Clear Sky Science · sv
GoLoCo-Net: global-local guided contextual attention network för segmentering av medicinska bilder
Se in i kroppen tydligare
Läkare förlitar sig i allt högre grad på MRI- och CT-skanningar för att förstå hur våra organ rör sig och förändras över tid, från ett bankande hjärta till tungan i rörelse vid tal. Men för att omvandla dessa gråskalebilder till tydliga, färgkodade kartor över anatomin måste datorer exakt avgränsa varje struktur — en uppgift som kallas segmentering. Denna artikel presenterar GoLoCo-Net, en ny metod inom artificiell intelligens som gör dessa avgränsningar skarpare och mer tillförlitliga över olika typer av medicinska skanningar, vilket potentiellt kan förbättra diagnostik, planering av behandling och forskning kring hur kroppen fungerar.
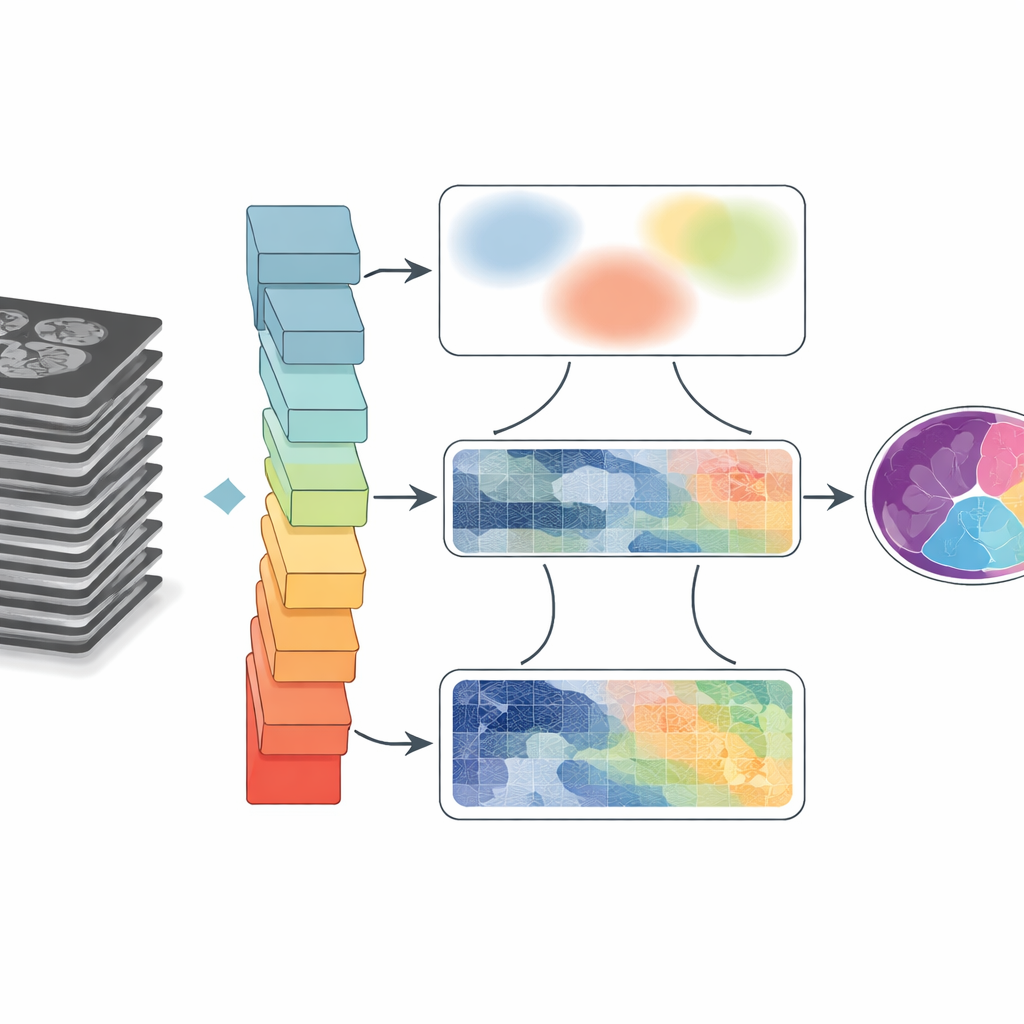
Varför det är så svårt att rita gränser i skanningar
Medicinska bilder är röriga. Organ ligger intill eller överlappar varandra, kanter kan se suddiga ut och rörelse eller hårdvarubegränsningar skapar oskärpa och artefakter. Traditionella datorprogram grupperar pixlar utifrån enkla regler, vilket ofta misslyckas när strukturer är små eller har svag kontrast. Deep learning har kraftigt förbättrat prestandan genom att låta neurala nätverk lära sig mönster direkt från stora datamängder. Vanliga konstruktioner koncentrerar sig dock antingen på små pixelnära områden och missar långdistanskopplingar, eller zoomar ut för att se helheten men förlorar då finare detaljer vid gränserna. Denna kompromiss blir avgörande när läkare behöver exakta former och storlekar, till exempel för att mäta hjärtrum eller följa tungans rörelser efter kirurgi.
