’entraînement en fonction de son degré d’ajustement actuel. Les exemples déjà très bons ou clairement mauvais sont sous-pondérés, tandis que les cas « difficiles mais utiles » sont accentués. Ce recentrage dynamique aide le modèle à converger plus rapidement et améliore la précision des boîtes autour d’objets petits et encombrés.
Preuves de performance en conditions réelles
L’équipe évalue LMW-YOLO sur trois jeux de référence exigeants : un jeu de données satellitaires haute résolution (NWPU VHR-10), une collection spécialisée de cibles extrêmement petites (RS-STOD) et un grand ensemble d’images de drones avec forte densité et occlusions (VisDrone2019). Sur les trois, le nouveau modèle surpasse une gamme de détecteurs récents, y compris plusieurs systèmes plus grands et plus complexes, tout en n’utilisant qu’environ 2,6 millions de paramètres et un coût de calcul modeste. Il fonctionne également en temps réel ou quasi temps réel sur des CPU standards, ce qui indique qu’il est pratique pour un déploiement sur drones et petites plateformes, et pas seulement dans des centres de données puissants.
Ce que cela signifie pour l’avenir
Pour le lectorat, le message clé est que l’on n’a plus à choisir aussi radicalement entre précision et efficacité pour repérer de minuscules objets depuis les hauteurs. En adaptant soigneusement la manière dont différentes couches d’un réseau traitent le détail et le contexte, et en l’entraînant avec une fonction de perte qui apprend à ignorer les exemples trompeurs, LMW-YOLO fournit des détections plus nettes et plus fiables tout en restant suffisamment compact pour les dispositifs aériens et satellitaires réels. Cela en fait un composant prometteur pour des applications allant de la surveillance du trafic et la sécurité portuaire à la réponse aux catastrophes et aux relevés environnementaux, là où chaque petit objet dans une image massive peut porter une information importante.
Citation: Qiu, Y., Lin, Z. Lightweight model LMW-YOLO for small object detection in remote sensing images. Sci Rep 16, 11644 (2026). https://doi.org/10.1038/s41598-026-45055-6
Mots-clés: télédétection, détection de petits objets, apprentissage profond léger, imagerie aérienne, architecture YOLO