Clear Sky Science · ar
نموذج خفيف الوزن LMW-YOLO لاكتشاف الأجسام الصغيرة في صور الاستشعار عن بُعد
رؤية الأشياء الصغيرة من الفضاء
من حركة المرور في المدن إلى السفن في الموانئ، يظهر الكثير من ما يهم على الأرض كنِقَاط صغيرة في الصور الجوية والأقمار الصناعية. ومع ذلك، فإن تعليم الحواسيب على اكتشاف هذه الأجسام الصغيرة بشكل موثوق أمرٌ أصعب مما يبدو، خاصة على أجهزة خفيفة مثل الطائرات بدون طيار أو الأقمار الصناعية الصغيرة. يقدم هذا البحث LMW-YOLO، نظام رؤية مدمج وفعال مصمم خصيصًا لاكتشاف الأجسام الصغيرة جدًا في صور الاستشعار عن بُعد الكبيرة والمزدحمة دون الحاجة إلى قدر كبير من طاقة الحوسبة.
لماذا يصعب العثور على الأهداف الصغيرة
تُلتقط صور الاستشعار عن بُعد من ارتفاعات عالية، لذا تظهر السيارات والقوارب والأشخاص عادة بعرض بضع بيكسلات فقط. تقوم الكواشف التقليدية، مثل عائلة YOLO الشهيرة، بتقليص الصور طبقةً بعد طبقة لتسريع المعالجة والتقاط الأنماط عالية المستوى. لكن بالنسبة لأجسام بعرض 5–10 بيكسلات فقط، قد تمحو هذه العملية هذه الأجسام قبل أن «يرى»ها الشبكة أصلاً. اعتمدت المحاولات السابقة لمعالجة هذه المشكلة عادةً على شبكات أعمق، أو آليات اهتمام، أو نماذج على غرار المحولات (Transformers). تعمل هذه الأساليب على تحسين الدقة، لكنها تكون غالبًا ثقيلة جدًا بالنسبة للطائرات بدون طيار أو الأقمار أو أجهزة الحافة ذات الذاكرة والطاقة المحدودة. ثمة توتر بين إبقاء النماذج صغيرة والحفاظ على التفاصيل الكافية للتعرّف على الأهداف الصغيرة في خلفيات معقدة من مبانٍ وأشجار ومياه.
تكييف الشبكة لكل مستوى
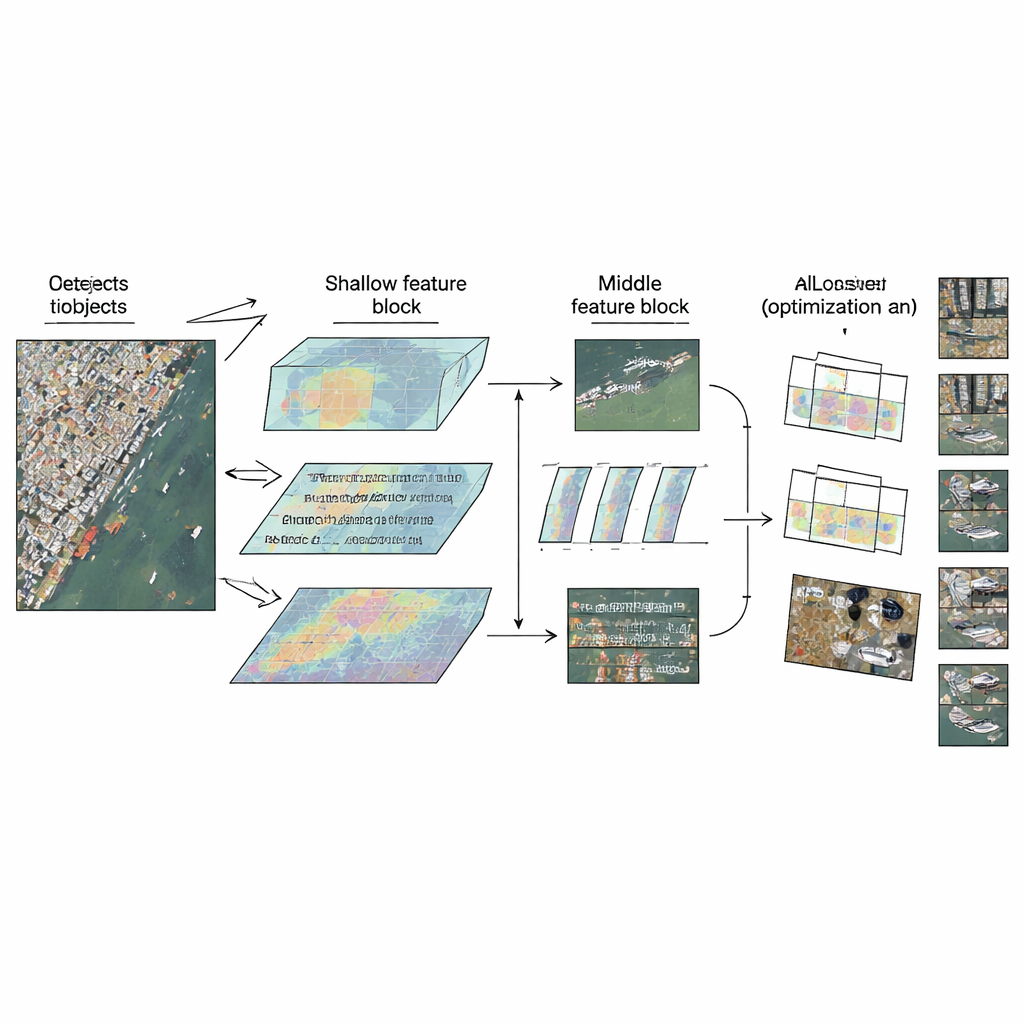