Blendera helheten och finare detaljer
GoLoCo-Net är utformat för att fånga både bildens breda kontext och de små detaljerna vid dess kanter. I centrum finns en modern "vision transformer"-encoder som ser hela skanningen på en gång och lär sig hur avlägsna regioner förhåller sig till varandra. Ovanpå denna bygger författarna två separata dekodergrenar. Den ena grenen fokuserar på högre nivåer av förståelse: vilka strukturer som finns och hur de är ordnade. Den andra bevarar lågnivåinformation såsom textur och skarpa gränser. Istället för att enkelt sy ihop dessa vyer använder GoLoCo-Net noggrant utformade attention-moduler så att global information kan vägleda lokala detaljer och att lokala signaler i sin tur kan skärpa den globala bilden.
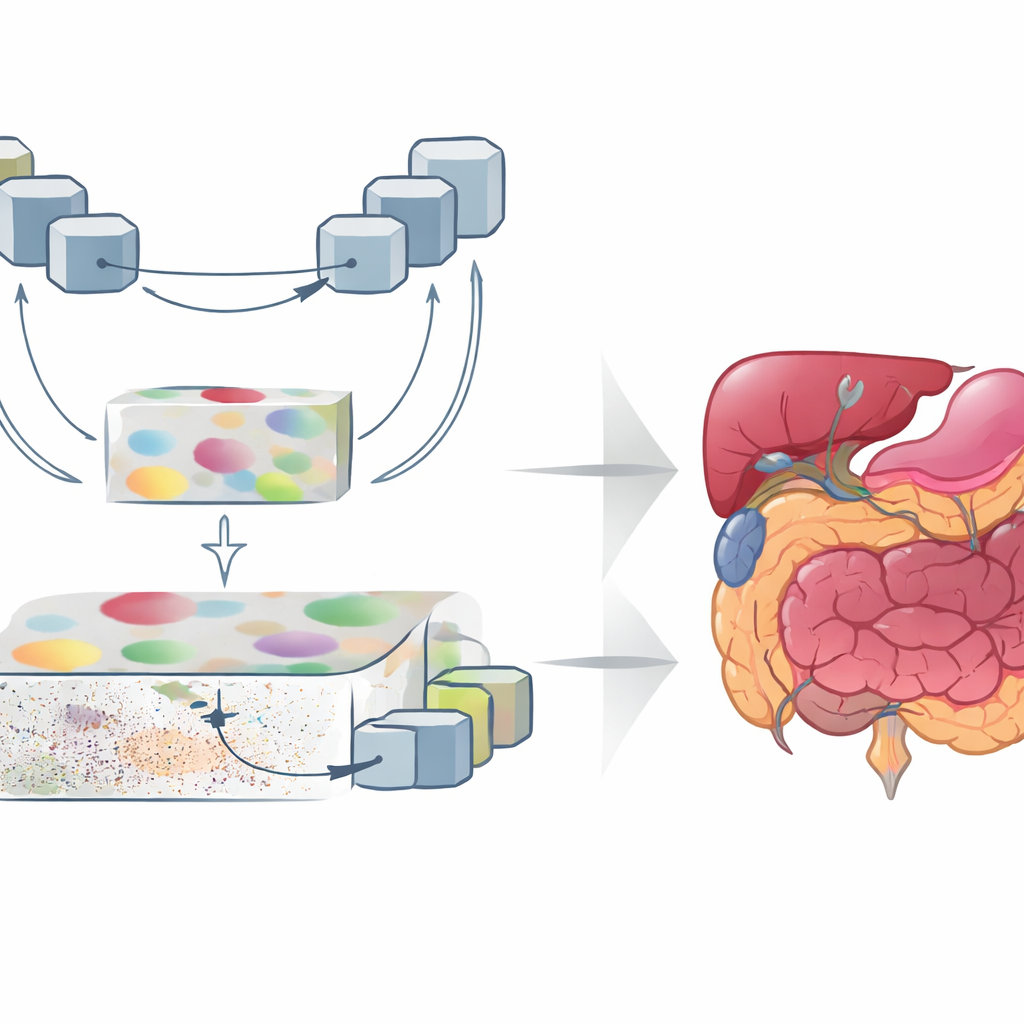
Hur de nya modulerna formar bilden
Den första nyckelmodulen, kallad Contextual Attention Feature Enhancement, berikar den högre nivåns representation. Den leder de abstrakta egenskaperna genom ett U-format block som upprepade gånger krymper och förstorar bildrepresentationen, vilket gör att nätverket kan betrakta strukturer i flera storlekar. Attention-mekanismer markerar sedan de regioner som är viktigast och dämpar transformerns tendens att sprida fokus för brett, vilket kan göra organens gränser suddiga. Den andra modulen, Global-Guide-Local Feature, börjar från motsatt håll: den tar detaljinformation om kanter och textur från grunda lager och använder en global signal från djupare lager för att filtrera bort brus och bakgrund. Ytterligare attention-block framhäver viktiga kanaler och spatiala regioner, så att små organ och tunna strukturer bevaras utan att överröstas av störningar.
Bevisa att det fungerar över organ och skannrar
