Clear Sky Science · pt
Modelo leve LMW-YOLO para detecção de pequenos objetos em imagens de sensoriamento remoto
Vendo as Coisas Pequenas do Espaço
De tráfego urbano a navios em um porto, grande parte do que importa na Terra aparece como minúsculos pontos em fotos aéreas e de satélite. Ainda assim, ensinar computadores a identificar esses objetos diminutos de forma confiável é surpreendentemente difícil, especialmente em dispositivos leves como drones ou pequenos satélites. Este artigo apresenta o LMW-YOLO, um sistema de visão compacto, porém poderoso, projetado especificamente para encontrar objetos muito pequenos em imagens extensas e complexas de sensoriamento remoto, sem exigir grande poder de processamento.
Por que Alvos Minúsculos São Difíceis de Encontrar
Imagens de sensoriamento remoto são feitas de muito alto, então carros, barcos e pessoas frequentemente aparecem com apenas alguns pixels de largura. Detectores de objetos padrão, como a popular família YOLO, reduzem as imagens camada a camada para acelerar o processamento e capturar padrões de alto nível. Mas para objetos com apenas 5–10 pixels, esse rebaixamento pode apagá-los antes mesmo que a rede os "veja". Tentativas anteriores para resolver esse problema tipicamente recorreram a redes mais profundas, mecanismos de atenção ou modelos no estilo Transformer. Essas abordagens podem melhorar a precisão, mas tendem a ser pesadas demais para drones, satélites ou dispositivos de borda com memória e energia limitadas. Há uma tensão entre manter os modelos pequenos e preservar detalhes suficientes para reconhecer alvos minúsculos em fundos complexos de prédios, árvores e água.
Adaptando a Rede a Cada Nível
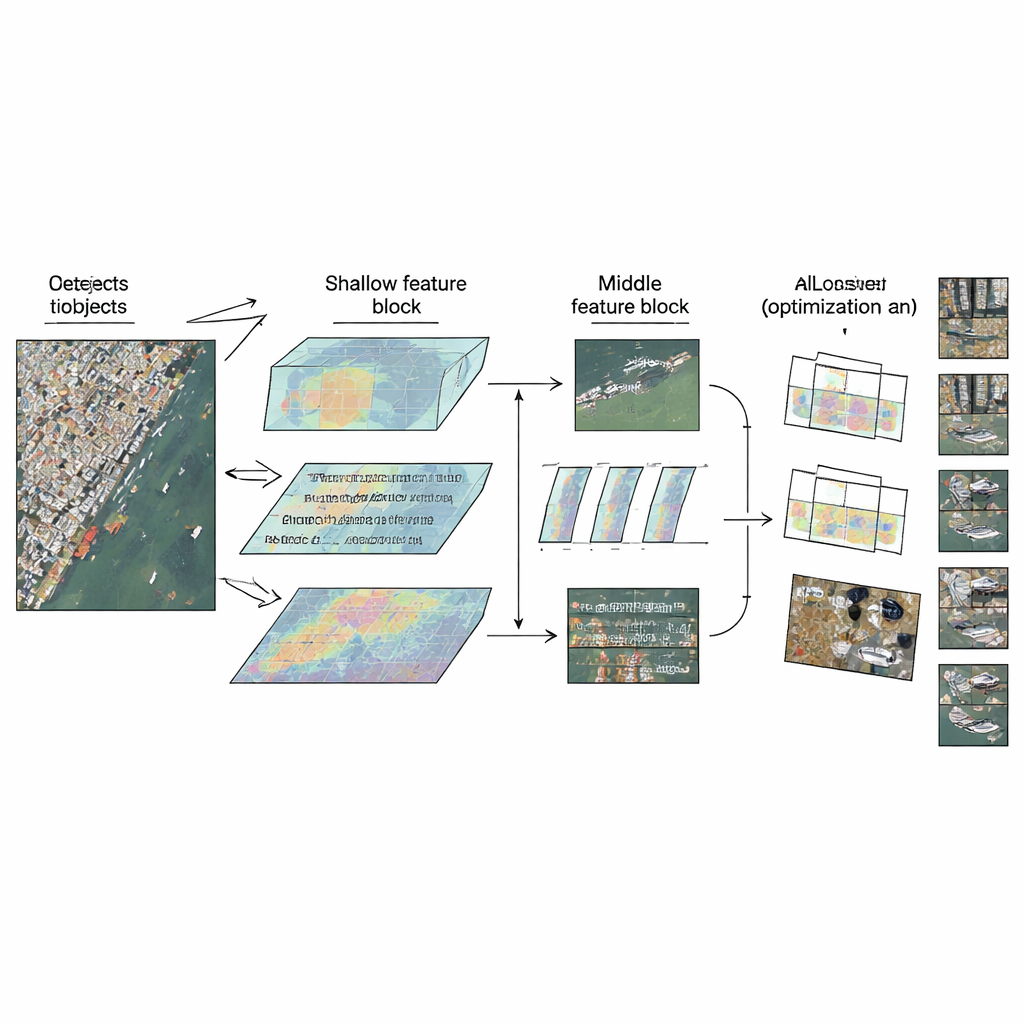
O LMW-YOLO parte de um backbone YOLO leve moderno e então rompe com um hábito comum de design: tratar todas as camadas da mesma forma. Em vez de usar um bloco uniforme em todo lugar, os autores propõem uma estratégia "Context-Scale Decoupled" que atribui a cada parte da rede um papel especializado. Na etapa rasa, onde as imagens ainda são relativamente grandes, o modelo tem dificuldade em ver com amplitude suficiente para interpretar objetos minúsculos no contexto. Aqui, os autores adicionam um módulo de Agregação de Contexto com Kernel Grande (LKCA) que emula janelas de filtro enormes combinando várias convoluções menores e eficientes. Isso permite que a rede olhe para uma área mais ampla preservando detalhes finos importantes para carros ou navios diminutos. Na etapa intermediária, o desafio muda: o modelo deve lidar com objetos de tamanhos muito diferentes sem perder nitidez espacial.
