Clear Sky Science · es
Modelo ligero LMW-YOLO para la detección de objetos pequeños en imágenes de teledetección
Ver lo pequeño desde el espacio
Desde el tráfico urbano hasta los barcos en un puerto, gran parte de lo importante en la Tierra aparece como diminutos puntos en fotos aéreas y satelitales. Sin embargo, enseñar a los ordenadores a detectar de forma fiable estos objetos diminutos resulta sorprendentemente difícil, sobre todo en dispositivos ligeros como drones o pequeños satélites. Este artículo presenta LMW-YOLO, un sistema visual compacto pero potente diseñado específicamente para encontrar objetos muy pequeños en imágenes de teledetección grandes y complejas sin necesitar una gran capacidad de cálculo.
Por qué es difícil encontrar objetivos diminutos
Las imágenes de teledetección se toman desde gran altitud, por lo que coches, embarcaciones y personas suelen aparecer con solo unos pocos píxeles de ancho. Los detectores de objetos estándar, como la popular familia YOLO, reducen la resolución de las imágenes capa a capa para acelerar el procesamiento y captar patrones de alto nivel. Pero para objetos de solo 5–10 píxeles, este muestreo descendente puede borrarlos antes de que la red los "vea". Intentos previos para solucionar este problema han recurrido a redes más profundas, mecanismos de atención o modelos tipo Transformer. Estas aproximaciones pueden mejorar la precisión, pero suelen ser demasiado pesadas para drones, satélites o dispositivos edge con memoria y energía limitadas. Existe una tensión entre mantener los modelos pequeños y conservar suficiente detalle para reconocer objetivos diminutos en fondos complejos de edificios, árboles y agua.
Adaptar la red a cada nivel
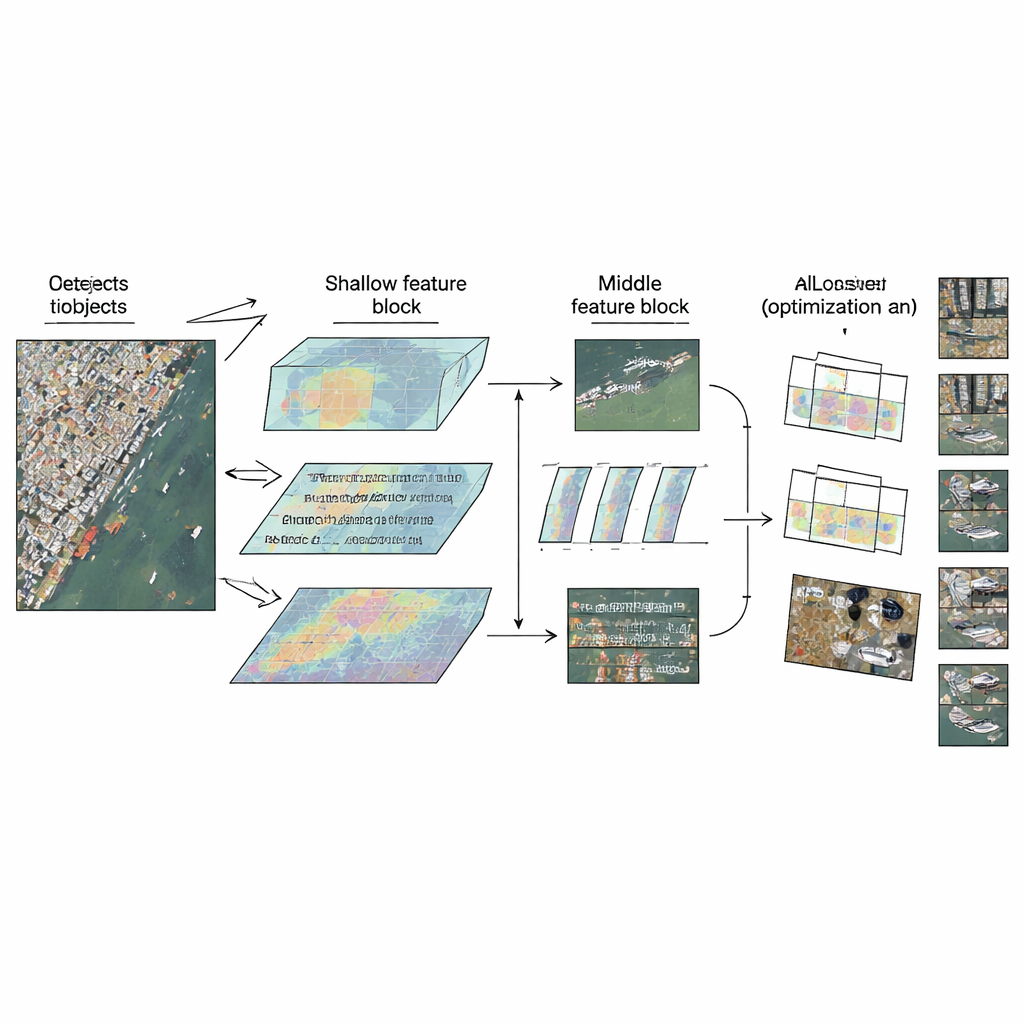
LMW-YOLO parte de un backbone YOLO moderno y ligero y rompe con una práctica común: tratar todas las capas por igual. En lugar de usar un mismo bloque en todas partes, los autores proponen una estrategia "Context-Scale Decoupled" que asigna a cada parte de la red un papel especializado. En la etapa superficial, donde las imágenes aún son relativamente grandes, el modelo tiene dificultad para ver lo bastante lejos como para interpretar objetos pequeños en su contexto. Aquí, los autores añaden un módulo de Agregación de Contexto de Gran Núcleo (LKCA) que simula ventanas de filtro enormes combinando varias convoluciones más pequeñas y eficientes. Esto permite a la red observar un área más amplia conservando los detalles finos importantes para detectar coches o barcos minúsculos. En la etapa intermedia, el reto cambia: el modelo debe manejar objetos de tamaños muy distintos sin perder nitidez espacial.
