Clear Sky Science · en
Lightweight model LMW-YOLO for small object detection in remote sensing images
Seeing the Small Things from Space
From city traffic to ships in a harbor, much of what matters on Earth shows up as tiny specks in aerial and satellite photos. Yet teaching computers to reliably spot these tiny objects is surprisingly hard, especially on lightweight devices like drones or small satellites. This paper introduces LMW-YOLO, a compact but powerful vision system designed specifically to find very small objects in large, cluttered remote sensing images without needing heavy computing power.
Why Tiny Targets Are Hard to Find
Remote sensing images are taken from high above, so cars, boats, and people often appear just a few pixels wide. Standard object detectors, such as the popular YOLO family, shrink images layer by layer to speed up processing and capture high-level patterns. But for objects only 5–10 pixels across, this downsampling can erase them before the network ever "sees" them. Earlier attempts to fix this problem have typically relied on deeper networks, attention mechanisms, or Transformer-style models. These approaches can improve accuracy, but they tend to be too heavy for drones, satellites, or edge devices with limited memory and power. There is a tension between keeping models small and keeping enough detail to recognize tiny targets in complex backgrounds of buildings, trees, and water.
Tailoring the Network to Each Level
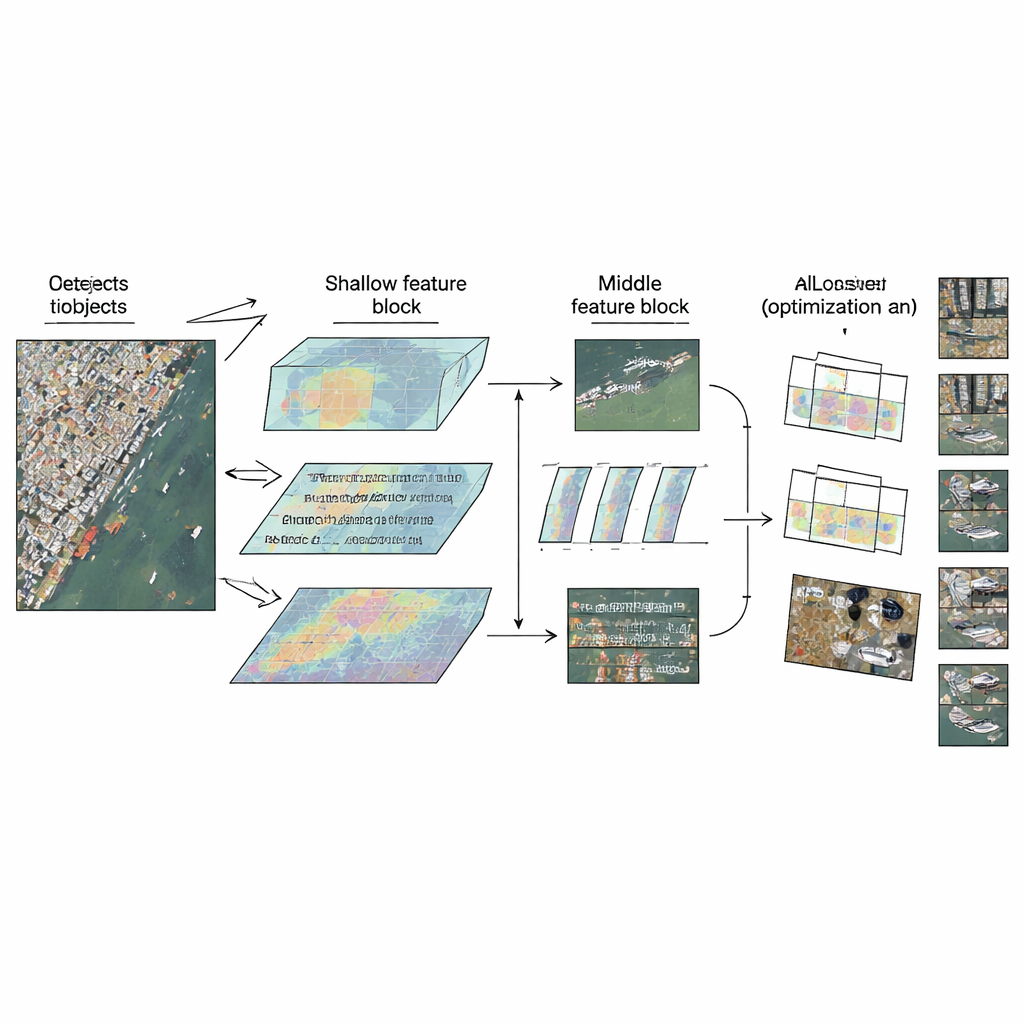
LMW-YOLO starts from a modern lightweight YOLO backbone and then breaks with a common design habit: treating all layers the same. Instead of using one uniform building block everywhere, the authors propose a "Context-Scale Decoupled" strategy that gives each part of the network a specialized role. In the shallow stage, where images are still relatively large, the model struggles to see far enough to interpret tiny objects in context. Here, the authors add a Large-Kernel Context Aggregation (LKCA) module that mimics huge filter windows by combining several smaller, efficient convolutions. This lets the network look over a wider area while still preserving fine details important for tiny cars or ships. In the middle stage, the challenge shifts: the model must handle objects of very different sizes without losing spatial sharpness.
Looking at Many Scales at Once
To cope with this variety, the authors introduce a Multi-Scale Dilated Perception (MSDP) module in the deeper feature maps. This module splits the information into two paths. One path passes through unchanged, preserving crisp positional details. The other passes through a set of parallel convolution branches that each "see" at different ranges, from very local to broader regions, thanks to dilated filters with different gaps. By recombining these streams, the network gains a rich multi-scale view: it can distinguish between tightly packed small vehicles, larger ships, and extended structures like bridges, all while keeping the cost in parameters and computations extremely low. Together, LKCA and MSDP let the network pay attention to both local detail and broader context in the layers where each matters most.