ينطلق LMW-YOLO من هيكلية YOLO خفيفة حديثة ثم يكسر عادة تصميمية شائعة: معاملة جميع الطبقات بنفس الطريقة. بدلاً من استخدام لبنة بنائية موحّدة في كل مكان، يقترح المؤلفون استراتيجية «فصل السياق والمقاس» Context-Scale Decoupled تمنح كل جزء من الشبكة دورًا متخصصًا. في المرحلة السطحية، حيث تظل الصور كبيرة نسبيًا، تكافح الشبكة لرؤية ما يكفي لفهم الأجسام الصغيرة في سياقها. هنا يضيف المؤلفون وحدة تجميع سياق ذات نواة كبيرة (Large-Kernel Context Aggregation - LKCA) التي تحاكي نوافذ مرشحات ضخمة عبر دمج عدة عمليات التواء أصغر وكفؤة. هذا يسمح للشبكة بالنظر عبر منطقة أوسع مع الحفاظ على التفاصيل الدقيقة المهمة لسيارات أو سفن صغيرة. في المرحلة الوسطى، يتغير التحدي: يجب على النموذج التعامل مع أجسام بأحجام متباينة جدًا دون فقدان الحدة المكانية.
النظر إلى عدة مقاييس في وقت واحد
لمواجهة هذا التنوع، يقدم المؤلفون وحدة الإدراك متعدد المقاييس والموسعة (Multi-Scale Dilated Perception - MSDP) في الخرائط الميزية الأعمق. تقسم هذه الوحدة المعلومات إلى مسارين. يمر أحد المسارين دون تغيير، محافظًا على التفاصيل الموضعية الحادة. يمر المسار الآخر عبر مجموعة من فروع الالتواء المتوازية التي «ترى» كل منها في مدى مختلف، من المحلي جدًا إلى النطاق الأوسع، بفضل مرشحات متوسعة ذات فجوات مختلفة. من خلال إعادة دمج هذه المسارات، تكسب الشبكة منظورًا متعدد المقاييس غنيًا: يمكنها التمييز بين مركبات صغيرة متكدسة بإحكام، وسفن أكبر، وهياكل ممتدة مثل الجسور، كل ذلك مع الحفاظ على تكلفة منخفضة جدًا من حيث المعاملات والحساب. معًا، تتيح وحدتا LKCA وMSDP للشبكة الانتباه إلى التفاصيل المحلية والسياق الأوسع في الطبقات التي يهمها كل منهما أكثر.
