Clear Sky Science · it
Modello leggero LMW-YOLO per il rilevamento di piccoli oggetti in immagini di telerilevamento
Vedere le cose piccole dallo spazio
Dai percorsi del traffico cittadino alle navi in un porto, gran parte di ciò che conta sulla Terra appare come minuscoli puntini nelle fotografie aeree e satellitari. Eppure insegnare ai computer a individuare in modo affidabile questi oggetti minuscoli è sorprendentemente difficile, soprattutto su dispositivi leggeri come droni o piccoli satelliti. Questo articolo presenta LMW-YOLO, un sistema visivo compatto ma potente progettato specificamente per trovare oggetti molto piccoli in ampie e caotiche immagini di telerilevamento senza richiedere un elevato carico di calcolo.
Perché è difficile trovare bersagli minuscoli
Le immagini di telerilevamento sono acquisite da grandi altezze, quindi automobili, imbarcazioni e persone appaiono spesso larghe solo pochi pixel. I rilevatori di oggetti standard, come la popolare famiglia YOLO, riducono le immagini strato dopo strato per accelerare l'elaborazione e catturare pattern di alto livello. Ma per oggetti di appena 5–10 pixel di larghezza, questo sottocampionamento può cancellarli prima ancora che la rete li "veda". I tentativi precedenti per risolvere il problema si sono tipicamente affidati a reti più profonde, meccanismi di attenzione o modelli in stile Transformer. Questi approcci possono migliorare la precisione, ma tendono a essere troppo pesanti per droni, satelliti o dispositivi edge con memoria e potenza limitate. Esiste quindi una tensione tra mantenere i modelli piccoli e conservare dettagli sufficienti per riconoscere bersagli minuscoli in contesti complessi di edifici, alberi e specchi d'acqua.
Adattare la rete a ogni livello
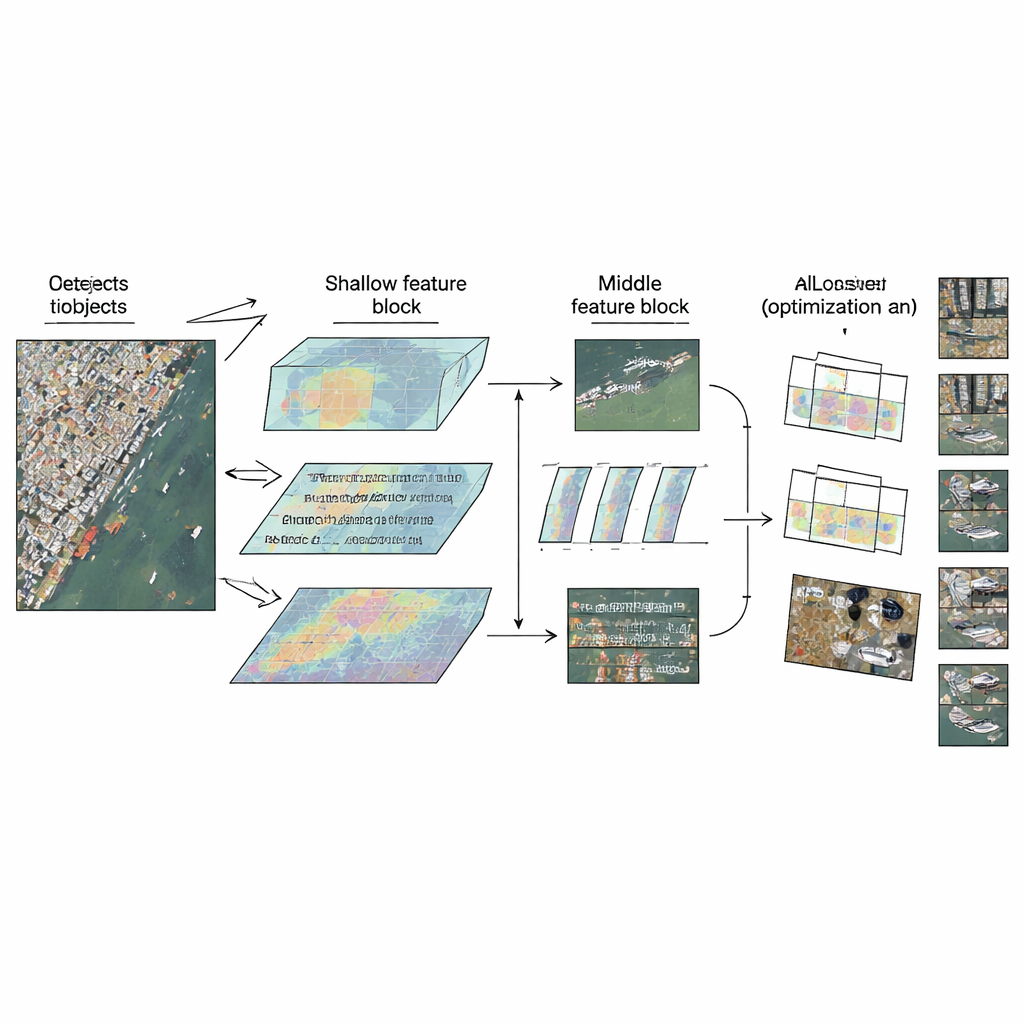
LMW-YOLO parte da un backbone YOLO moderno e leggero e poi rompe una pratica comune: trattare tutti gli strati allo stesso modo. Invece di usare un blocco uniforme ovunque, gli autori propongono una strategia "Context-Scale Decoupled" che assegna a ciascuna parte della rete un ruolo specializzato. Nello stadio superficiale, dove le immagini sono ancora relativamente grandi, il modello fatica a guardare abbastanza lontano per interpretare i piccoli oggetti nel loro contesto. Qui gli autori aggiungono un modulo Large-Kernel Context Aggregation (LKCA) che imita finestre di filtro molto ampie combinando diverse convoluzioni più piccole ed efficienti. Questo permette alla rete di osservare un'area più ampia preservando comunque i dettagli fini importanti per auto o navi minuscole. Nello stadio intermedio, la sfida cambia: il modello deve gestire oggetti di dimensioni molto diverse senza perdere nitidezza spaziale.
