Clear Sky Science · de
Leichtgewichtiges Modell LMW-YOLO zur Erkennung kleiner Objekte in Fernerkundungsbildern
Die kleinen Dinge aus dem All sehen
Von Stadtverkehr bis zu Schiffen im Hafen: Vieles, was auf der Erde wichtig ist, erscheint in Luft- und Satellitenaufnahmen nur als winzige Punkte. Computern zuverlässig beizubringen, diese kleinen Objekte zu erkennen, ist jedoch überraschend schwierig, besonders auf leichten Geräten wie Drohnen oder kleinen Satelliten. Dieses Papier stellt LMW-YOLO vor, ein kompaktes, aber leistungsfähiges Visionsystem, das speziell dafür entwickelt wurde, sehr kleine Objekte in großen, unübersichtlichen Fernerkundungsbildern zu finden, ohne großen Rechenaufwand zu benötigen.
Warum winzige Ziele schwer zu finden sind
Fernerkundungsbilder werden aus großer Höhe aufgenommen, sodass Autos, Boote und Menschen oft nur wenige Pixel breit erscheinen. Standard-Objektdetektoren, etwa die verbreitete YOLO-Familie, verkleinern Bilder schrittweise, um die Verarbeitung zu beschleunigen und abstrakte Muster zu erfassen. Bei Objekten, die nur 5–10 Pixel groß sind, kann dieses Downsampling sie jedoch auslöschen, bevor das Netzwerk sie überhaupt „sieht“. Frühere Versuche, dieses Problem zu beheben, setzten meist auf tiefere Netze, Aufmerksamkeitsmechanismen oder Transformer-ähnliche Modelle. Diese Ansätze können die Genauigkeit verbessern, sind aber oft zu schwer für Drohnen, Satelliten oder Edge-Geräte mit begrenztem Speicher und Energie. Es besteht also ein Spannungsfeld zwischen der Modellkompaktheit und dem Erhalt genügend feiner Details, um winzige Ziele in komplexen Umgebungen aus Gebäuden, Bäumen und Wasser zu erkennen.
Das Netzwerk pro Ebene maßschneidern
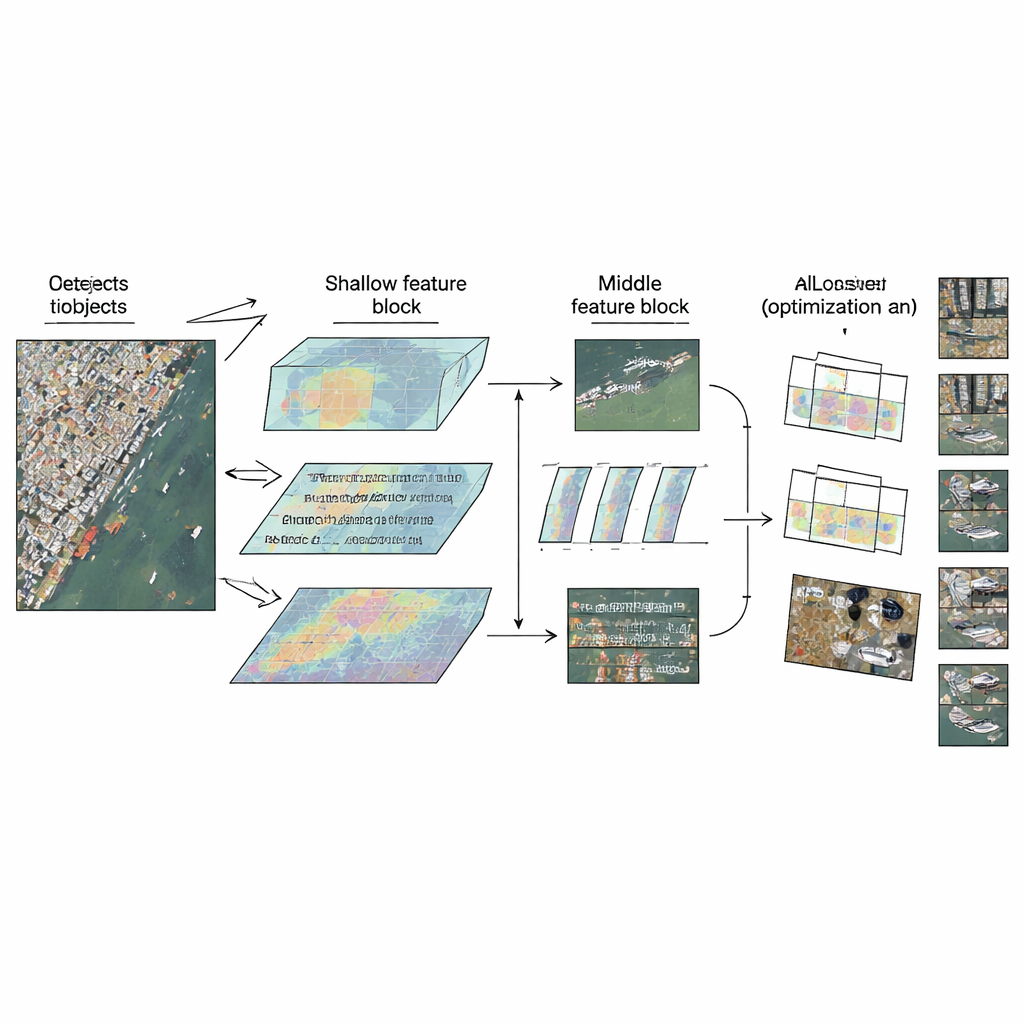
LMW-YOLO beginnt mit einem modernen, leichtgewichtigen YOLO-Backbone und bricht dann mit einer gängigen Designgewohnheit: alle Schichten gleich zu behandeln. Statt überall denselben Baustein zu verwenden, schlagen die Autoren eine „Context-Scale Decoupled“-Strategie vor, die jedem Netzwerkbereich eine spezialisierte Rolle zuweist. In der flachen Stufe, in der die Bilder noch relativ groß sind, fällt es dem Modell schwer, weit genug zu schauen, um winzige Objekte im Kontext zu interpretieren. Hier fügen die Autoren ein Large-Kernel Context Aggregation (LKCA)-Modul hinzu, das riesige Filterfenster nachahmt, indem mehrere kleinere, effiziente Faltungen kombiniert werden. Dadurch kann das Netzwerk über einen größeren Bereich blicken und gleichzeitig feine Details erhalten, die für kleine Autos oder Schiffe wichtig sind. In der mittleren Stufe verschiebt sich die Herausforderung: Das Modell muss Objekte sehr unterschiedlicher Grössen verarbeiten, ohne räumliche Schärfe zu verlieren.