تعلم أذكى من بيانات غير مثالية
حتى مع ميزات محسنة، يبقى التدريب على بيانات جوية حقيقية أمرًا معقدًا. غالبًا ما تحتوي مجموعات بيانات الاستشعار عن بُعد على تسميات ضوضائية، أو أجسام مخفية جزئيًا، أو أشكال غريبة تربك دوال الخسارة التقليدية. تستخدم العديد من نماذج نمط YOLO قواعد ثابتة تعامل جميع أمثلة التدريب بشكل مماثل، ما قد يسمح لعدد قليل من الأمثلة السيئة بتوليد تحديثات مضللة وتبطئ أو تزعزع عملية التعلم. يستبدل LMW-YOLO ذلك بمخطط يسمى Wise-IoU v3، الذي يضبط مدى تأثير كل مثال على التدريب بناءً على مدى توافقه الحالي. تُخفف أوزان الأمثلة الجيدة جدًا أو السيئة بوضوح، بينما تحظى الحالات «الصعبة ولكن المفيدة» بمزيد من التركيز. يساعد هذا التمركز الديناميكي النموذج على التقارب أسرع ويحسن دقة رسم الصناديق حول الأجسام الصغيرة والمزدحمة.
إثبات الفعالية في العالم الحقيقي
اختبر الفريق LMW-YOLO على ثلاث مجموعات معيارية متطلبة: مجموعة بيانات عالية الدقة من الأقمار الصناعية (NWPU VHR-10)، ومجموعة متخصصة للأهداف الصغيرة للغاية (RS-STOD)، ومجموعة واسعة من صور الطائرات بدون طيار ذات الازدحام والتغطية الكثيفة (VisDrone2019). عبر الثلاث مجموعات، تفوّق النموذج الجديد على مجموعة من الكواشف الحديثة، بما في ذلك عدة أنظمة أكبر وأكثر تعقيدًا، بينما استخدم حوالي 2.6 مليون معلمة وحوسبة معتدلة فقط. كما يعمل في الزمن الحقيقي أو قريبًا منه على المعالجات المركزية القياسية، مما يشير إلى جدواه للنشر على الطائرات بدون طيار والمنصات الصغيرة، وليس فقط في مراكز بيانات قوية.
ماذا يعني هذا للمستقبل
بالنسبة للقارئ، الرسالة الأساسية هي أننا لم نعد مضطرين لاختيار حاد بين الدقة والكفاءة عند رصد الأجسام الصغيرة من الأعلى. من خلال تكييف كيفية تعامل طبقات مختلفة من الشبكة مع التفاصيل والسياق بعناية، ومن خلال تدريبها بدالة خسارة تتعلم تجاهل الأمثلة المضللة، يقدم LMW-YOLO اكتشافات أدق وأكثر موثوقية مع بقاء النموذج صغيرًا بما يكفي لأجهزة الاستشعار الجوية والأقمار الصناعية العملية. هذا يجعله حجر بناء واعدًا لتطبيقات تتراوح من مراقبة المرور وأمن الموانئ إلى الاستجابة للكوارث والمسوح البيئية، حيث يمكن أن تحمل كل جسم صغير في صورة ضخمة معلومات مهمة.
الاستشهاد: Qiu, Y., Lin, Z. Lightweight model LMW-YOLO for small object detection in remote sensing images. Sci Rep 16, 11644 (2026). https://doi.org/10.1038/s41598-026-45055-6
الكلمات المفتاحية: الاستشعار عن بعد, اكتشاف الأجسام الصغيرة, التعلم العميق خفيف الوزن, الصور الجوية, بنية YOLO