Osservare molte scale contemporaneamente
Per far fronte a questa varietà, gli autori introducono un modulo Multi-Scale Dilated Perception (MSDP) nelle mappe di feature più profonde. Questo modulo divide l'informazione in due percorsi. Un percorso passa senza modifiche, preservando dettagli posizionali nitidi. L'altro passa attraverso un insieme di rami convoluzionali paralleli che "vedono" ognuno a diverse estensioni, da regioni molto locali a aree più ampie, grazie a filtri dilatati con gap differenti. Ricombinando questi flussi, la rete acquisisce una ricca visione multi-scala: può distinguere tra veicoli piccoli e fitti, navi più grandi e strutture estese come ponti, mantenendo al contempo un costo in parametri e computazione estremamente basso. Insieme, LKCA e MSDP permettono alla rete di prestare attenzione sia ai dettagli locali sia al contesto più ampio negli strati in cui ciascuno è più rilevante.
Apprendere in modo più intelligente da dati imperfetti
Anche con feature migliori, l'addestramento su dati aerei reali è complicato. I dataset di telerilevamento spesso contengono etichette rumorose, oggetti parzialmente nascosti o forme anomale che confondono le funzioni di perdita convenzionali. Molti modelli in stile YOLO usano regole fisse che trattano tutti gli esempi di addestramento allo stesso modo, permettendo a pochi esempi errati di generare aggiornamenti fuorvianti e rallentare o destabilizzare l'apprendimento. LMW-YOLO sostituisce questo approccio con uno schema chiamato Wise-IoU v3, che regola la forza con cui ogni esempio influenza l'addestramento in base a quanto esso si adatta attualmente. Gli esempi già molto buoni o chiaramente pessimi vengono attenuati, mentre i casi "difficili ma utili" vengono enfatizzati. Questo focus dinamico aiuta il modello a convergere più rapidamente e migliora la precisione con cui disegna box attorno a oggetti piccoli e affollati.
Dimostrare che funziona nel mondo reale
Il team testa LMW-YOLO su tre benchmark impegnativi: un dataset satellitare ad alta risoluzione (NWPU VHR-10), una raccolta specializzata di bersagli estremamente piccoli (RS-STOD) e un ampio set di immagini da drone con forte affollamento e occlusione (VisDrone2019). Su tutti e tre, il nuovo modello supera una serie di rilevatori recenti, inclusi diversi sistemi più grandi e complessi, utilizzando allo stesso tempo solo circa 2,6 milioni di parametri e un'operatività computazionale moderata. Gira inoltre in tempo reale o quasi in tempo reale su CPU standard, indicando che è praticabile per il dispiegamento su droni e piccole piattaforme, non solo nei potenti data center.
Cosa significa per il futuro
Per i lettori, il messaggio chiave è che non è più necessario scegliere in modo così netto tra accuratezza ed efficienza quando si tratta di individuare oggetti minuscoli dall'alto. Adattando con cura il modo in cui i diversi strati di una rete gestiscono dettaglio e contesto, e addestrandola con una funzione di perdita che impara a ignorare esempi fuorvianti, LMW-YOLO offre rilevamenti più nitidi e affidabili rimanendo sufficientemente piccolo per dispositivi aerei e satellitari reali. Questo lo rende un elemento promettente per applicazioni che vanno dal monitoraggio del traffico e la sicurezza dei porti alla risposta a disastri e indagini ambientali, dove ogni piccolo oggetto in un'immagine enorme può contenere informazioni importanti.
Citazione: Qiu, Y., Lin, Z. Lightweight model LMW-YOLO for small object detection in remote sensing images. Sci Rep 16, 11644 (2026). https://doi.org/10.1038/s41598-026-45055-6
Parole chiave: telerilevamento, rilevamento di piccoli oggetti, deep learning leggero, immagini aeree, architettura YOLO