För att testa GoLoCo-Net utvärderade forskarna metoden på tre mycket olika dataset. Det ena fångar talorganen i rörelse under tal-MRI, där tungan, mjuka gommen och omgivande vävnader rör sig snabbt och är känsliga för oskärpa och artefakter. Det andra innehåller kardiella MRI-skanningar som används för att mäta hjärtats kammare och muskelmassa. Det tredje är ett CT-dataset över flera bukorgan, inklusive levern, njurarna och bukspottkörteln. På alla tre presterade GoLoCo-Net bättre än flera ledande konvolutions- och transformerbaserade modeller, med högre överlappningspoäng mot expertritade konturer och bättre bevarande av anatomiska former. Det förblev robust även när extra brus tillsattes, vilket tyder på att det kan hantera ofullkomliga, verkliga data.
Vad detta betyder för patienter och kliniker
I praktiska termer erbjuder GoLoCo-Net ett mer tillförlitligt sätt att omvandla råa skanningar till precisa anatomiska kartor. För radiologer och kirurger kan det innebära renare, mer konsekventa mätningar av organ och tumörer. För talforskare och kliniker kan det ge tydligare bildruta-för-bildruta-visningar av hur tungan och mjuka gommen rör sig, utan tidsödande manuell avritning. Eftersom nyckelmodulerna är utformade för att kunna kopplas in i befintliga system kan tillvägagångssättet komma att användas i stor skala allteftersom bildbehandlings-AI utvecklas. Huvudpoängen är enkel: genom att lära datorer att balansera helheten med de allra finaste detaljerna förflyttar detta arbete oss närmare snabbare, mer exakta och mer robusta tolkningar av medicinska bilder.
Citering: He, Y., Miquel, M.E. & Zhang, Q. GoLoCo-Net: global-local guided contextual attention network for medical images segmentation. Sci Rep 16, 12300 (2026). https://doi.org/10.1038/s41598-026-42415-0
Nyckelord: segmentering av medicinska bilder, MRI, CT, deep learning, vision transformer