Mirar muchas escalas a la vez
Para hacer frente a esta variedad, los autores introducen un módulo de Percepción Densificada Multi‑escala (MSDP) en los mapas de características más profundos. Este módulo divide la información en dos vías. Una vía pasa sin cambios, preservando detalles posicionales nítidos. La otra atraviesa un conjunto de ramas convolucionales en paralelo que "ven" a distintos alcances, desde regiones muy locales hasta áreas más amplias, gracias a filtros dilatados con distintos huecos. Al recombinar estas corrientes, la red obtiene una visión multi‑escala rica: puede distinguir entre vehículos pequeños muy juntos, barcos de mayor tamaño y estructuras extensas como puentes, todo ello manteniendo el coste en parámetros y cómputo extremadamente bajo. Juntos, LKCA y MSDP permiten que la red atienda tanto al detalle local como al contexto más amplio en las capas donde cada aspecto importa.
Aprender mejor con datos imperfectos
Incluso con mejores características, entrenar con datos reales aéreos es complejo. Los conjuntos de teledetección a menudo contienen etiquetas ruidosas, objetos parcialmente ocultos o formas extrañas que confunden las pérdidas de entrenamiento convencionales. Muchos modelos estilo YOLO usan reglas fijas que tratan todos los ejemplos de entrenamiento por igual, lo que permite que unos pocos ejemplos malos generen actualizaciones engañosas y ralenticen o desestabilicen el aprendizaje. LMW‑YOLO sustituye esto por un esquema llamado Wise‑IoU v3, que ajusta la influencia de cada ejemplo en el entrenamiento según lo bien que encaje actualmente. Los ejemplos ya muy buenos o claramente malos reciben menos peso, mientras que los casos "difíciles pero útiles" se enfatizan. Este enfoque dinámico ayuda a que el modelo converja más rápido y mejora la precisión con la que traza cajas alrededor de objetos pequeños y concurridos.
Demostrando que funciona en el mundo real
El equipo evalúa LMW‑YOLO en tres bancos de pruebas exigentes: un conjunto de satélite de alta resolución (NWPU VHR‑10), una colección especializada en objetivos extremadamente pequeños (RS‑STOD) y un gran conjunto de imágenes de drones con fuerte aglomeración y oclusión (VisDrone2019). En los tres casos, el nuevo modelo supera a una gama de detectores recientes, incluidos varios sistemas más grandes y complejos, usando solo alrededor de 2,6 millones de parámetros y un coste computacional moderado. Además, se ejecuta en tiempo real o casi en tiempo real en CPU estándar, lo que indica que es práctico para desplegar en drones y plataformas pequeñas, no solo en centros de datos potentes.
Qué supone esto de cara al futuro
Para el lector, el mensaje clave es que ya no hace falta elegir de forma tan rígida entre precisión y eficiencia al detectar objetos diminutos desde arriba. Al adaptar cuidadosamente cómo distintas capas de una red manejan el detalle y el contexto, y al entrenarla con una función de pérdida que aprende a ignorar ejemplos engañosos, LMW‑YOLO ofrece detecciones más nítidas y confiables manteniéndose lo bastante pequeño para dispositivos aéreos y satelitales reales. Esto lo convierte en un bloque prometedor para aplicaciones que van desde la monitorización del tráfico y la seguridad portuaria hasta la respuesta a desastres y los estudios ambientales, donde cada pequeño objeto en una imagen masiva puede aportar información importante.
Cita: Qiu, Y., Lin, Z. Lightweight model LMW-YOLO for small object detection in remote sensing images. Sci Rep 16, 11644 (2026). https://doi.org/10.1038/s41598-026-45055-6
Palabras clave: teledetección, detección de objetos pequeños, aprendizaje profundo ligero, imágenes aéreas, arquitectura YOLO