Smarter Learning from Imperfect Data
Even with better features, training on real aerial data is tricky. Remote sensing datasets often contain noisy labels, partially hidden objects, or odd shapes that confuse conventional training losses. Many YOLO-style models use fixed rules that treat all training examples similarly, which can let a few bad examples generate misleading updates and slow or destabilize learning. LMW-YOLO replaces this with a scheme called Wise-IoU v3, which adjusts how strongly each example influences training based on how well it currently fits. Examples that are already very good or clearly terrible are down-weighted, while the "hard but useful" cases get emphasized. This dynamic focusing helps the model converge faster and improves how precisely it draws boxes around small, crowded objects.
Proving It Works in the Real World
The team tests LMW-YOLO on three demanding benchmarks: a high-resolution satellite dataset (NWPU VHR-10), a specialized collection of extremely tiny targets (RS-STOD), and a large drone image set with heavy crowding and occlusion (VisDrone2019). Across all three, the new model outperforms a range of recent detectors, including several larger and more complex systems, while using only about 2.6 million parameters and modest computation. It also runs in real time or near-real time on standard CPUs, indicating that it is practical for deployment on drones and small platforms, not just in powerful data centers.
What This Means Going Forward
For readers, the key message is that we no longer have to choose as starkly between accuracy and efficiency when it comes to spotting tiny objects from above. By carefully tailoring how different layers of a network handle detail and context, and by training it with a loss function that learns to ignore misleading examples, LMW-YOLO delivers sharper, more reliable detections while staying small enough for real-world aerial and satellite devices. This makes it a promising building block for applications ranging from traffic monitoring and harbor security to disaster response and environmental surveys, where every tiny object in a massive image can carry important information.
Citation: Qiu, Y., Lin, Z. Lightweight model LMW-YOLO for small object detection in remote sensing images. Sci Rep 16, 11644 (2026). https://doi.org/10.1038/s41598-026-45055-6
Keywords: remote sensing, small object detection, lightweight deep learning, aerial imagery, YOLO architecture