Olhando em Muitas Escalas ao Mesmo Tempo
Para lidar com essa variedade, os autores introduzem um módulo de Percepção Diluída Multiescala (MSDP) nas mapas de características mais profundas. Esse módulo divide a informação em dois caminhos. Um caminho passa sem alteração, preservando detalhes posicionais nítidos. O outro passa por um conjunto de ramos de convolução paralelos que "veem" em alcances diferentes, do muito local a regiões mais amplas, graças a filtros dilatados com espaços variados. Ao recombinar essas correntes, a rede obtém uma visão multiescala rica: ela pode distinguir entre veículos pequenos e apertados, navios maiores e estruturas alongadas como pontes, tudo mantendo o custo em parâmetros e computação extremamente baixo. Juntos, LKCA e MSDP permitem que a rede preste atenção tanto ao detalhe local quanto ao contexto mais amplo nas camadas onde cada um é mais importante.
Aprendizado Mais Inteligente a Partir de Dados Imperfeitos
Mesmo com features melhores, treinar com dados aéreos reais é complicado. Conjuntos de dados de sensoriamento remoto frequentemente contêm rótulos ruidosos, objetos parcialmente ocultos ou formas estranhas que confundem perdas de treinamento convencionais. Muitos modelos estilo YOLO usam regras fixas que tratam todos os exemplos de treinamento de forma semelhante, o que pode permitir que alguns exemplos ruins gerem atualizações enganosas e retardem ou desestabilizem o aprendizado. O LMW-YOLO substitui isso por um esquema chamado Wise-IoU v3, que ajusta a força com que cada exemplo influencia o treinamento com base em quão bem ele se ajusta no momento. Exemplos que já são muito bons ou claramente ruins têm peso reduzido, enquanto os casos "difíceis, mas úteis" são enfatizados. Esse foco dinâmico ajuda o modelo a convergir mais rápido e melhora a precisão ao traçar caixas ao redor de objetos pequenos e aglomerados.
Comprovando que Funciona no Mundo Real
A equipe testa o LMW-YOLO em três benchmarks exigentes: um conjunto de satélite de alta resolução (NWPU VHR-10), uma coleção especializada em alvos extremamente pequenos (RS-STOD) e um grande conjunto de imagens de drone com forte aglomeração e oclusão (VisDrone2019). Em todos os três, o novo modelo supera uma série de detectores recentes, incluindo vários sistemas maiores e mais complexos, usando apenas cerca de 2,6 milhões de parâmetros e computação moderada. Ele também roda em tempo real ou quase em tempo real em CPUs padrão, indicando que é prático para implantação em drones e plataformas pequenas, não apenas em centros de dados potentes.
O que Isso Significa Para o Futuro
Para os leitores, a mensagem chave é que não precisamos mais escolher de forma tão radical entre precisão e eficiência ao detectar objetos minúsculos a partir do alto. Ao ajustar cuidadosamente como diferentes camadas de uma rede lidam com detalhe e contexto, e treinando-a com uma função de perda que aprende a ignorar exemplos enganosos, o LMW-YOLO proporciona detecções mais nítidas e confiáveis mantendo-se pequeno o bastante para dispositivos aéreos e de satélite do mundo real. Isso o torna um bloco de construção promissor para aplicações que vão do monitoramento de tráfego e segurança de portos ao suporte a resposta a desastres e levantamentos ambientais, onde cada pequeno objeto em uma imagem massiva pode conter informação importante.
Citação: Qiu, Y., Lin, Z. Lightweight model LMW-YOLO for small object detection in remote sensing images. Sci Rep 16, 11644 (2026). https://doi.org/10.1038/s41598-026-45055-6
Palavras-chave: sensoriamento remoto, detecção de pequenos objetos, aprendizado profundo leve, imagens aéreas, arquitetura YOLO