Viele Skalen gleichzeitig betrachten
Um mit dieser Vielfalt fertigzuwerden, führen die Autoren in tieferen Merkmalskarten ein Multi-Scale Dilated Perception (MSDP)-Modul ein. Dieses Modul teilt die Informationen in zwei Pfade. Ein Pfad wird unverändert weitergegeben und bewahrt scharfe Positionsdetails. Der andere durchläuft eine Reihe paralleler Faltungszweige, die dank dilatierten Filtern mit unterschiedlichen Abständen jeweils in unterschiedlichen Bereichen „sehen“, von sehr lokal bis breiter. Durch das Wiederzusammenführen dieser Ströme erhält das Netzwerk eine reichhaltige Mehrskalenansicht: Es kann eng beieinander stehende kleine Fahrzeuge, größere Schiffe und ausgedehnte Strukturen wie Brücken unterscheiden, während Parameter- und Rechenkosten sehr gering bleiben. Zusammen ermöglichen LKCA und MSDP dem Netzwerk, in den Schichten, in denen es besonders wichtig ist, sowohl auf lokale Details als auch auf weiteren Kontext zu achten.
Intelligenteres Lernen aus unvollkommenen Daten
Selbst mit besseren Merkmalen ist das Training an realen Luftdaten heikel. Fernerkundungsdatensätze enthalten oft verrauschte Labels, teilweise verdeckte Objekte oder ungewöhnliche Formen, die konventionelle Trainingsverluste verwirren. Viele YOLO-ähnliche Modelle nutzen feste Regeln, die alle Trainingsbeispiele gleich behandeln, sodass einige wenige schlechte Beispiele irreführende Aktualisierungen erzeugen und das Lernen verlangsamen oder destabilisieren können. LMW-YOLO ersetzt dies durch ein Schema namens Wise-IoU v3, das die Einflussstärke jedes Beispiels auf das Training anpasst, basierend darauf, wie gut es momentan passt. Beispiele, die bereits sehr gut oder eindeutig schlecht sind, werden heruntergewichtet, während „schwierige, aber nützliche“ Fälle betont werden. Dieses dynamische Fokussieren hilft dem Modell, schneller zu konvergieren und verbessert die Präzision der Begrenzungsboxen bei kleinen, dicht gedrängten Objekten.
Demonstration der Praxistauglichkeit
Das Team testet LMW-YOLO auf drei anspruchsvollen Benchmarks: einem hochauflösenden Satellitendatensatz (NWPU VHR-10), einer spezialisierten Sammlung extrem winziger Ziele (RS-STOD) und einem großen Drohnenbildsatz mit starker Überfüllung und Verdeckung (VisDrone2019). Über alle drei Datensätze hinweg übertrifft das neue Modell eine Reihe aktueller Detektoren, einschließlich mehrerer größerer und komplexerer Systeme, und das bei nur etwa 2,6 Millionen Parametern und moderatem Rechenaufwand. Es läuft zudem in Echtzeit oder beinahe Echtzeit auf Standard-CPUs, was darauf hindeutet, dass es praktikabel für den Einsatz auf Drohnen und kleinen Plattformen ist und nicht nur in leistungsstarken Rechenzentren.
Was das für die Zukunft bedeutet
Für die Leserschaft ist die Kernbotschaft: Wir müssen nicht länger so strikt zwischen Genauigkeit und Effizienz wählen, wenn es darum geht, winzige Objekte aus der Luft zu erkennen. Durch die gezielte Anpassung, wie verschiedene Schichten eines Netzwerks Detail und Kontext behandeln, und durch das Training mit einer Verlustfunktion, die lernt, irreführende Beispiele zu ignorieren, liefert LMW-YOLO schärfere, zuverlässigere Erkennungen und bleibt gleichzeitig klein genug für reale Luft- und Satellitenplattformen. Das macht es zu einem vielversprechenden Baustein für Anwendungen von Verkehrsüberwachung und Hafensicherheit bis hin zu Katastrophenhilfe und Umweltuntersuchungen, bei denen jedes winzige Objekt in einem riesigen Bild wichtige Informationen tragen kann.
Zitation: Qiu, Y., Lin, Z. Lightweight model LMW-YOLO for small object detection in remote sensing images. Sci Rep 16, 11644 (2026). https://doi.org/10.1038/s41598-026-45055-6
Schlüsselwörter: Fernerkundung, Erkennung kleiner Objekte, leichtgewichtiges Deep Learning, Luftbilder, YOLO-Architektur